! python --versionPython 3.10.11This is a POC that shows how Reinforcement Learning could be used to build a strategic Next Best Action (NBA) model. This kind of model is handy to analyze customer jounrneys so that marketing effort can be optimized. The system-under-steer (SUS) is constructed making use of Gymnasium. The agent is implemented with the Ray RLlib library. Data is generated internally, so there are no external dependencies.
Next Best Action (NBA) is a decision-making framework used in various fields, including customer relationship management, marketing, healthcare, and recommendation systems. It involves determining the optimal action to take at a given moment to maximize desired outcomes or achieve specific objectives.
In a rapidly changing environment with numerous possibilities, organizations need to make intelligent decisions about their interactions with customers, patients, or users. NBA helps address this challenge by leveraging data-driven approaches and prescriptive analytics to recommend the most suitable action for a particular context or situation.
At its core, NBA combines the power of advanced algorithms, machine learning, and optimization techniques to identify the next best course of action from a set of available options. These options could include personalized offers, targeted marketing campaigns, treatment plans, product recommendations, or any other action that aims to influence an individual’s behavior or outcome positively.
The NBA framework considers multiple factors when determining the best action. These factors may include historical data, customer preferences, behavioral patterns, business rules, real-time information, and predefined objectives. By analyzing and interpreting these inputs, the NBA system generates actionable insights that guide decision-makers towards the most effective action to take.
The benefits of implementing an NBA approach are manifold. It enables organizations to enhance customer or user experiences by providing personalized and relevant interactions. By delivering tailored recommendations or interventions, businesses can optimize their resources, increase customer satisfaction, and foster long-term loyalty.
Moreover, NBA contributes to data-driven decision-making, enabling organizations to prioritize actions based on their potential impact and align them with overarching goals. It empowers businesses to make informed choices, optimize processes, and drive desired outcomes by leveraging the power of data and advanced analytics.
However, implementing an NBA system involves challenges such as data quality, model accuracy, interpretability, scalability, and privacy considerations. Organizations need to address these challenges by ensuring the availability of high-quality data, robust models, appropriate feature engineering, and ongoing evaluation and refinement of the NBA system.
Next Best Action (NBA) is a decision-making framework that leverages data-driven approaches, machine learning, and optimization techniques to recommend the most appropriate action in a given context. By incorporating NBA into their operations, organizations can enhance customer experiences, optimize resource allocation, and drive desired outcomes by leveraging the power of data and advanced analytics.
Here are some information items from the areas of Marketing communications and Customer Experience Management, set in the context of Reinforcement Learning:
! python --versionPython 3.10.11! pip install "ray[rllib]" torch matplotlibLooking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: ray[rllib] in /usr/local/lib/python3.10/dist-packages (2.4.0)
Requirement already satisfied: torch in /usr/local/lib/python3.10/dist-packages (2.0.1+cu118)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (3.7.1)
Requirement already satisfied: attrs in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (23.1.0)
Requirement already satisfied: click>=7.0 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (8.1.3)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (3.12.0)
Requirement already satisfied: jsonschema in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (4.3.3)
Requirement already satisfied: msgpack<2.0.0,>=1.0.0 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.0.5)
Requirement already satisfied: protobuf!=3.19.5,>=3.15.3 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (3.20.3)
Requirement already satisfied: pyyaml in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (6.0)
Requirement already satisfied: aiosignal in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.3.1)
Requirement already satisfied: frozenlist in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.3.3)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (2.27.1)
Requirement already satisfied: virtualenv<20.21.1,>=20.0.24 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (20.21.0)
Requirement already satisfied: packaging in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (23.1)
Requirement already satisfied: grpcio<=1.51.3,>=1.42.0 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.51.3)
Requirement already satisfied: numpy>=1.19.3 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.22.4)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.5.3)
Requirement already satisfied: tabulate in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (0.8.10)
Requirement already satisfied: tensorboardX>=1.9 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (2.6)
Requirement already satisfied: dm-tree in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (0.1.8)
Requirement already satisfied: gymnasium==0.26.3 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (0.26.3)
Requirement already satisfied: lz4 in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (4.3.2)
Requirement already satisfied: scikit-image in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (0.19.3)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (1.10.1)
Requirement already satisfied: typer in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (0.7.0)
Requirement already satisfied: rich in /usr/local/lib/python3.10/dist-packages (from ray[rllib]) (13.3.4)
Requirement already satisfied: cloudpickle>=1.2.0 in /usr/local/lib/python3.10/dist-packages (from gymnasium==0.26.3->ray[rllib]) (2.2.1)
Requirement already satisfied: gymnasium-notices>=0.0.1 in /usr/local/lib/python3.10/dist-packages (from gymnasium==0.26.3->ray[rllib]) (0.0.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch) (4.5.0)
Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch) (1.11.1)
Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch) (3.1)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch) (3.1.2)
Requirement already satisfied: triton==2.0.0 in /usr/local/lib/python3.10/dist-packages (from torch) (2.0.0)
Requirement already satisfied: cmake in /usr/local/lib/python3.10/dist-packages (from triton==2.0.0->torch) (3.25.2)
Requirement already satisfied: lit in /usr/local/lib/python3.10/dist-packages (from triton==2.0.0->torch) (16.0.5)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (1.0.7)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (4.39.3)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (1.4.4)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (8.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (3.0.9)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Requirement already satisfied: distlib<1,>=0.3.6 in /usr/local/lib/python3.10/dist-packages (from virtualenv<20.21.1,>=20.0.24->ray[rllib]) (0.3.6)
Requirement already satisfied: platformdirs<4,>=2.4 in /usr/local/lib/python3.10/dist-packages (from virtualenv<20.21.1,>=20.0.24->ray[rllib]) (3.3.0)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch) (2.1.2)
Requirement already satisfied: pyrsistent!=0.17.0,!=0.17.1,!=0.17.2,>=0.14.0 in /usr/local/lib/python3.10/dist-packages (from jsonschema->ray[rllib]) (0.19.3)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas->ray[rllib]) (2022.7.1)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->ray[rllib]) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->ray[rllib]) (2022.12.7)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->ray[rllib]) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->ray[rllib]) (3.4)
Requirement already satisfied: markdown-it-py<3.0.0,>=2.2.0 in /usr/local/lib/python3.10/dist-packages (from rich->ray[rllib]) (2.2.0)
Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/dist-packages (from rich->ray[rllib]) (2.14.0)
Requirement already satisfied: imageio>=2.4.1 in /usr/local/lib/python3.10/dist-packages (from scikit-image->ray[rllib]) (2.25.1)
Requirement already satisfied: tifffile>=2019.7.26 in /usr/local/lib/python3.10/dist-packages (from scikit-image->ray[rllib]) (2023.4.12)
Requirement already satisfied: PyWavelets>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-image->ray[rllib]) (1.4.1)
Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch) (1.3.0)
Requirement already satisfied: mdurl~=0.1 in /usr/local/lib/python3.10/dist-packages (from markdown-it-py<3.0.0,>=2.2.0->rich->ray[rllib]) (0.1.2)from ray.rllib.algorithms.ppo import PPO
from IPython import display
import time
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from itertools import accumulate
from ray.tune.logger import pretty_print
from pprint import pprint
import itertools
from collections import namedtuple, defaultdict
import pandas as pd/usr/local/lib/python3.10/dist-packages/tensorflow_probability/python/__init__.py:57: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if (distutils.version.LooseVersion(tf.__version__) <
/usr/local/lib/python3.10/dist-packages/google/rpc/__init__.py:20: DeprecationWarning: Deprecated call to `pkg_resources.declare_namespace('google.rpc')`.
Implementing implicit namespace packages (as specified in PEP 420) is preferred to `pkg_resources.declare_namespace`. See https://setuptools.pypa.io/en/latest/references/keywords.html#keyword-namespace-packages
pkg_resources.declare_namespace(__name__)
/usr/local/lib/python3.10/dist-packages/pkg_resources/__init__.py:2349: DeprecationWarning: Deprecated call to `pkg_resources.declare_namespace('google')`.
Implementing implicit namespace packages (as specified in PEP 420) is preferred to `pkg_resources.declare_namespace`. See https://setuptools.pypa.io/en/latest/references/keywords.html#keyword-namespace-packages
declare_namespace(parent)! pip install gymnasium/usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:283: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: gymnasium in /usr/local/lib/python3.10/dist-packages (0.26.3)
Requirement already satisfied: numpy>=1.18.0 in /usr/local/lib/python3.10/dist-packages (from gymnasium) (1.22.4)
Requirement already satisfied: cloudpickle>=1.2.0 in /usr/local/lib/python3.10/dist-packages (from gymnasium) (2.2.1)
Requirement already satisfied: gymnasium-notices>=0.0.1 in /usr/local/lib/python3.10/dist-packages (from gymnasium) (0.0.1)import sys
import gymnasium
sys.modules["gym"] = gymnasium
from gymnasium import Env
from gymnasium.spaces import Dict, Discrete, Box, MultiDiscrete, Tuple
from gymnasium.wrappers import TimeLimit
gymnasium.__version__'0.26.3'The parameters of the System-Under-Steer (SUS) are:
SNames = [
'C__sens_t', 'C__nVisits_t', 'C__lastNOffers_t', 'C__nPurch_t',
'C__nPurchSinceLastOffer_t', 'W__behav_t'
]
xNames = ['x_t']
# eNames = #not used
piNames = ['X__Random', 'X__PPO']
# T = 4000All our data is simulated for this POC. Once we have created a model for the environment, we will use it to prepare some data. First, we setup some additional parameters.
def setup_behavior_probs_dict_from_init_data():
probs_dict = defaultdict(lambda: [0.90, 0.08, 0.02]) #default
probs_dict['1'] = [0.90, 0.08, 0.02]
probs_dict['2'] = [0.90, 0.08, 0.02]
probs_dict['3'] = [0.90, 0.08, 0.02]
probs_dict['11'] = [0.90, 0.08, 0.02]
probs_dict['12'] = [0.90, 0.08, 0.02]
probs_dict['13'] = [0.70, 0.08, 0.22] ##
probs_dict['21'] = [0.90, 0.08, 0.02]
probs_dict['22'] = [0.90, 0.08, 0.02]
probs_dict['23'] = [0.90, 0.08, 0.02]
probs_dict['31'] = [0.90, 0.08, 0.02]
probs_dict['32'] = [0.90, 0.08, 0.02]
probs_dict['33'] = [0.90, 0.08, 0.02]
probs_dict['111'] = [0.90, 0.08, 0.02]
probs_dict['112'] = [0.90, 0.08, 0.02]
probs_dict['113'] = [0.70, 0.08, 0.22] ##
probs_dict['121'] = [0.90, 0.08, 0.02]
probs_dict['122'] = [0.90, 0.08, 0.02]
probs_dict['123'] = [0.70, 0.08, 0.22] ##
probs_dict['131'] = [0.70, 0.08, 0.22] ##
probs_dict['132'] = [0.70, 0.08, 0.22] ##
probs_dict['133'] = [0.50, 0.08, 0.42] ###
probs_dict['211'] = [0.90, 0.08, 0.02]
probs_dict['212'] = [0.90, 0.08, 0.02]
probs_dict['213'] = [0.70, 0.08, 0.22] ##
probs_dict['221'] = [0.90, 0.08, 0.02]
probs_dict['222'] = [0.90, 0.08, 0.02]
probs_dict['223'] = [0.90, 0.08, 0.02]
probs_dict['231'] = [0.90, 0.08, 0.02]
probs_dict['232'] = [0.90, 0.08, 0.02]
probs_dict['233'] = [0.90, 0.08, 0.02]
probs_dict['311'] = [0.90, 0.08, 0.02]
probs_dict['312'] = [0.90, 0.08, 0.02]
probs_dict['313'] = [0.70, 0.08, 0.22] ##
probs_dict['321'] = [0.90, 0.08, 0.02]
probs_dict['322'] = [0.90, 0.08, 0.02]
probs_dict['323'] = [0.37, 0.10, 0.53] ####
probs_dict['331'] = [0.90, 0.08, 0.02]
probs_dict['332'] = [0.90, 0.08, 0.02]
probs_dict['333'] = [0.90, 0.08, 0.02]
return probs_dict# HORIZON = 700
# HORIZON = 800
# HORIZON = 1000
# HORIZON = 1200
# HORIZON = 1400
# HORIZON = 2000
HORIZON = 4000def multinomial_int(probs):
return np.where(np.random.multinomial(1, probs) == 1)[0][0]def get_behavior_probs(offers, beh_probs_dict): #offers so far
offers_str = ''.join([str(i) for i in offers])
return beh_probs_dict[offers_str]
# get_behavior_probs([2]) Marketing is most effective if each customer is treated as a system-under-steer (SUM). By taking into account variables like a customer’s sensitivity to advertisements, the number of visits the customer made to the company’s website, the most recent offers made to the customer, the total number of purchases the customer made, the number of purchases the customer made since the last offer, and the customer’s behavior probabilities an AI agent can learn an optimal sequence of offers to place in front of the customer. By doing so the agent attempts to steer the customer along his/her journey subject to a specified objective. Examples of objectives are to maximize the customer’s happiness, maximize the company’s profit associated with the customer, etc. A combination of objectives could also be specified.
In this section we want to answer three questions: - What metrics are we going to track? - What decisions do we intend to make? - What are the sources of uncertainty?
The following metrics will be tracked: - the number of visits to the company’s site - the total number of purchases made by a customer - the number of purchases since the last offer - the cumulative reward for the company, i.e. the profit
A single type of decision needs to be made at the start of each iteration - the type of offer made to a customer. It can be one of the following: - None (no offer made) - An advertisement is presented - A small discount is offered with the adverisement - A large discount is offered with the adverisement
There are several sources of uncertainty: - the customer behavior - could be - None, i.e. no response to an offer - Visit, i.e. the customer visits the company’s site but does not purchase - Purchase, i.e. the customer visits and make a purchase - the purchase probability of a customer
A Python class is used to implement the model for the SUS (System Under Steer). It inherits from the Env class in the gymnasium package:
class Customer(Env):
def __init__(self, env_config=None):
...
...The state variables represent what we need to know.
The state is:
The state variables are represented by the following variables in the CustomerModel class:
self.SNames = SNames
self.State = namedtuple('State', SNames) # 'class'
self.S_t = self.build_state(self.S_0) # 'instance'where
SNames = ['C__sens_t', 'C__nVisits_t', 'C__lastNOffers_t', 'C__nPurch_t',
'C__nPurchSinceLastOffer_t', 'W__behav_t']The decision variables represent what we control.
The decision variables are represented by the following variables in the CustomerModel class:
self.Decision = namedtuple('Decision', xNames) # 'class'where
xNames = ['x_t']The exogenous information variables represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(x_t\).
\[ W_{t+1} = \hat{W}^{behav}_{t+1} \]
represents the behavior of the customer. - the behavior is informed by the purchase probability of a customer - could be one of - No action, i.e. no response to an offer (0) - Visit, i.e. the customer visits the company’s site but does not purchase (1) - Purchase, i.e. the customer visits and make a purchase (2)
The latest exogenous information can be accessed by calling the following method from class CustomerModel():
def W_fn(self):
behav_probs = get_behavior_probs(self.S_t.C__lastNOffers_t, self.behavior_probs); #print(f'beh_probs: {beh_probs}')
W_tt1 = multinomial_int(behav_probs)
return W_tt1, behav_probsThe transition function describe how the state variables evolve over time.
We have the following equations: \[C^{nVisits}_{t+1}= \begin{cases} C^{nVisits}_{t} + 1 & \text{if } W_{t+1}=1 \\ C^{nVisits}_{t} & \text{otherwise} \end{cases} \]
\[C^{nPurch}_{t+1}= \begin{cases} C^{nPurch}_{t} + 1 & \text{if } W_{t+1}=2 \\ C^{nPurch}_{t} & \text{otherwise} \end{cases} \]
\[C^{nPurchSinceLastOffer}_{t+1}= \begin{cases} C^{nPurchSinceLastOffer}_{t} + 1 & \text{if } W_{t+1}=2 \\ 0 & \text{if } x_{t}>0 \\ C^{nPurchSinceLastOffer}_{t} & \text{otherwise} \end{cases} \]
Collectively, they represent the general transition function:
\[ S_{t+1} = S^M(S_t,X^{\pi}(S_t)) \]
The transition function is implemented by the following method in class CustomerModel():
# transition function
def S__M_fn(self, x_t, W_tt1):
# C__sens
C__sens_tt1 = self.S_t.C__sens_t
# C__nVisits
if W_tt1==1:
C__nVisits_tt1 = self.S_t.C__nVisits_t + 1
else:
C__nVisits_tt1 = self.S_t.C__nVisits_t
# C__lastNOffers
if x_t.x_t > 0: #don't keep 0 offers
C__lastNOffers_tt1 = np.append(self.S_t.C__lastNOffers_t, x_t.x_t)
if C__lastNOffers_tt1.size > 3:
C__lastNOffers_tt1 = np.delete(C__lastNOffers_tt1, 0)
else:
C__lastNOffers_tt1 = self.S_t.C__lastNOffers_t
# C__nPurch
if W_tt1 == 2:
C__nPurch_tt1 = self.S_t.C__nPurch_t + 1
else:
C__nPurch_tt1 = self.S_t.C__nPurch_t
# C__nPurchSinceLastOffer
C__nPurchSinceLastOffer_tt1 = self.S_t.C__nPurchSinceLastOffer_t
if W_tt1 == 2:
C__nPurchSinceLastOffer_tt1 = self.S_t.C__nPurchSinceLastOffer_t + 1
if x_t.x_t > 0:
C__nPurchSinceLastOffer_tt1 = 0 #reset purchases
S_tt1 = self.build_state({
'C__sens_t': C__sens_tt1,
'C__nVisits_t': C__nVisits_tt1,
'C__lastNOffers_t': C__lastNOffers_tt1,
'C__nPurch_t': C__nPurch_tt1,
'C__nPurchSinceLastOffer_t': C__nPurchSinceLastOffer_tt1,
'W__behav_t': W_tt1
})
return S_tt1The objective function captures the performance metrics of the solution to the problem.
\[ \begin{align} C(S_t,x_t,W_{t+1}) = C^{nPurchSinceLastOffer}_t \end{align} \]
This leads to the objective function:
\[ \max_{\pi}\mathbb{E}\{\sum_{t=0}^{T}C(S_t,x_t,W_{t+1}) \} \]
The contribution (reward) function is implemented by the following method in class CustomerModel:
# reward function
def C_fn(self):
C = self.S_t.C__nPurchSinceLastOffer_t
return CHere is the complete implementation of the CustomerModel class:
class CustomerModel(Env):
def __init__(self, env_config=None):
if env_config is None:
env_config = dict()
self.behavior_probs = env_config.get(
"behavior_probs", setup_behavior_probs_dict_from_init_data())
self.S_0_info = {
'C__sens_t': 0,
'C__nVisits_t': 0,
'C__lastNOffers_t': np.array([0, 0, 0]),
'C__nPurch_t': 0,
'C__nPurchSinceLastOffer_t': 0,
'W__behav_t': 0,
}
self.SNames = SNames
self.xNames = xNames
# self.eNames = eNames #not used
self.State = namedtuple('State', SNames) # 'class'
self.S_t = self.build_state(self.S_0_info) # 'instance'
self.Decision = namedtuple('Decision', xNames) # 'class'
self.cumC = 0.0 #. cumulative reward
self.t = env_config.get("t", 0)
self.T = env_config.get("T", 10)
self.observation_space = Dict({
'C__sens_t': Discrete(2),
'C__nVisits_t': Discrete(HORIZON),
'C__lastNOffers_t': MultiDiscrete([4, 4, 4]),
'C__nPurch_t': Discrete(HORIZON),
'C__nPurchSinceLastOffer_t': Discrete(HORIZON),
'W__behav_t': Discrete(3),
})
self.action_space = Discrete(n=4) #offers
def reset(self, seed=None, options=None):
self.behavior_probs = setup_behavior_probs_dict_from_init_data()
self.t = 0
self.cumC = 0.0
self.S_t = self.build_state(self.S_0_info)
return self.S_t._asdict(), {"t": 0, "purchase_prob": 0.5}
def build_state(self, info):
return self.State(*[info[sn] for sn in self.SNames])
def build_decision(self, info):
return self.Decision(*[info[xn] for xn in self.xNames])
def done(self):
return self.t >= self.T
# return self.t >= T
# exog info function
def W_fn(self):
behav_probs = get_behavior_probs(self.S_t.C__lastNOffers_t, self.behavior_probs); #print(f'beh_probs: {beh_probs}')
W_tt1 = multinomial_int(behav_probs)
return W_tt1, behav_probs
# transition function
def S__M_fn(self, x_t, W_tt1):
# C__sens
C__sens_tt1 = self.S_t.C__sens_t
# C__nVisits
if W_tt1==1:
C__nVisits_tt1 = self.S_t.C__nVisits_t + 1
else:
C__nVisits_tt1 = self.S_t.C__nVisits_t
# C__lastNOffers
if x_t.x_t > 0: #don't keep 0 offers
C__lastNOffers_tt1 = np.append(self.S_t.C__lastNOffers_t, x_t.x_t)
if C__lastNOffers_tt1.size > 3:
C__lastNOffers_tt1 = np.delete(C__lastNOffers_tt1, 0)
else:
C__lastNOffers_tt1 = self.S_t.C__lastNOffers_t
# C__nPurch
if W_tt1 == 2:
C__nPurch_tt1 = self.S_t.C__nPurch_t + 1
else:
C__nPurch_tt1 = self.S_t.C__nPurch_t
# C__nPurchSinceLastOffer
C__nPurchSinceLastOffer_tt1 = self.S_t.C__nPurchSinceLastOffer_t
if W_tt1 == 2:
C__nPurchSinceLastOffer_tt1 = self.S_t.C__nPurchSinceLastOffer_t + 1
if x_t.x_t > 0:
C__nPurchSinceLastOffer_tt1 = 0 #reset purchases
S_tt1 = self.build_state({
'C__sens_t': C__sens_tt1,
'C__nVisits_t': C__nVisits_tt1,
'C__lastNOffers_t': C__lastNOffers_tt1,
'C__nPurch_t': C__nPurch_tt1,
'C__nPurchSinceLastOffer_t': C__nPurchSinceLastOffer_tt1,
'W__behav_t': W_tt1
})
return S_tt1
# reward function
def C_fn(self):
C = self.S_t.C__nPurchSinceLastOffer_t
return C
def step(self, action):
if not action in [0,1,2,3]:
raise ValueError("Action must be in {0,1,2,3}")
info = {'x_t': action}
x_t = self.build_decision(info)
W_tt1, beh_probs = self.W_fn()
C = self.C_fn()
self.cumC += C
self.S_t = self.S__M_fn(x_t, W_tt1)
self.t += 1
return (
self.S_t._asdict(), self.cumC, self.done(), self.done(),
{"t": self.t, "purchase_prob": beh_probs[-1]}
)M_config = {
# "alpha" : 0.5,
"seed" : 42,
"T": HORIZON,
"max_episode_steps": HORIZON,
# "max_episode_steps": T,
"horizon": HORIZON
# "horizon": T
# "disable_env_checking": True
}M_test = CustomerModel(M_config)from ray.rllib.utils.pre_checks.env import check_env
check_env(M_test)2023-05-24 23:54:28,205 WARNING env.py:155 -- Your env doesn't have a .spec.max_episode_steps attribute. Your horizon will default to infinity, and your environment will not be reset.As described in 4.3.3, the uncertainty model consists of the random process that provides the customer behavior at time \(t\), which could be one of:
There are two main meta-classes of policy design. Each of these has two subclasses: - Policy Search - Policy Function Approximations (PFAs) - Cost Function Approximations (CFAs) - Lookahead - Value Function Approximations (VFAs) - Direct Lookaheads (DLAs)
In this project we will use two policies: - X__Random, which is a random policy that provides a decision from a fixed discrete distribution regardless of the state of the SUS. This policy is used for comparison with an optimized policy. - X__PPO, a Proximal Policy Optimization implementation from RLlib. This policy belongs to the PFA class.
X__Random is implemented by the following method in class CustomerPolicy():
def X__Random(self, S_t, explore, modify_env_at_step):
offer_r = multinomial_int([0.70, 0.1, 0.1, 0.1])
info = {
'x_t': offer_r
}
return self.model.build_decision(info)X__PPO is implemented (and wrapped) by the following method in class CustomerPolicy():
def X__PPO(self, S_t, explore, modify_env_at_step):
offer = self.algo.compute_single_action(S_t, explore=explore)
info = {
'x_t': offer
}
return self.model.build_decision(info)The CustomerPolicy() class implements the policy design.
import random
class CustomerPolicy():
def __init__(self, model, piNames, algo):
self.model = model
self.piNames = piNames
self.Policy = namedtuple('Policy', piNames)
self.algo = algo
# def X__Random(self, **kwargs):
def X__Random(self, S_t, explore, modify_env_at_step):
offer_r = multinomial_int([0.70, 0.1, 0.1, 0.1])
info = {
'x_t': offer_r
}
return self.model.build_decision(info)
# def X__PPO(self, **kwargs):
def X__PPO(self, S_t, explore, modify_env_at_step):
offer = self.algo.compute_single_action(S_t, explore=explore)
info = {
'x_t': offer
}
return self.model.build_decision(info)
def plot_evalu(self, df_non, df, comment):
legendlabels = [r'$\mathrm{non}$', r'$\mathrm{opt}$']
n_charts = 7
ylabelsize = 14
mpl.rcParams['lines.linewidth'] = 1.2
mycolors = ['g', 'b', 'c', 'm']
fig, axs = plt.subplots(n_charts, sharex=True)
# fig.set_figwidth(13); fig.set_figheight(9)
fig.set_figwidth(20); fig.set_figheight(9)
fig.suptitle(f'PERFORMANCE OF OPTIMIZED PPO POLICY\nOptimal (magenta), Non-optimal (cyan)\n '+f'{comment}', fontsize=16)
i = 0
axs[i].set_ylim(auto=True); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(False)
axs[i].step(df_non['x_t'], 'c:', label=labels[i], where='post')
axs[i].step(df['x_t'], 'm', label=labels[i], where='post')
axs[i].set_ylabel('Offers\nmade to\ncustomer', rotation=0, ha='right', va='center', fontweight='bold');
axs[i].yaxis.set_ticks(ticks=[0,1,2,3], minor=False)
axs[i].set_yticks([0,1,2,3], minor=False)
axs[i].set_yticklabels(labels=['None', 'Adv', 'SmallDisc', 'LargeDisc'], minor=False)
i = 1
axs[i].set_ylim(auto=True); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(False)
axs[i].step(df_non['W__behav_t'], 'c:', where='post')
axs[i].step(df['W__behav_t'], 'm', where='post')
axs[i].set_ylabel('Customer\nBehaviors', rotation=0, ha='right', va='center', fontweight='bold');
axs[i].set_yticks([0,1,2], minor=False)
axs[i].set_yticklabels(labels=['None', 'Visit', 'Purchase'], minor=False)
i = 2
axs[i].set_ylim(auto=True); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(True)
axs[i].step(df_non['C__nVisits_t'], 'c:', where='post')
axs[i].step(df['C__nVisits_t'], 'm', where='post')
axs[i].set_ylabel('Number\nof\nVisits', rotation=0, ha='right', va='center', fontweight='bold');
i = 3
axs[i].set_ylim(0, 0.75); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(True)
axs[i].step(df_non['purchase_prob'], 'c:', where='post')
axs[i].step(df['purchase_prob'], 'm', where='post')
axs[i].set_ylabel('Purchase\nProb.', rotation=0, ha='right', va='center', fontweight='bold');
i = 4
axs[i].set_ylim(auto=True); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(True)
axs[i].step(df_non['C__nPurch_t'], 'c', where='post')
axs[i].step(df['C__nPurch_t'], 'm', where='post')
axs[i].set_ylabel('Number\nof\nPurchases', rotation=0, ha='right', va='center', fontweight='bold');
i = 5
axs[i].set_ylim(auto=True); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(True)
axs[i].step(df_non['C__nPurchSinceLastOffer_t'], 'c', where='post')
axs[i].step(df['C__nPurchSinceLastOffer_t'], 'm', where='post')
axs[i].set_ylabel('REWARD:\nNumber of\nPurchases\nsince last\noffer', rotation=0, ha='right', va='center', fontweight='bold');
from matplotlib.ticker import MaxNLocator
axs[i].yaxis.set_major_locator(MaxNLocator(integer=True))
i = 6
axs[i].set_ylim(auto=True); axs[i].spines['top'].set_visible(False); axs[i].spines['right'].set_visible(True); axs[i].spines['bottom'].set_visible(True)
axs[i].step(df_non['cumC'], 'c', where='post')
axs[i].step(df['cumC'], 'm', where='post')
axs[i].set_ylabel('CUM. REWARD', rotation=0, ha='right', va='center', fontweight='bold');
axs[i].set_xlabel('$t$', rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize);
fig.legend(labels=legendlabels, loc='lower left', fontsize=16)An instance of CustomerModel is automatically created by the RLlib framework. We still have to create an instance of the CustomerPolicy. We have the option of either restoring an existing checkpoint (which includes a policy), or creating a new checkpoint.
# T = 5000!ls -al "{base_dir}"total 28396
drwx------ 2 root root 4096 May 21 14:41 -checkpoint_000020
drwx------ 2 root root 4096 May 23 12:39 checkpoint_000020
drwx------ 2 root root 4096 May 21 13:52 '-checkpoint_000020 (1)'
drwx------ 2 root root 4096 May 20 21:19 '-checkpoint_000020 (2)'
drwx------ 2 root root 4096 May 20 13:18 '-checkpoint_000020 (3)'
drwx------ 2 root root 4096 May 20 21:37 -checkpoint_000021
drwx------ 2 root root 4096 May 20 16:21 -checkpoint_000030
-rw------- 1 root root 210792 May 20 14:48 next-best-action-rl_ANNO.ipynb
-rw------- 1 root root 4553810 May 18 21:02 'next-best-action-rl_PORT^v1.ipynb'
-rw------- 1 root root 7371975 May 22 18:45 'next-best-action-rl_PORT^v2.ipynb'
-rw------- 1 root root 9737128 May 23 19:38 'next-best-action-rl_PORT^v3.ipynb'
-rw------- 1 root root 7173523 May 24 23:49 'next-best-action-rl_PORT^v4.ipynb'# restore also (includes policy)
from ray.rllib.algorithms.algorithm import Algorithm
# Use the Algorithm's `from_checkpoint` utility to get a new algo instance
# that has the exact same state as the old one, from which the checkpoint was
# created in the first place:
ppo_algo = Algorithm.from_checkpoint(f"{base_dir}/checkpoint_000020")
# P = Algorithm.from_checkpoint(f"{base_dir}/checkpoint_000020")
# Continue training:
# my_new_ppo.train()
# OR
# Do inference:
# ppo_algo.compute_single_action(obs[0], explore=explore)2023-05-24 23:50:39,741 WARNING checkpoints.py:109 -- No `rllib_checkpoint.json` file found in checkpoint directory /content/gdrive/My Drive/Katsov/tensor-house/recipe-04/checkpoint_000020! Trying to extract checkpoint info from other files found in that dir.
WARNING:ray.tune.utils.util:Install gputil for GPU system monitoring.
2023-05-24 23:50:44,234 INFO worker.py:1625 -- Started a local Ray instance.# plot rewards from checkpoint using tensorboard# ppo_algo.stop() #for debug if neededfrom ray.rllib.algorithms.ppo import PPO, PPOConfig
# from envs_03 import FrozenPond
ppo_config = (
PPOConfig()
.framework("torch")
# .rollouts(create_env_on_local_worker=True)
.rollouts(num_rollout_workers=0) #to train on CPUs only !!!!!!!!!!!!!!!!!!!
.debugging(seed=0, log_level="ERROR")
.training(model={"fcnet_hiddens": [32, 32]})
# .environment(env=Customer, env_config=env_config)
# .environment(env_config=env_config)
)
ppo_algo = ppo_config.build(env=CustomerModel); ppo_algo
# ppo_algo = ppo_config.build(); ppo
# P = ppo_algoWARNING:ray.tune.utils.util:Install gputil for GPU system monitoring.PPOepisode_reward_mean = []%%time
from ray.tune.logger import pretty_print
# train_info = ppo.train(); #train_info
# episode_reward_mean = []
for i in range(20): #20
print(i, end='.')
result = ppo_algo.train()
# result = P.train()
# print(pretty_print(result))
episode_reward_mean.append(result["episode_reward_mean"])
print('\n')0.1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
CPU times: user 9min 44s, sys: 4.59 s, total: 9min 49s
Wall time: 10min 12s# plt.plot(episode_reward_mean);
plt.plot(episode_reward_mean);
plt.title('Episode Reward Mean')
plt.xlabel('episode')
plt.ylabel('Reward Mean');
%%time
ppo_algo.evaluate()["evaluation"]["episode_reward_mean"]
# P.evaluate()["evaluation"]["episode_reward_mean"]CPU times: user 1min 32s, sys: 1.48 s, total: 1min 34s
Wall time: 1min 34s23.00475# save checkpoint
# https://docs.ray.io/en/latest/rllib/rllib-saving-and-loading-algos-and-policies.html
# https://docs.ray.io/en/latest/rllib/package_ref/doc/ray.rllib.algorithms.algorithm.Algorithm.save.html#ray.rllib.algorithms.algorithm.Algorithm.save
path_to_checkpoint = ppo_algo.save(checkpoint_dir=base_dir)
# path_to_checkpoint = P.save(checkpoint_dir=base_dir)!ls -al "{path_to_checkpoint}"total 35
-rw------- 1 root root 11938 May 25 00:07 algorithm_state.pkl
-rw------- 1 root root 0 May 25 00:07 .is_checkpoint
drwx------ 3 root root 4096 May 25 00:07 policies
-rw------- 1 root root 301 May 25 00:07 rllib_checkpoint.json
-rw------- 1 root root 18450 May 25 00:07 .tune_metadata# test
# ppo_algo.stop()# ppo_algo.train() #broke after .stop()
# ppo_algo.evaluate() #seemed to work after .stop()# restore also (includes policy)
# from ray.rllib.algorithms.algorithm import Algorithm
# ppo_algo = Algorithm.from_checkpoint(path_to_checkpoint)stop_time_evalu = 4000M_evalu = CustomerModel(M_config)
P_evalu = CustomerPolicy(M_evalu, piNames, ppo_algo)M_config{'seed': 42, 'T': 4000, 'max_episode_steps': 4000, 'horizon': 4000}def run_policy_evalu(piName_evalu, stop_time_evalu, explore=None, modify_env_at_step=None):
record = []
obs = M_evalu.reset()[0]
for t in range(stop_time_evalu):
x_t = getattr(P_evalu, piName_evalu)(obs, explore, modify_env_at_step)
obs, rew, trm, trn, inf = M_evalu.step(x_t.x_t)
record_t = list(obs.values()) + [rew] + [x_t.x_t] + [explore, modify_env_at_step] + [inf['purchase_prob']]
record.append(record_t)
# modify env
if (not modify_env_at_step==None) and (inf["t"] == modify_env_at_step):
M_evalu.behavior_probs['133'] = [0.90, 0.08, 0.02]
M_evalu.behavior_probs['323'] = [0.90, 0.08, 0.02]
M_evalu.behavior_probs['321'] = [0.20, 0.10, 0.70] #new best
M_evalu.behavior_probs['123'] = [0.20, 0.10, 0.70] #new best
M_evalu.behavior_probs['111'] = [0.20, 0.10, 0.70] #new best
M_evalu.behavior_probs['222'] = [0.20, 0.10, 0.70] #new best
M_evalu.behavior_probs['333'] = [0.20, 0.10, 0.70] #new best
print(f"ENVIRONMENT MODIFIED at step {inf['t']}...")
print(f"M_evalu.behavior_probs['133']: {M_evalu.behavior_probs['133']}")
print(f"M_evalu.behavior_probs['323']: {M_evalu.behavior_probs['323']}")
print(f"M_evalu.behavior_probs['321']: {M_evalu.behavior_probs['321']}") #new best
print(f"M_evalu.behavior_probs['123']: {M_evalu.behavior_probs['123']}") #new best
print(f"M_evalu.behavior_probs['111']: {M_evalu.behavior_probs['111']}") #new best
print(f"M_evalu.behavior_probs['222']: {M_evalu.behavior_probs['222']}") #new best
print(f"M_evalu.behavior_probs['333']: {M_evalu.behavior_probs['333']}") #new best
cumC = M_evalu.cumC
return cumC, recordpiName_evalu_non = 'X__Random'
labels = ['C__sens_t','C__nVisits_t','C__lastNOffers_t','C__nPurch_t','C__nPurchSinceLastOffer_t','W__behav_t'] +\
['cumC'] + ['x_t'] + ['explore', 'modify_env_at_step'] + ['purchase_prob']
# print(f'{int(cumC)=:,}')
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=False, modify_env_at_step=None)
df_non = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]
#no explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=False, modify_env_at_step=HORIZON//40)
df_non_nxmod = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]
#explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=True, modify_env_at_step=HORIZON//40)
df_non_exmod = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]
ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]piName_evalu = 'X__PPO'
labels = ['C__sens_t','C__nVisits_t','C__lastNOffers_t','C__nPurch_t','C__nPurchSinceLastOffer_t','W__behav_t'] +\
['cumC'] + ['x_t'] + ['explore', 'modify_env_at_step'] + ['purchase_prob']
# print(f'{int(cumC)=:,}')
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=False, modify_env_at_step=None)
df = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]
#no explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=False, modify_env_at_step=HORIZON//40)
df_nxmod = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]
#explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=True, modify_env_at_step=HORIZON//40)
df_exmod = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]
ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]P_evalu.plot_evalu(df_non, df, 'Unchanged environment')/usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:283: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)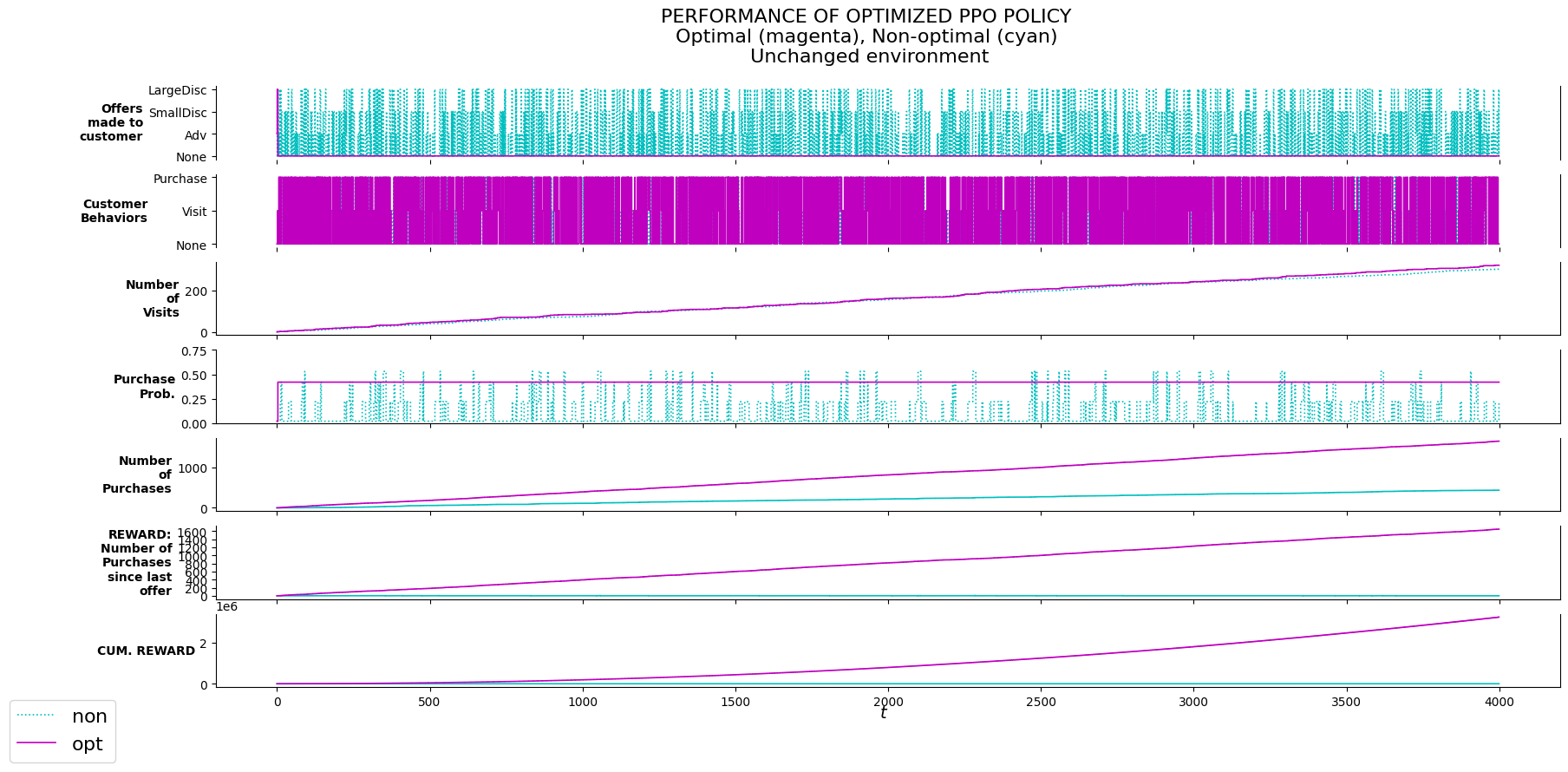
P_evalu.plot_evalu(df_non_nxmod, df_nxmod, 'Changed Env at t=100 -- no exploration after change')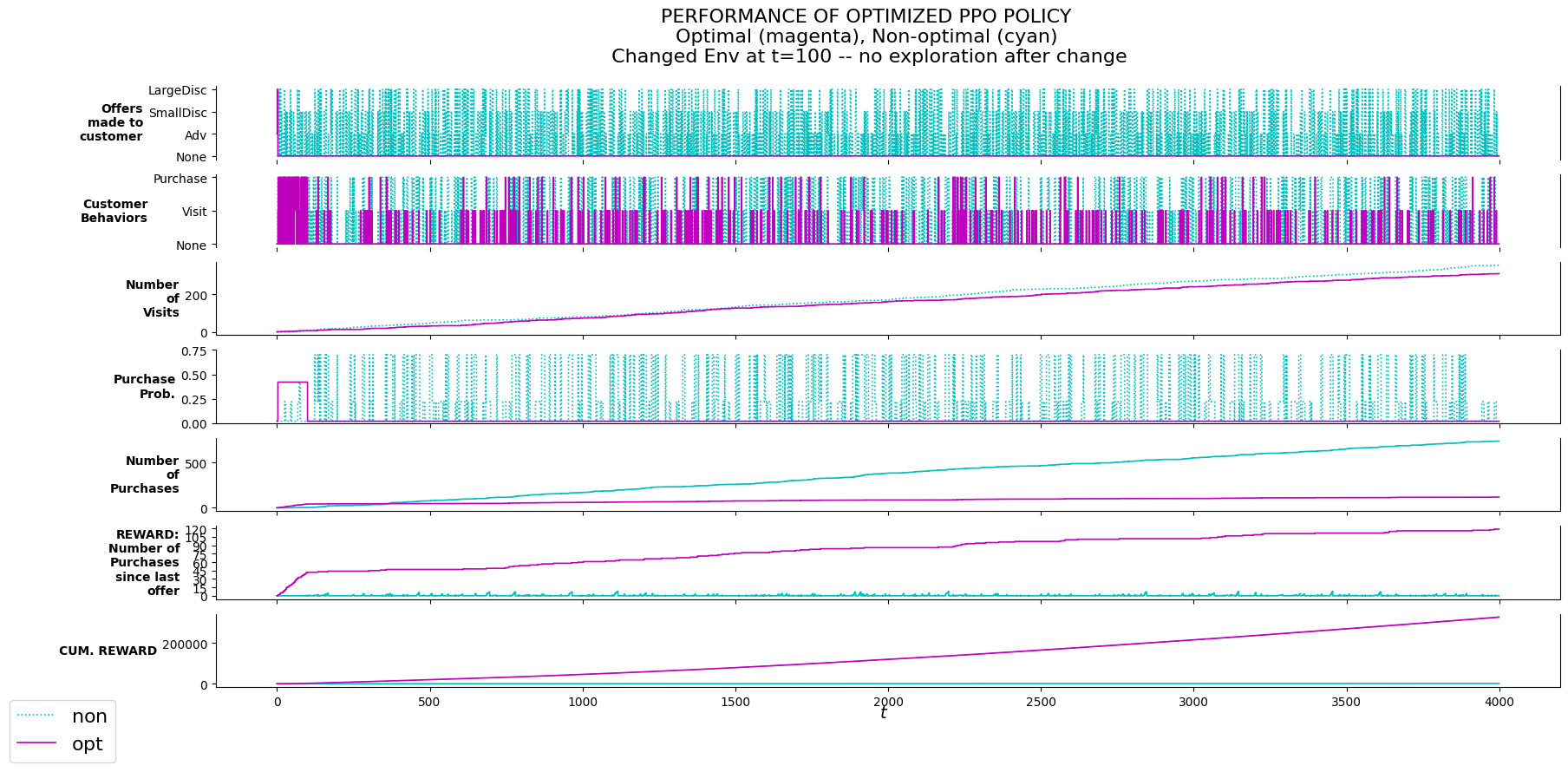
P_evalu.plot_evalu(df_non_exmod, df_exmod, 'Changed Env at t=100 -- exploration after change')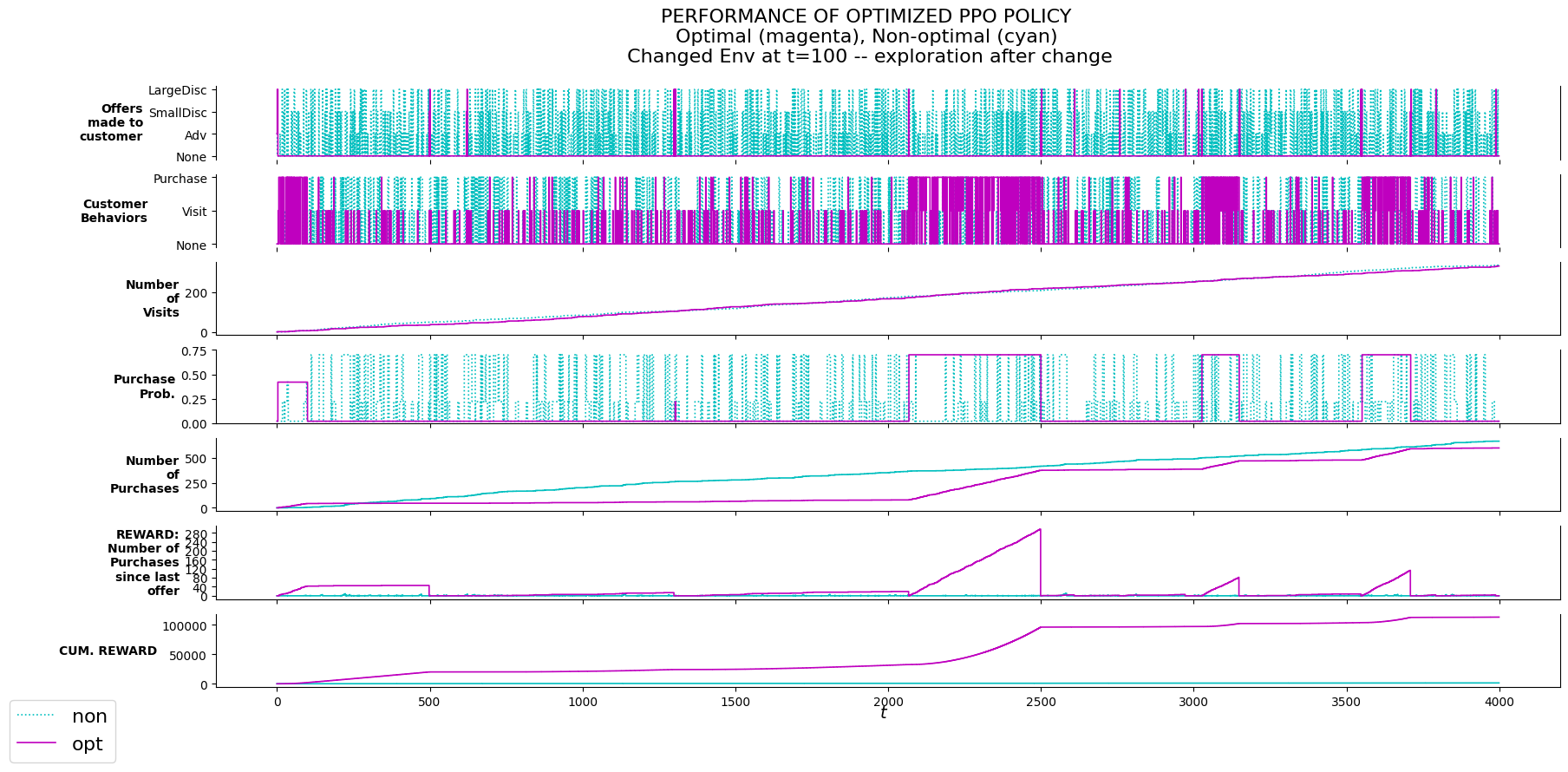
piName_evalu_non = 'X__Random'
labels = ['C__sens_t','C__nVisits_t','C__lastNOffers_t','C__nPurch_t','C__nPurchSinceLastOffer_t','W__behav_t'] +\
['cumC'] + ['x_t'] + ['explore', 'modify_env_at_step'] + ['purchase_prob']
# print(f'{int(cumC)=:,}')
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=False, modify_env_at_step=None)
df_non = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]
#no explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=False, modify_env_at_step=HORIZON//40)
df_non_nxmod = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]
#explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=True, modify_env_at_step=HORIZON//40)
df_non_exmod = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]
ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]piName_evalu = 'X__PPO'
labels = ['C__sens_t','C__nVisits_t','C__lastNOffers_t','C__nPurch_t','C__nPurchSinceLastOffer_t','W__behav_t'] +\
['cumC'] + ['x_t'] + ['explore', 'modify_env_at_step'] + ['purchase_prob']
# print(f'{int(cumC)=:,}')
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=False, modify_env_at_step=None)
df = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]
#no explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=False, modify_env_at_step=HORIZON//40)
df_nxmod = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]
#explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=True, modify_env_at_step=HORIZON//40)
df_exmod = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]/usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:283: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]
ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]P_evalu.plot_evalu(df_non, df, 'Unchanged environment')/usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:283: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)
P_evalu.plot_evalu(df_non_nxmod, df_nxmod, 'Changed Env at t=100 -- no exploration after change')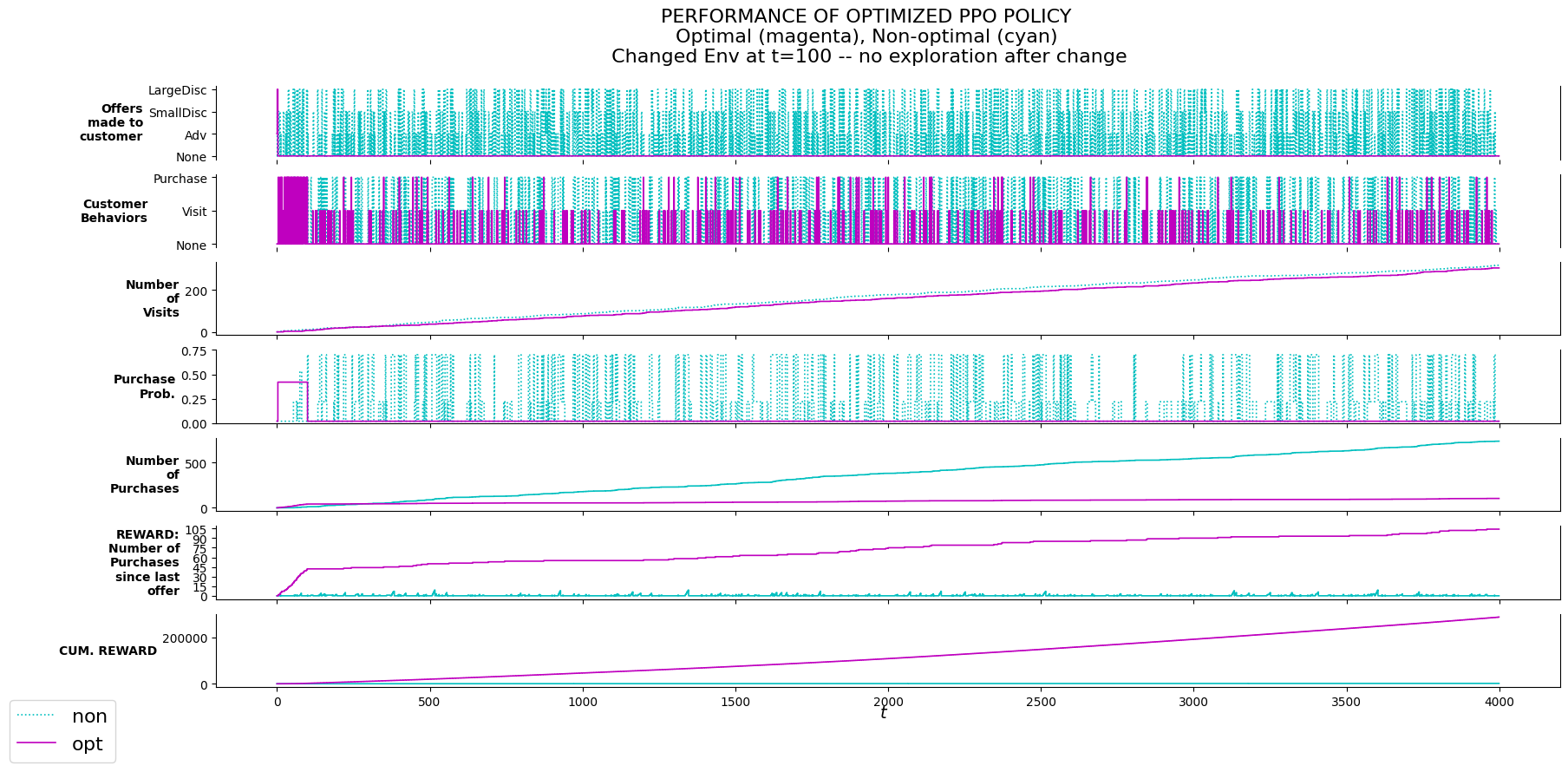
P_evalu.plot_evalu(df_non_exmod, df_exmod, 'Changed Env at t=100 -- exploration after change')
piName_evalu_non = 'X__Random'
labels = ['C__sens_t','C__nVisits_t','C__lastNOffers_t','C__nPurch_t','C__nPurchSinceLastOffer_t','W__behav_t'] +\
['cumC'] + ['x_t'] + ['explore', 'modify_env_at_step'] + ['purchase_prob']
# print(f'{int(cumC)=:,}')
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=False, modify_env_at_step=None)
df_non = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]
#no explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=False, modify_env_at_step=HORIZON//40)
df_non_nxmod = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]
#explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu_non, stop_time_evalu, explore=True, modify_env_at_step=HORIZON//40)
df_non_exmod = pd.DataFrame.from_records(data=record, columns=labels); #df_non[:10]ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]
ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]piName_evalu = 'X__PPO'
labels = ['C__sens_t','C__nVisits_t','C__lastNOffers_t','C__nPurch_t','C__nPurchSinceLastOffer_t','W__behav_t'] +\
['cumC'] + ['x_t'] + ['explore', 'modify_env_at_step'] + ['purchase_prob']
# print(f'{int(cumC)=:,}')
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=False, modify_env_at_step=None)
df = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]
#no explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=False, modify_env_at_step=HORIZON//40)
df_nxmod = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]
#explore after modified SUS
cumC, record = run_policy_evalu(piName_evalu, stop_time_evalu, explore=True, modify_env_at_step=HORIZON//40)
df_exmod = pd.DataFrame.from_records(data=record, columns=labels); #df[:10]/usr/local/lib/python3.10/dist-packages/ipykernel/ipkernel.py:283: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]
ENVIRONMENT MODIFIED at step 100...
M_evalu.behavior_probs['133']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['323']: [0.9, 0.08, 0.02]
M_evalu.behavior_probs['321']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['123']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['111']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['222']: [0.2, 0.1, 0.7]
M_evalu.behavior_probs['333']: [0.2, 0.1, 0.7]P_evalu.plot_evalu(df_non, df, 'Unchanged environment')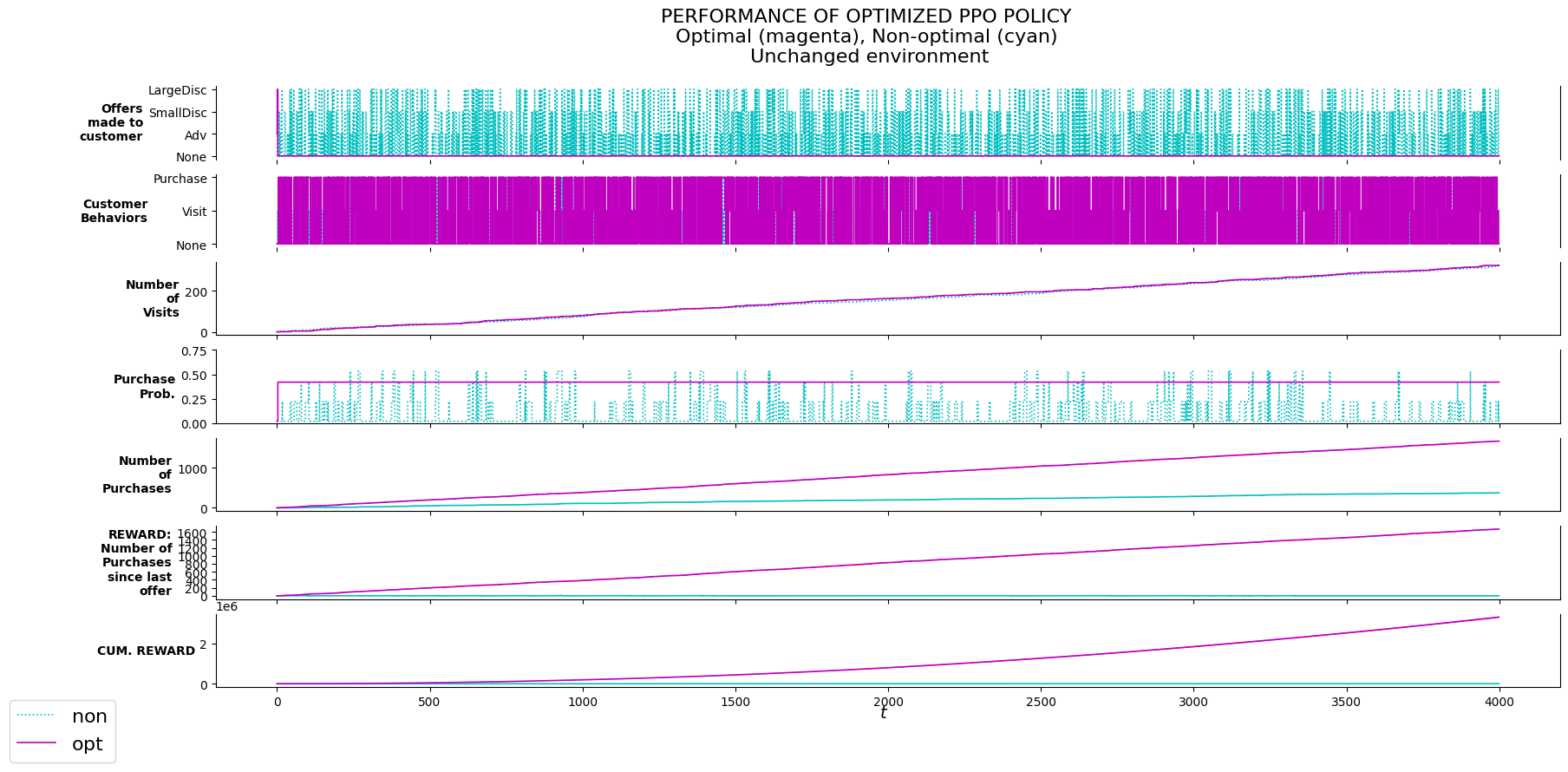
P_evalu.plot_evalu(df_non_nxmod, df_nxmod, 'Changed Env at t=100 -- no exploration after change')
P_evalu.plot_evalu(df_non_exmod, df_exmod, 'Changed Env at t=100 -- exploration after change')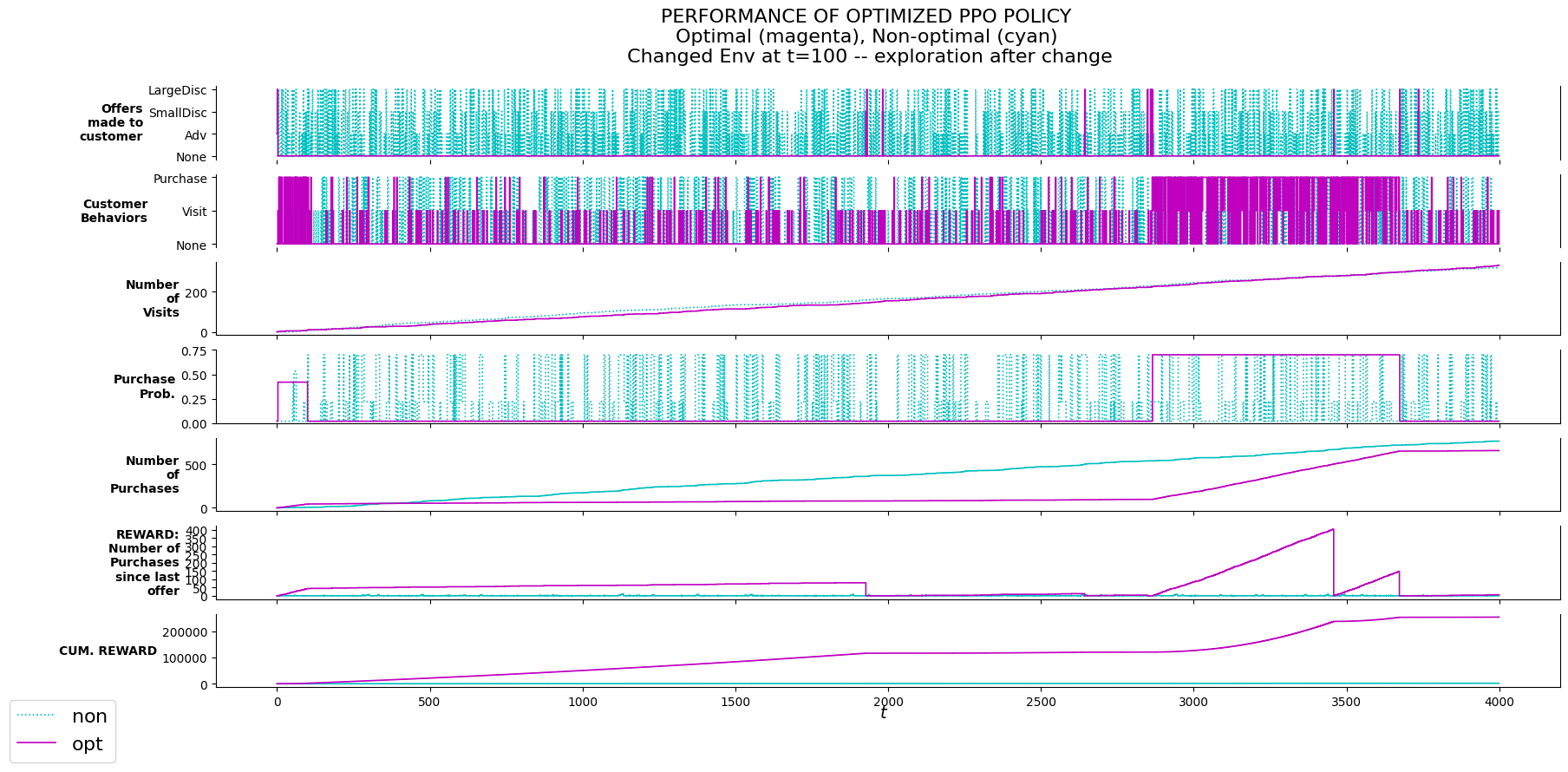
ppo_algo.stop()