The overall purpose of the project is to lay the ground work for another project that makes use of a categorical control space. The purpose of the Part 1b project is to experiment with the code from the paper:
Koudahl, M. T., van de Laar, T. W., & de Vries, B. (2023). Realising Synthetic Active Inference Agents, Part I: Epistemic Objectives and Graphical Specification Language arXiv:2306.08014
T-maze Active Inference - Policy Inference (Part 1b)
1 BUSINESS UNDERSTANDING
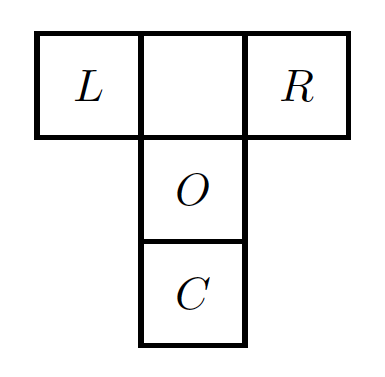
A mouse lives in a T-maze as shown in the next figure.
T-maze with letters
Either the left arm (L) or the right arm (R) of the maze contains a reward in each trial. A trial always starts with the mouse in the origin position, O. The mouse can go directly to L or to R to try and find the reward. The C postion contains a cue of where the reward is for the particular trial. The mouse can choose to first go to C, get the cue and then go to the reward location (A or B). Optimal navigation is to first go to C and then to the arm with the reward, either L or R. Moving in this way delays the reward which means that a greedy policy will lead to non-optimal behavior. When the mouse reaches either A or B it is mandated to return to the origin C indicating the end of the trial.
This project is in the form of an analysis of two papers:
Koudahl, M. T., van de Laar, T. W., & de Vries, B. (2023). Realising Synthetic Active Inference Agents, Part I: Epistemic Objectives and Graphical Specification Language arXiv:2306.08014
van de Laar, T. W., Koudahl, M. T., & de Vries, B. (2023). Realising Synthetic Active Inference Agents, Part II: Variational Message Passing Updates arXiv:2306.02733
The analysis in this notebook is mostly based on the first paper. The purpose of the current project is to lay the ground work for another project that makes use of a categorical control space. In general, the diagrams have been reproduced from the mentioned papers.
versioninfo() ##. Julia version
Julia Version 1.8.2
Commit 36034abf260 (2022-09-29 15:21 UTC)
Platform Info:
OS: Linux (x86_64-linux-gnu)
CPU: 12 × Intel(R) Core(TM) i7-8700B CPU @ 3.20GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-13.0.1 (ORCJIT, skylake)
Threads: 1 on 12 virtual cores
Environment:
JULIA_NUM_THREADS =
Updating registry at `~/.julia/registries/General.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.8/Project.toml`
No Changes to `~/.julia/environments/v1.8/Manifest.toml`
Pkg.status() ##.
Status `~/.julia/environments/v1.8/Project.toml`
[31c24e10] Distributions v0.25.108
⌅ [5b8099bc] DomainSets v0.6.6
⌃ [f6369f11] ForwardDiff v0.10.35
⌅ [a194aa59] ReactiveMP v3.8.1
⌅ [86711068] RxInfer v2.10.4
⌅ [2913bbd2] StatsBase v0.33.21
⌃ [4c63d2b9] StatsFuns v1.3.0
⌃ [9d95972d] TupleTools v1.3.0
Info Packages marked with ⌃ and ⌅ have new versions available, but those with ⌅ are restricted by compatibility constraints from upgrading. To see why use `status --outdated`
Random.seed!(1909)
TaskLocalRNG()
2 DATA UNDERSTANDING
There is no pre-existing data to be analyzed.
3 DATA PREPARATION
There is no pre-existing data to be prepared.
4 MODELING
4.1 Narrative
The next figure (from Bert de Vries at Eindhoven Technical University) shows the interactions between the agent and the environment:
Interactions-AgtEnv
The grey area shows the markov blanket of the agent. The interactions between the agent and environment can be summarized by:
This means that actions on the environment are sampled from the posterior over control signals. We will explain a bit more down below.
4.2 Core Elements
This section attempts to answer three important questions:
What metrics are we going to track?
What decisions do we intend to make?
What are the sources of uncertainty?
For this problem, we will track:
the position of the mouse
the position of the reward
whether a reward is obtained
Decisions will be in the form of agent-prescribed actions to go to one of the 4 positions.
The sources of uncertainty relating to the environment will be
the accuracy of the cue in position C
4.3 System-Under-Steer / Environment / Generative Process
The system-under-steer/environment/generative process is the mouse within the T-maze. The brain of the mouse, although embedded within the mouse which is part of the environment, is considered distinct from the environment and plays the role of the agent. The state of the environment will have a component for the position of the mouse, and another component for the position of the reward. The mouse will be steered (by its brain) by means of commands to go to specific positions in the maze.
4.3.1 State and Observation variables
The state at time \(t\) of the mouse will be given by:
\[
\tilde{s}_t = (\cal P)
\]
where
\(\cal P = \mathrm{\{O,C,L,R \}}\): the position of the mouse
The observation made by the mouse at time \(t\) will be given by:
\[
y_t = (\cal O)
\]
where
\(\mathrm{CL}\): the cue points to arm L
\(\mathrm{CR}\): the cue points to arm R
\(\mathrm{RW}\): the reward is won
\(\mathrm{NR}\): no reward is obtained
4.3.2 Decision variables
The decision variables represent what we control.
The decision or action vector is given by:
\(a_t = (a_{t})_{a\in \cal A}\) where
\(\cal{A} = \mathrm{\{O,C,L,R \}}\), the position to move to
4.3.3 Exogenous information / Autonomous variables
The exogenous information variables, aka autonomous state represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(a_t\). For this problem the exogenous information \(W_t\) is given by:
\(w_t = (w_{t})_{w\in \cal R}\) where
\(\cal{R} = \mathrm{\{RL,RR\}}\), the position of the reward
4.3.4 Transition and Observation functions
After combining the state of the mouse with the exogenous information, the resultant state of the environment at time \(t\) is now given by:
\[
\tilde{s}_t = (\cal P, \cal R)
\]
where
\(\cal P = \mathrm{\{O,C,L,R \}}\): the position of the mouse
\(\cal R = \mathrm{\{RL,RR\}}\): the position of the reward, left arm or right arm
The agent is allowed two moves (\(T=2\)). After each move the agent observes an outcome \(\cal O ∈ \mathrm{\{CL, CR, RW, NR\}}\). The observation, emitted at time \(t\), by the system-under-steer (sustr), will be given by:
\[
y_t = (\cal O)
\]
where
\(\mathrm{CL}\): the cue points to arm L
\(\mathrm{CR}\): the cue points to arm R
\(\mathrm{RW}\): the reward is won
\(\mathrm{NR}\): no reward is obtained
The agent/environment interaction may be expressed as:
\(w_t\) is the exogenous information / autonomous state
\(y_t\) is the outcome or observation
Observation model
states \(\tilde{s}\in(\cal P, \cal R)\) observations \(y\)
\((O,RL)\)
\((O,RR)\)
\((L,RL)\)
\((L,RR)\)
\((R,RL)\)
\((R,RR)\)
\((C,RL)\)
\((C,RR)\)
\(CL\)
\(0.5\)
\(0.5\)
\(1\)
\(CR\)
\(0.5\)
\(0.5\)
\(1\)
\(RW\)
\(\alpha\)
\(1-\alpha\)
\(1-\alpha\)
\(\alpha\)
\(NR\)
\(1-\alpha\)
\(\alpha\)
\(\alpha\)
\(1-\alpha\)
4.3.5 Objective function
The objective function is such that the Bethe free energy (BFE) or Generalized free energy (GFE) is minimized. This aspect will be handled by the RxInfer Julia package.
4.3.6 Implementation of the System-Under-Steer / Environment / Generative Process
N/A
4.4 Uncertainty Model
As noted above, the sources of uncertainty relating to the environment will be:
the accuracy of the cue in position C
4.5 Agent / Generative Model
The agent consists of:
A free energy functional \(F[q] = \mathbb E_q \left[\mathrm{log} \frac{q(z)}{p(x,z)}\right]\) where
\(p(x, z) = \Pi_k p(x_k,z_k \mid z_{k-1})\) is a generative model with:
On the agent’s side, the state at time \(t\) will be given by a 1-hot encoded vector \(\mathbf s_t\). The initial state prior is given by \[
p(\mathbf s_{0}) = \mathcal{Cat}(\mathbf s_{0} ∣ \mathbf d)
\]
where \(\mathbf d\) parameterizes the categorical distribution of \(\mathbf s_0\).
The observation made by the mouse at time \(t\) will be given by \(\mathbf x_t\).
4.5.2 Decision variables
On the agent’s side, the action on the environment at time \(t\) will be represented by a 1-hot encoded vector \(\mathbf u_t\). The control prior is given by \[
p(\mathbf u_k) = \mathcal{Cat}(\mathbf u_k ∣ \mathbf e_k)
\]
where \(\mathbf e_k\) parameterizes the categorical distribution of \(\mathbf u_k\).
\(\mathbf A \mathbf s_k\) parameterizes the categorical distribution of \(\mathbf x_k\).
An entry in \(A\) captures the probability of a specific observation given a specific state. Each column in \(A\) contains a categorical distribution. A specific column is selected by multiplying with \(\mathbf s\).
4.5.5 Implementation of the Agent / Generative Model / Internal Model
We start by specifying a probabilistic model for the agent that describes the agent’s internal beliefs over the external dynamics of the environment. Assuming the current time is \(t\) and \(t=1\),
To infer goal-driven (i.e. purposeful) behavior, we add prior beliefs \(p^+(x)\) about desired future observations$. This leads to an extended agent model:
In general, if \(\mathbf a\) is a 1-hot encoded random variable, and has a categorical (aka multinoulli) distribution, then
\[p(\mathbf a ∣ \boldsymbol{\rho}) = \mathcal{Cat}(\mathbf a ∣ \boldsymbol \rho) = \prod_{i} \rho_i^{a_i}\]
This means the \(i\) th component of vector \(\mathbf a\) selects the \(i\) th component of the probability vector \(\boldsymbol \rho\) of the distribution.
If the probability vector is \(\boldsymbol{\rho} = \begin{bmatrix} 0.05 \\ 0.05 \\ 0.50 \\ 0.10 \\ 0.10 \\ 0.20 \end{bmatrix}\) and the random variable \(\mathbf a\) is \(\mathbf{a} = \begin{bmatrix} 0 \\ 0 \\ 0 \\ 1 \\ 0 \\ 0 \end{bmatrix}\)
Similarly, the \(\mathbf u_{κ k}\) picks the \(\kappa\) th entry of \(\mathbf u_k\).
4.5.5.1 Generative Model for the T-maze
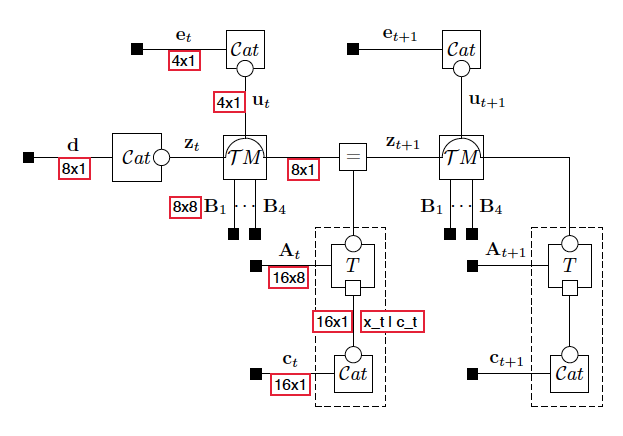
The next figure is a representation of the Constrained Forney-style Factor Graph (CFFG) of the problem:
T-maze_CFFG
The red boxes indicate the dimensions of the vectors and matrices. Transitions are indicated by \(\cal T\) and Transition-Mixtures by \(\cal TM\). The dashed box represents the Goal-Observation submodel. Next, we would like to define the generative model for the T-maze agent in RxInfer. However, we first need code for the Transition-Mixture as well as the Goal-Observation submodel.
4.5.3.2 Transition-Mixture
## include("transition_mixture/transition_mixture_ANNO^v1.jl")## ContingencyTensor is defined hereimportDistributions: mean, entropyimportStatsBase: xlogx ## This makes entropy calculations consistent with Distributions.jlconst Tensorvariate = ArrayLikeVariate{3}const DiscreteTensorvariateDistribution = Distribution{Tensorvariate, Discrete}struct ContingencyTensor{T<: Real, P <: AbstractArray{T}} <: DiscreteTensorvariateDistribution p::Pend## Only use normalised tensors for now! Or baby dies....Distributions.mean(dist::ContingencyTensor) = dist.p## Clamplog meansmean(::typeof(ReactiveMP.clamplog), dist::MatrixDirichlet) =digamma.(ReactiveMP.clamplog.(dist.a)) .-digamma.(sum(ReactiveMP.clamplog.(dist.a)); dims =1)Distributions.entropy(dist::ContingencyTensor) =-sum(xlogx.(dist.p))struct TransitionMixture end@node TransitionMixture Stochastic [out, in, s, B1, B2, B3, B4,] #.@average_energy TransitionMixture ( q_out_in_s::ContingencyTensor, #. q_B1::PointMass, q_B2::PointMass, q_B3::PointMass, q_B4::PointMass) =begin## Need to make this generic log_A_bar = [mean(ReactiveMP.clamplog, q_B1);;; mean(ReactiveMP.clamplog, q_B2);;; mean(ReactiveMP.clamplog, q_B3);;; mean(ReactiveMP.clamplog, q_B4)] B =mean(q_out_in_s) #.sum(-tr.(transpose.(eachslice(B, dims=3)) .*eachslice(log_A_bar, dims=3)))end## Used when input state is clamped@average_energy TransitionMixture ( #. q_out_s::ContingencyTensor, #. q_in::PointMass, q_B1::PointMass, q_B2::PointMass, q_B3::PointMass, q_B4::PointMass) =begin## Need to make this generic log_A_bar = [mean(ReactiveMP.clamplog,q_B1);;; mean(ReactiveMP.clamplog,q_B2);;; mean(ReactiveMP.clamplog,q_B3);;; mean(ReactiveMP.clamplog,q_B4)] B =mean(q_out_s) #.sum(-tr.(transpose.(eachslice(B, dims=3)) .*eachslice(log_A_bar, dims=3)))end
## include("helpers_ANNO^v1.jl")usingReactiveMPimportLinearAlgebra: Ifunctionsoftmax(x::Vector) r = x .-maximum(x)clamp!(r, -100, 0.0)exp.(r) ./sum(exp.(r))end## Alias for safe logarithmconst safelog = ReactiveMP.clamplog## Kronecker product## https://www.statlect.com/matrix-algebra/Kronecker-product#:~:text=The%20Kronecker%20product%20is%20an,linear%20algebra%20and%20its%20applications.## https://en.wikipedia.org/wiki/Kronecker_product## https://www.math.uwaterloo.ca/~hwolkowi/henry/reports/kronthesisschaecke04.pdffunctionconstructABCD(α::Float64, Cs, T)## Observation model A_1 = [0.50.5;0.50.5;0.00.0;0.00.0] A_2 = [0.00.0;0.00.0; α 1-α;1-α α ] A_3 = [0.00.0;0.00.0;1-α α ; α 1-α] A_4 = [1.00.0;0.01.0;0.00.0;0.00.0] A =zeros(16, 8) A[1:4, 1:2] = A_1 A[5:8, 3:4] = A_2 A[9:12, 5:6] = A_3 A[13:16, 7:8] = A_4## 0's violate the domain of the Dirichlet distribution and breaks FE calculation A .+= tiny## Transition model B_1 =kron([1111; ## Row: can I move to 1?0000;0000;0000], I(2)) B_2 =kron([0110;1001; ## Row: can I move to 2?0000;0000], I(2)) B_3 =kron([0110;0000;1001; ## Row: can I move to 3?0000], I(2)) B_4 =kron([0110;0000;0000;1001], I(2)) ## Row: can I move to 4? B = [B_1, B_2, B_3, B_4] C = [softmax(kron(ones(4), [0.0, 0.0, c, -c])) for c in Cs] ## Goal prior D =kron([1.0, 0.0, 0.0, 0.0], [0.5, 0.5]) ## Initial state priorreturn (A, B, C, D)end
constructABCD (generic function with 1 method)
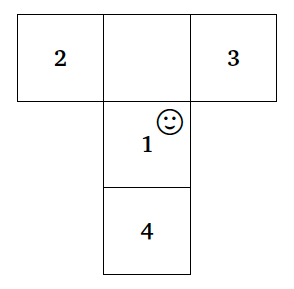
The following diagram shows the numerical values associated with the categorical states of the agent’s position:
T-maze with numbers
## Create the model@modelfunctiont_maze(A, d, B₁, B₂, B₃, B₄, T) u =randomvar(T) #. s =randomvar(T) ## Latent states #. c =datavar(Vector{Float64}, T) ## Goal prior s₀ ~Categorical(d) ## State prior #. sₜ₋₁ = s₀ #.for t in1:T ##. T=2; assume current time t=0 u[t] ~Categorical(fill(1./4., 4)) #. s[t] ~TransitionMixture(sₜ₋₁, u[t], B₁, B₂, B₃, B₄) #. c[t] ~GoalObservation(s[t], A) where { pipeline =GeneralizedPipeline(vague(Categorical, 8))} sₜ₋₁ = s[t] #.end# end;end## Pointmass constraints@constraintsfunctionpointmass_q()## q(switch) :: PointMassq(u) :: PointMass #.end## Node constraints@metafunctiont_maze_meta()GoalObservation(c, s) ->GeneralizedMeta() #.end
t_maze_meta (generic function with 1 method)
## NOT USED IN THIS NOTEBOOK# ## We need to make pointmass constraints for discrete vars by hand# import RxInfer.default_point_mass_form_constraint_optimizer# import RxInfer.PointMassFormConstraint# function default_point_mass_form_constraint_optimizer(# ::Type{Univariate},# ::Type{Discrete},# constraint::PointMassFormConstraint,# distribution)# out = zeros(length(probvec(distribution)))# out[argmax(probvec(distribution))] = 1.# PointMass(out)# end
4.6 Agent Evaluation
4.6.1 Evaluate with simulated data
## Configure experiment_T =2; ## Planning horizon_α =0.9; _cᵁᵗⁱˡ =2.0##. Reward probability and utility_its =10; ## Number of inference iterations to run_initmarginals = ( s=[Categorical(fill(1./8., 8)) for t in1:_T], ) ## Initial marginals #._A, _B, _c, _d =constructABCD(_α, [_cᵁᵗⁱˡ for t in1:_T], _T); ## Generate the matrices we need
Inference results:
Posteriors | available for (s, s₀, u)
## Inspect resultsprintln("Posterior s₀, ", probvec.(_result.posteriors[:s₀][end]), "\n") #.println("Posterior s as t=1, ", probvec.(_result.posteriors[:s][end][1])) #.println("Posterior s as t=2, ", probvec.(_result.posteriors[:s][end][2]), "\n") #.println("Posterior u as t=1, ", probvec.(_result.posteriors[:u][end][1])) #.println("Posterior u as t=2, ", probvec.(_result.posteriors[:u][end][2])) #.
Posterior s₀, [0.49999999997599515, 0.4999999999759952, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12]
Posterior s as t=1, [0.12504911587568743, 0.12504911587568743, 0.17545999968929593, 0.02264472880305665, 0.02264472880305665, 0.17545999968929593, 0.1768461556319599, 0.17684615563195993]
Posterior s as t=2, [0.21451619046215178, 0.21451619046215178, 0.17853389987901877, 0.023041443930652612, 0.023041443930652605, 0.1785338998790188, 0.08390846572817681, 0.08390846572817681]
Posterior u as t=1, [0.2500982317513749, 0.1981047284923526, 0.1981047284923526, 0.3536923112639199]
Posterior u as t=2, [0.13187528818577468, 0.3006277080558477, 0.30062770805584776, 0.26686929570253]
Inference results:
Posteriors | available for (s, s₀, u)
## Inspect resultsprintln("Posterior s₀, ", probvec.(_result.posteriors[:s₀][end]), "\n") #.println("Posterior s as t=1, ", probvec.(_result.posteriors[:s][end][1])) #.println("Posterior s as t=2, ", probvec.(_result.posteriors[:s][end][2]), "\n") #.println("Posterior u as t=1, ", probvec(_result.posteriors[:u][end][1])) ##. no dot after probvec!println("Posterior u as t=2, ", probvec(_result.posteriors[:u][end][2])) ##. no dot after probvec!
Posterior s₀, [0.49999999997599515, 0.4999999999759952, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12, 8.001571707637846e-12]
Posterior s as t=1, [0.12504911587568743, 0.12504911587568743, 0.17545999968929593, 0.02264472880305665, 0.02264472880305665, 0.17545999968929593, 0.1768461556319599, 0.17684615563195993]
Posterior s as t=2, [0.21451619046215178, 0.21451619046215178, 0.17853389987901877, 0.023041443930652612, 0.023041443930652605, 0.1785338998790188, 0.08390846572817681, 0.08390846572817681]
Posterior u as t=1, [0.0, 0.0, 0.0, 1.0]
Posterior u as t=2, [0.0, 0.0, 1.0, 0.0]