!python --versionPython 3.6.13Machine-translated content in longer documents can usually not be presented to users directly. There is a need for a human proofreader to verify the quality first. Many factors determine the amount of human effort needed. Because the sentence is a good unit of semantics it makes sense to think about effort estimation in terms of individual sentences that need to be proofread. Examples of factors that determine proofreading effort are:
The purpose of this project is to create an effort estimation model. The client has a number of pre-translation models that vary in quality. Similarly, human proofreaders on the team has varying levels of skill. In addition, the length of documents varies. Currently, a fixed compensation is paid per document. This model will enhance fairness when the client determines the compensation for proofreaders.
The dataset comes in the form of contributions, each captured as a row or data-point. Each contribution is a sentence that could be in the source language (always English) or a translation of the source sentence. There could be many variations/versions of a translated sentence, including the version provided by the translation engine initially. Human proofreaders then provide their own corrections in the form of other versions.
There are 4 kinds of contributions:
The features of the dataset are:
In this notebook we will only prepare the dataset. Modeling will occur in followup notebooks.
The development will be undertaken on the AWS platform, making use of Sagemaker Notebook instances. In addition, to make provision for eventual big-data needs, Apache Spark technology will be used.
Initially, because the current dataset is still relatively small, development and training will be done locally. Eventually, however, the code will be linked to an AWS Elastic Map Reduce (EMR) cluster to allow for a big-data training platform.
At a lower level, development will occur in Jupyter notebooks. Dataframes will not be used in the native Spark format, but rather making use of the relatively new Databricks Koalas library. The advantage of this approach is that Koalas allow for Spark functionality packaged as familiar pandas function calls.
Note that this notebook runs on a Sagemaker Notebook instance (VM). It is not accessed via Sagemaker Studio.
First, we import the necessary modules and create a SparkSession with the SageMaker-Spark dependencies attached.
!python --versionPython 3.6.13Databricks Koalas is central to our activities:
!pip install koalas
# !conda install koalas -c conda-forge #takes long!Collecting koalas
Downloading koalas-1.8.0-py3-none-any.whl (720 kB)
|████████████████████████████████| 720 kB 10.0 MB/s eta 0:00:01 |███████████▉ | 266 kB 10.0 MB/s eta 0:00:01
Requirement already satisfied: pyarrow>=0.10 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from koalas) (4.0.0)
Requirement already satisfied: pandas>=0.23.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from koalas) (1.1.5)
Requirement already satisfied: numpy<1.20.0,>=1.14 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from koalas) (1.19.5)
Requirement already satisfied: python-dateutil>=2.7.3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from pandas>=0.23.2->koalas) (2.8.1)
Requirement already satisfied: pytz>=2017.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from pandas>=0.23.2->koalas) (2021.1)
Requirement already satisfied: six>=1.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from python-dateutil>=2.7.3->pandas>=0.23.2->koalas) (1.15.0)
Installing collected packages: koalas
Successfully installed koalas-1.8.0#
# https://www.kaggle.com/general/185679
!pip install -U seaborn
import seaborn as sns
sns.__version__ #should be 0.11.1Requirement already satisfied: seaborn in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (0.11.1)
Requirement already satisfied: numpy>=1.15 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from seaborn) (1.19.5)
Requirement already satisfied: scipy>=1.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from seaborn) (1.5.3)
Requirement already satisfied: pandas>=0.23 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from seaborn) (1.1.5)
Requirement already satisfied: matplotlib>=2.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from seaborn) (3.3.4)
Requirement already satisfied: cycler>=0.10 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib>=2.2->seaborn) (0.10.0)
Requirement already satisfied: python-dateutil>=2.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib>=2.2->seaborn) (2.8.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib>=2.2->seaborn) (1.3.1)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib>=2.2->seaborn) (2.4.7)
Requirement already satisfied: pillow>=6.2.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib>=2.2->seaborn) (7.2.0)
Requirement already satisfied: six in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from cycler>=0.10->matplotlib>=2.2->seaborn) (1.15.0)
Requirement already satisfied: pytz>=2017.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from pandas>=0.23->seaborn) (2021.1)'0.11.1'import os
import boto3
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import sagemaker
from sagemaker import get_execution_role
import sagemaker_pyspark
import numpy as np
import re
import databricks.koalas as ks
ks.__version__WARNING:root:'ARROW_PRE_0_15_IPC_FORMAT' environment variable was not set. It is required to set this environment variable to '1' in both driver and executor sides if you use pyarrow>=0.15 and pyspark<3.0. Koalas will set it for you but it does not work if there is a Spark context already launched.
WARNING:root:'PYARROW_IGNORE_TIMEZONE' environment variable was not set. It is required to set this environment variable to '1' in both driver and executor sides if you use pyarrow>=2.0.0. Koalas will set it for you but it does not work if there is a Spark context already launched.'1.8.0'import io
import matplotlib.pyplot as plt
import pandas as pd
pd.__version__'1.1.5'!pip list | grep pysparkpyspark 2.4.0
sagemaker-pyspark 1.4.2sagemaker.__version__'2.40.0'role = get_execution_role()
# Configure Spark to use the SageMaker Spark dependency jars
jars = sagemaker_pyspark.classpath_jars()
classpath = ":".join(sagemaker_pyspark.classpath_jars())
# See the SageMaker Spark Github to learn how to connect to EMR from a notebook instance
spark = SparkSession.builder.config("spark.driver.extraClassPath", classpath)\
.master("local[*]").getOrCreate()
sparkSparkSession - in-memory
#
# Koalas default index
# ks.set_option('compute.default_index_type', 'sequence')
ks.get_option('compute.default_index_type')'sequence'def display_all(df):
with pd.option_context("display.max_rows", 1000, "display.max_columns", 1000):
display(df)df_E = ks.read_csv(data_location, sep='~'); df_E.shape
#- df_E = ks.read_csv(data_location, index_col=None, header=None, sep='~', encoding='utf-8'); df_E.shape(167289, 18)df_E.iloc[:5,:-2]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | e_id | e_top | be_id | be_top | c_id | c_created_at | c_kind | c_eis | c_base | a_role | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1963-0728 | ENG | 3706 | 15-0402-b | h | 1 | 733089 | Z | None | None | 1099529 | 2020-06-09 21:05:24.117 | E | 0 | None | EP |
| 1 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 2 | 733090 | Z | None | None | 1099530 | 2020-06-09 21:05:24.142 | E | 0 | None | EP |
| 2 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 3 | 733091 | Z | None | None | 1099531 | 2020-06-09 21:05:24.166 | E | 0 | None | EP |
| 3 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 4 | 733092 | Z | None | None | 1099532 | 2020-06-09 21:05:24.191 | E | 0 | None | EP |
| 4 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 5 | 733093 | Z | None | None | 1099533 | 2020-06-09 21:05:24.219 | E | 0 | None | EP |
df_E.info()databricks.koalas.frame.DataFrame
Int64Index: 167289 entries, 0 to 167288
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 m_descriptor 167289 non-null object
1 t_lan 167289 non-null object
2 t_senc 167289 non-null int32
3 t_version 167289 non-null object
4 s_typ 167289 non-null object
5 s_rsen 167289 non-null int32
6 e_id 167289 non-null int32
7 e_top 167289 non-null object
8 be_id 0 non-null object
9 be_top 0 non-null object
10 c_id 167289 non-null int32
11 c_created_at 167289 non-null datetime64[ns]
12 c_kind 167289 non-null object
13 c_eis 167289 non-null int32
14 c_base 0 non-null object
15 a_role 167289 non-null object
16 u_name 167289 non-null object
17 e_content 167287 non-null object
dtypes: datetime64[ns](1), int32(5), object(12)#
# drop features that won't be used
df_E = df_E.drop(['e_id','e_top','be_id','be_top','c_id','c_created_at','c_kind','c_eis','c_base','a_role','u_name'], axis=1)
df_E.iloc[:5,:-1]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | |
|---|---|---|---|---|---|---|
| 0 | 1963-0728 | ENG | 3706 | 15-0402-b | h | 1 |
| 1 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 2 |
| 2 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 3 |
| 3 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 4 |
| 4 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 5 |
#
# handle NaNs in e_content
e_content_nans = df_E['e_content'].isna()
df_E[e_content_nans]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | e_content | |
|---|---|---|---|---|---|---|---|
| 99927 | 1956-0805 | ENG | 1430 | 15-0402-b | n | 1176 | None |
| 162847 | 1957-0419 | ENG | 645 | 15-0401-b | n | 505 | None |
#
#replace e_content NaNs with empty strings
df_E.loc[e_content_nans, 'e_content'] = ''
# df_E.loc[e_content_nans, ['e_content']]
# OR
df_E[df_E['e_content']=='']| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | e_content | |
|---|---|---|---|---|---|---|---|
| 99927 | 1956-0805 | ENG | 1430 | 15-0402-b | n | 1176 | |
| 162847 | 1957-0419 | ENG | 645 | 15-0401-b | n | 505 |
#
# add chars column
#- df_E['chars'] = [len(e) for e in df_E['e_content']] #does not work with Koalas
df_E['chars'] = df_E['e_content'].apply(len)
df_E.loc[:5,['m_descriptor','t_lan','t_version','s_rsen','chars']]| m_descriptor | t_lan | t_version | s_rsen | chars | |
|---|---|---|---|---|---|
| 0 | 1963-0728 | ENG | 15-0402-b | 1 | 37 |
| 1 | 1963-0728 | ENG | 15-0402-b | 2 | 27 |
| 2 | 1963-0728 | ENG | 15-0402-b | 3 | 19 |
| 3 | 1963-0728 | ENG | 15-0402-b | 4 | 64 |
| 4 | 1963-0728 | ENG | 15-0402-b | 5 | 312 |
| 5 | 1963-0728 | ENG | 15-0402-b | 6 | 360 |
#
# df_E.loc[e_content_nans, ['e_content','chars']]
# OR
df_E[df_E['chars']==0]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | e_content | chars | |
|---|---|---|---|---|---|---|---|---|
| 99927 | 1956-0805 | ENG | 1430 | 15-0402-b | n | 1176 | 0 | |
| 162847 | 1957-0419 | ENG | 645 | 15-0401-b | n | 505 | 0 |
#
# add words column
# https://www.geeksforgeeks.org/python-program-to-count-words-in-a-sentence/
#- df_E['words'] = [len(re.findall(r'\w+', e)) for e in df_E['e_content']] #does not work in Koalas
df_E['words'] = df_E['e_content'].apply(lambda e: len(re.findall(r'\w+', e)))
df_E.loc[:5,['m_descriptor','t_lan','t_senc','t_version','s_typ','s_rsen','chars','words']]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | chars | words | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1963-0728 | ENG | 3706 | 15-0402-b | h | 1 | 37 | 7 |
| 1 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 2 | 27 | 4 |
| 2 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 3 | 19 | 4 |
| 3 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 4 | 64 | 12 |
| 4 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 5 | 312 | 61 |
| 5 | 1963-0728 | ENG | 3706 | 15-0402-b | n | 6 | 360 | 70 |
#
#remove BER part of version from t_version so that we can use this
# column to join the English contributions with their matching
# translated contributions
#- df_E['t_version'] = ['-'.join(e.split('-')[:2]) for e in df_E['t_version']] #does not work in Koalas
df_E['t_version'] = df_E['t_version'].apply(lambda e: '-'.join(e.split('-')[:2]))
df_E.loc[:5,['m_descriptor','t_lan','t_senc','t_version','s_typ','s_rsen','chars','words']]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | chars | words | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1963-0728 | ENG | 3706 | 15-0402 | h | 1 | 37 | 7 |
| 1 | 1963-0728 | ENG | 3706 | 15-0402 | n | 2 | 27 | 4 |
| 2 | 1963-0728 | ENG | 3706 | 15-0402 | n | 3 | 19 | 4 |
| 3 | 1963-0728 | ENG | 3706 | 15-0402 | n | 4 | 64 | 12 |
| 4 | 1963-0728 | ENG | 3706 | 15-0402 | n | 5 | 312 | 61 |
| 5 | 1963-0728 | ENG | 3706 | 15-0402 | n | 6 | 360 | 70 |
#- df_C = ks.read_csv(data_location, index_col=None, header=None, sep='~', encoding='utf-8'); df_C.shape
df_C = ks.read_csv(data_location, sep='~'); df_C.shape(177283, 18)df_C.iloc[:5,:-2]| m_descriptor | t_lan | t_senc | t_version | s_typ | s_rsen | e_id | e_top | be_id | be_top | c_id | c_created_at | c_kind | c_eis | c_base | a_role | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1963-0728 | FIJ | 3714 | 15-0401-B123 | n | 2 | 51283 | M | NaN | None | 60569 | 2017-07-03 00:58:53.572 | C | 22 | None | TE |
| 1 | 1963-0728 | FIJ | 3714 | 15-0401-B123 | n | 3 | 51284 | M | NaN | None | 60570 | 2017-07-03 01:01:31.919 | C | 144 | None | TE |
| 2 | 1963-0728 | FIJ | 3714 | 15-0401-B123 | n | 4 | 51285 | M | NaN | None | 60572 | 2017-07-03 01:16:49.033 | C | 901 | None | TE |
| 3 | 1963-0728 | FIJ | 3714 | 15-0401-B123 | n | 5 | 51286 | M | NaN | None | 60574 | 2017-07-03 02:19:45.848 | C | 740 | None | TE |
| 4 | 1963-0728 | FIJ | 3714 | 15-0401-B123 | n | 6 | 51287 | M | NaN | None | 60576 | 2017-07-03 02:35:33.669 | C | 875 | None | TE |
df_V = ks.read_csv(data_location, sep='~'); df_V.shape(382895, 18)df_CV = ks.concat([df_C, df_V], axis=0); df_CV.shape(560178, 18)tmp = df_CV.sort_values(by=['m_descriptor', 't_lan','t_version','s_rsen','a_role','u_name','c_created_at'])# tmp = df_CV.sort_values(by=['m_descriptor', 't_lan','t_version','s_rsen','a_role','u_name','c_created_at'])
df_aggd_CV = df_CV.groupby(['m_descriptor', 't_lan','t_version','s_rsen','a_role','u_name']).agg({'c_eis':['sum','count'], 'e_content':'last'})
df_aggd_CV.shape(382157, 3)df_aggd_CV = df_aggd_CV.reset_index(); df_aggd_CV.shape(382157, 9)df_aggd_CV.columnsMultiIndex([('m_descriptor', ''),
( 't_lan', ''),
( 't_version', ''),
( 's_rsen', ''),
( 'a_role', ''),
( 'u_name', ''),
( 'c_eis', 'sum'),
( 'c_eis', 'count'),
( 'e_content', 'last')],
)df_aggd_CV.columns = ['m_descriptor','t_lan','t_version','s_rsen','a_role','u_name','c_eis_sum','c_eis_count','e_content']
df_aggd_CV.loc[:5,['m_descriptor','t_lan','t_version','s_rsen','a_role','c_eis_sum','c_eis_count']]| m_descriptor | t_lan | t_version | s_rsen | a_role | c_eis_sum | c_eis_count | |
|---|---|---|---|---|---|---|---|
| 0 | 1963-0728 | FIJ | 15-0401-B123 | 7 | TE | 196 | 2 |
| 1 | 1963-0728 | FIJ | 15-0401-B123 | 45 | TE | 66 | 3 |
| 2 | 1963-0728 | FIJ | 15-0401-B123 | 200 | TE | 739 | 3 |
| 3 | 1963-0728 | FIJ | 15-0401-B123 | 224 | TE | 909 | 2 |
| 4 | 1963-0728 | FIJ | 15-0401-B123 | 255 | TE | 899 | 2 |
| 5 | 1963-0728 | FIJ | 15-0401-B123 | 266 | QE | 11 | 2 |
#
# remove BER from t_version
#- df_aggd_CV['t_version'] = ['-'.join(e.split('-')[:2]) for e in df_aggd_CV['t_version']] #does not work in Koalas
df_aggd_CV['t_version'] = df_aggd_CV['t_version'].apply(lambda e: '-'.join(e.split('-')[:2]))
df_aggd_CV.loc[:5,['m_descriptor','t_lan','t_version','s_rsen','a_role','c_eis_sum','c_eis_count']]| m_descriptor | t_lan | t_version | s_rsen | a_role | c_eis_sum | c_eis_count | |
|---|---|---|---|---|---|---|---|
| 0 | 1963-0728 | FIJ | 15-0401 | 7 | TE | 196 | 2 |
| 1 | 1963-0728 | FIJ | 15-0401 | 45 | TE | 66 | 3 |
| 2 | 1963-0728 | FIJ | 15-0401 | 200 | TE | 739 | 3 |
| 3 | 1963-0728 | FIJ | 15-0401 | 224 | TE | 909 | 2 |
| 4 | 1963-0728 | FIJ | 15-0401 | 255 | TE | 899 | 2 |
| 5 | 1963-0728 | FIJ | 15-0401 | 266 | QE | 11 | 2 |
#
# df_aggd_joind_E_CV = ks.merge(df_E, df_aggd_CV, how='inner', on=['m_descriptor', 't_version', 's_rsen'], suffixes=('_E', '_CV'), sort=True) #sort not proper here
df_aggd_joind_E_CV = ks.merge(df_E, df_aggd_CV, how='inner', on=['m_descriptor', 't_version', 's_rsen'], suffixes=('_E', '_CV'))
df_aggd_joind_E_CV.sort_values(by=['m_descriptor', 't_version', 's_rsen'])
df_aggd_joind_E_CV.loc[20:30,['m_descriptor','t_lan_E','t_senc','t_version','s_typ','s_rsen','chars','words','t_lan_CV','a_role','c_eis_sum','c_eis_count']]| m_descriptor | t_lan_E | t_senc | t_version | s_typ | s_rsen | chars | words | t_lan_CV | a_role | c_eis_sum | c_eis_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 1963-0630z | ENG | 2683 | 15-0403 | n | 1272 | 82 | 12 | BEM | CE | 55 | 2 |
| 21 | 1963-0630z | ENG | 2683 | 15-0403 | n | 2160 | 64 | 14 | BEM | TE | 184 | 2 |
| 22 | 1963-0630z | ENG | 2683 | 15-0403 | n | 2277 | 128 | 22 | BEM | TE | 163 | 2 |
| 23 | 1963-0630z | ENG | 2683 | 15-0403 | c | 2322 | 76 | 17 | BEM | TE | 82 | 2 |
| 24 | 1963-0630z | ENG | 2683 | 15-0403 | n | 2360 | 22 | 4 | BEM | CE | 25 | 2 |
| 25 | 1963-0630z | ENG | 2683 | 15-0403 | n | 2402 | 43 | 9 | BEM | TE | 66 | 2 |
| 26 | 1963-0728 | ENG | 3706 | 15-0402 | n | 775 | 7 | 2 | AFR | TE | 7 | 2 |
| 27 | 1963-0728 | ENG | 3706 | 15-0402 | n | 1073 | 83 | 17 | AFR | TE | 79 | 2 |
| 28 | 1963-0728 | ENG | 3706 | 15-0402 | n | 1465 | 69 | 13 | AFR | TE | 45 | 2 |
| 29 | 1963-0728 | ENG | 3706 | 15-0402 | n | 1530 | 59 | 14 | AFR | TE | 25 | 2 |
| 30 | 1963-0728 | ENG | 3706 | 15-0402 | n | 1711 | 127 | 23 | AFR | TE | 70 | 2 |
df_aggd_joind_E_CV.shape(382157, 15)#
# rename
df = df_aggd_joind_E_CV.copy()#
# inspect range of ENG chars and words, and OTH c_eis_sum
#- display_all(ks.describe(include='all').T)
display_all(df.describe().T)
# conclusion: min and max are fine for both| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| t_senc | 382157.0 | 1604.499140 | 601.625867 | 233.0 | 1215.0 | 1544.0 | 1803.0 | 3714.0 |
| s_rsen | 382157.0 | 796.977975 | 576.160495 | 1.0 | 344.0 | 710.0 | 1139.0 | 3714.0 |
| chars | 382157.0 | 59.645394 | 48.458367 | 0.0 | 26.0 | 46.0 | 80.0 | 621.0 |
| words | 382157.0 | 11.880999 | 9.370457 | 0.0 | 5.0 | 9.0 | 16.0 | 120.0 |
| c_eis_sum | 382157.0 | 57.017639 | 1684.807546 | 1.0 | 4.0 | 13.0 | 44.0 | 929396.0 |
| c_eis_count | 382157.0 | 1.465201 | 0.548948 | 1.0 | 1.0 | 1.0 | 2.0 | 8.0 |
df.columnsIndex(['m_descriptor', 't_lan_E', 't_senc', 't_version', 's_typ', 's_rsen',
'e_content_E', 'chars', 'words', 't_lan_CV', 'a_role', 'u_name',
'c_eis_sum', 'c_eis_count', 'e_content_CV'],
dtype='object')plt.figure(figsize=(20,10))
colors = ['green']
plt.hist(df['c_eis_sum'], bins=200, density=False, histtype='bar', color=colors, label=colors)
plt.title('Distribution of c_eis (seconds)\n', fontweight ="bold")
plt.xlabel("effort (seconds)")
plt.show()
#
# remove outliers
df_deoutlrd = df[df['c_eis_sum']<180] #less than 3 minutes
# df_deoutlrd = df[df['c_eis_sum']<300] #less than 5 minutes
# df_deoutlrd = df[df['c_eis_sum']<600] #less than 10 minutes
# df_deoutlrd = df[df['c_eis_sum']<1200] #less than 20 minutesplt.figure(figsize=(20,10))
colors = ['green']
plt.hist(df_deoutlrd['c_eis_sum'], bins=200, density=False, histtype='bar', color=colors, label=colors)
plt.title('Distribution of c_eis (seconds)\n', fontweight ="bold")
plt.xlabel("effort (seconds)")
plt.show()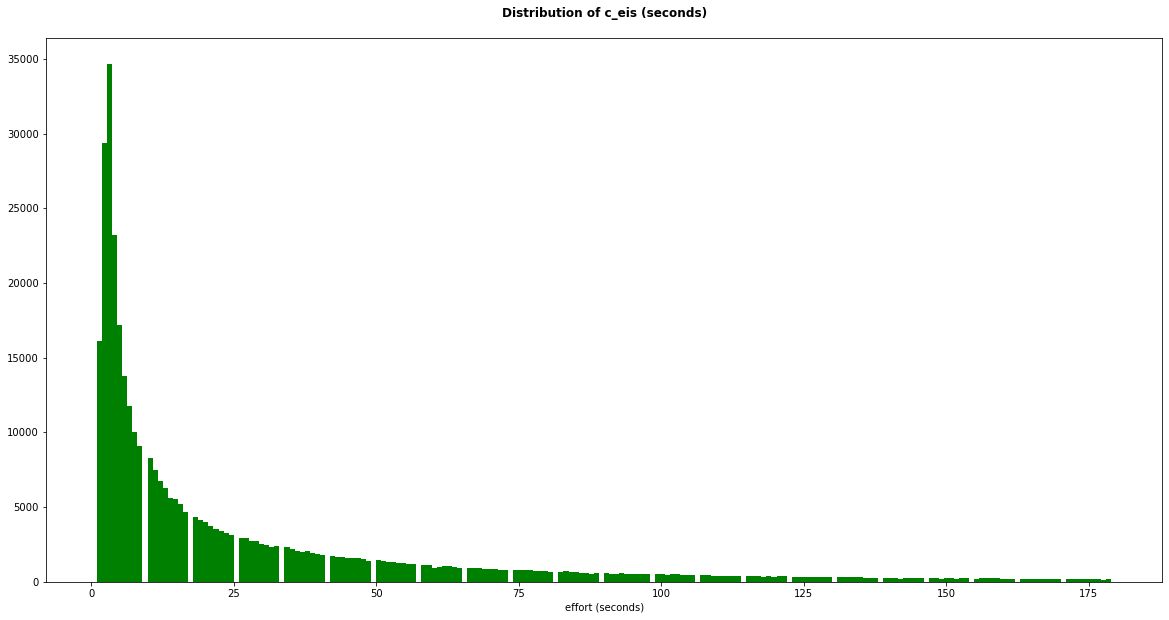
df_deoutlrd.columnsIndex(['m_descriptor', 't_lan_E', 't_senc', 't_version', 's_typ', 's_rsen',
'e_content_E', 'chars', 'words', 't_lan_CV', 'a_role', 'u_name',
'c_eis_sum', 'c_eis_count', 'e_content_CV'],
dtype='object')plt.figure(figsize=(20,10))
plt.title('c_eis_sum vs English chars', fontsize=30, color='black')
plt.xlabel('English chars', fontsize=20, color='black')
plt.ylabel('c_eis_sum', fontsize=20, rotation=90, color='black')
# plt.scatter(x='chars', y='c_eis_sum', data=df_deoutlrd);
# plt.scatter(x=df_deoutlrd['chars'], y=df_deoutlrd['c_eis_sum']);
plt.scatter(x='chars', y='c_eis_sum', data=df_deoutlrd.to_pandas());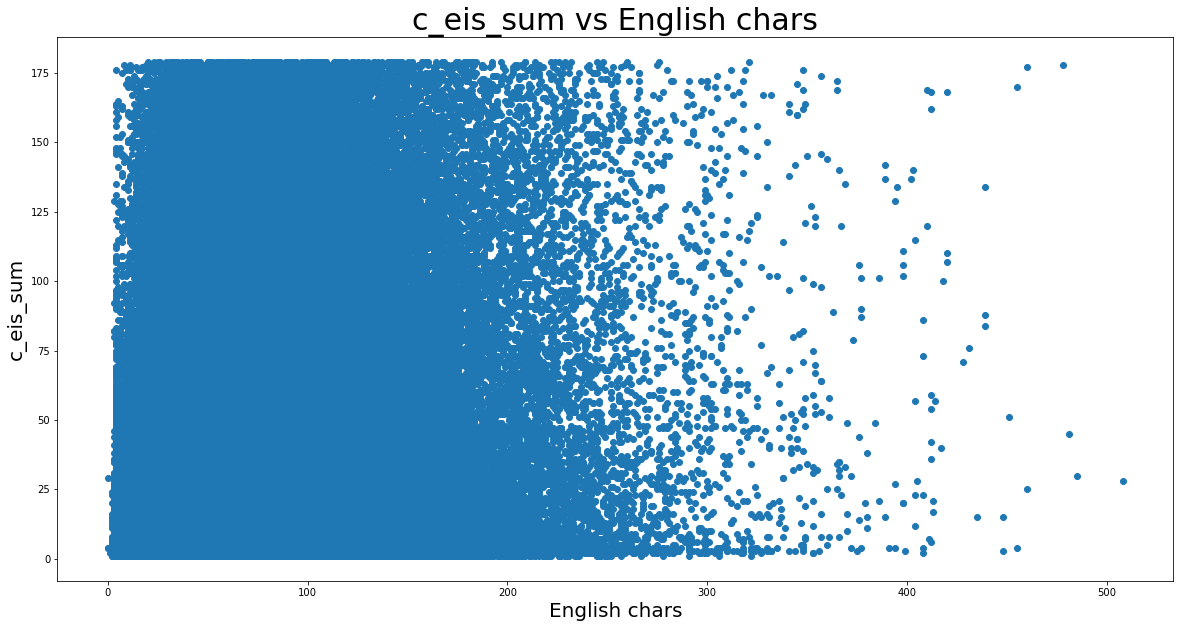
df_deoutlrd_TEs = df_deoutlrd[df_deoutlrd['a_role']=='TE']; df_deoutlrd_TEs.shape(222801, 15)df_deoutlrd_TEs.loc[0:10,['m_descriptor','t_lan_E','t_senc','t_version','s_typ','s_rsen','chars','words','t_lan_CV','a_role','c_eis_sum','c_eis_count']]| m_descriptor | t_lan_E | t_senc | t_version | s_typ | s_rsen | chars | words | t_lan_CV | a_role | c_eis_sum | c_eis_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1963-0728 | ENG | 3714 | 15-0401 | n | 45 | 67 | 12 | FIJ | TE | 66 | 3 |
| 6 | 1963-0728 | ENG | 3714 | 15-0401 | n | 322 | 99 | 21 | FIJ | TE | 148 | 2 |
| 8 | 1963-0728 | ENG | 3714 | 15-0401 | n | 387 | 34 | 4 | FIJ | TE | 32 | 2 |
| 9 | 1963-0728 | ENG | 3714 | 15-0401 | n | 1153 | 14 | 4 | FIJ | TE | 66 | 2 |
| 10 | 1963-0728 | ENG | 3714 | 15-0401 | n | 1610 | 100 | 19 | FIJ | TE | 133 | 2 |
df_deoutlrd_TEs.head()| m_descriptor | t_lan_E | t_senc | t_version | s_typ | s_rsen | e_content_E | chars | words | t_lan_CV | a_role | u_name | c_eis_sum | c_eis_count | e_content_CV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1948-0304 | ENG | 1165 | 15-0902 | n | 87 | [Blank.spot.on.tape — Ed.] feel the vibration,... | 83 | 14 | POR | TE | olisil | 22 | 2 | [Espaço em branco na fita - Ed.] sentir a vibr... |
| 2 | 1948-0304 | ENG | 1165 | 15-0902 | n | 189 | The thing that you're seeking after is already... | 84 | 17 | POR | TE | olisil | 52 | 2 | A coisa que procura já está no cofre do céu pa... |
| 13 | 1948-0304 | ENG | 1165 | 15-0902 | n | 1098 | But tonight he's not coming, trying; he's comi... | 70 | 14 | POR | TE | olisil | 49 | 2 | Mas esta noite ele não vira, a tentar; ele vem... |
| 15 | 1949-0718 | ENG | 700 | 15-0901 | n | 13 | O Father, I'm sure, with Divine faith, You wil... | 70 | 13 | GER | TE | lazbet | 73 | 2 | O Vater, ich bin mir sicher, mit göttlichem Gl... |
| 18 | 1949-0718 | ENG | 700 | 15-0901 | n | 209 | And while I was in prayer here at the altar, a... | 137 | 29 | GER | TE | lazbet | 108 | 2 | Und während ich hier am Altar im Gebet war, ei... |
plt.figure(figsize=(20,10))
plt.title('c_eis_sum vs English chars (TEs)', fontsize=30, color='black')
plt.xlabel('English chars', fontsize=20, color='black')
plt.ylabel('c_eis_sum', fontsize=20, rotation=90, color='black')
plt.scatter(x='chars', y='c_eis_sum', data=df_deoutlrd_TEs.to_pandas());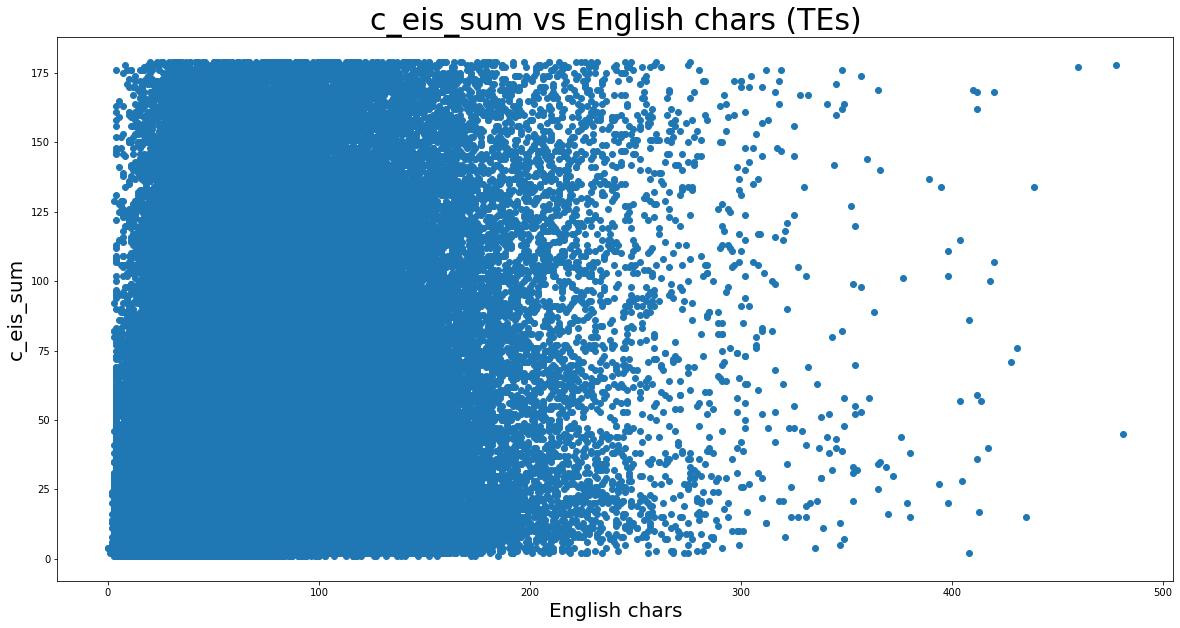
sdf = df_deoutlrd_TEs.to_spark()
csv_path = f"s3a://{bucket_str}/output/"
sdf.coalesce(1).orderBy(['m_descriptor','t_lan','t_version','s_rsen']).write.mode('overwrite').format( #1 is for a single file
"com.databricks.spark.csv").option("header","true").option("sep","~").save(csv_path)#
# test
sdf = spark.read.csv(csv_path, sep='~', header=True, inferSchema=True, nanValue='null', nullValue='null')
# csv_df = spark.read.csv(csv_path, header=True, inferSchema = True)kdf = sdf.to_koalas()kdf.shape(222801, 15)kdf.columnsIndex(['m_descriptor', 't_lan_E', 't_senc', 't_version', 's_typ', 's_rsen',
'e_content_E', 'chars', 'words', 't_lan_CV', 'a_role', 'u_name',
'c_eis_sum', 'c_eis_count', 'e_content_CV'],
dtype='object')kdf.loc[:5,['m_descriptor','t_lan_E','t_senc','t_version','s_typ','s_rsen','chars','words','t_lan_CV','a_role','c_eis_sum','c_eis_count']]| m_descriptor | t_lan_E | t_senc | t_version | s_typ | s_rsen | chars | words | t_lan_CV | a_role | c_eis_sum | c_eis_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1948-0304 | ENG | 1165 | 15-0902 | n | 1 | 102 | 21 | GER | TE | 107 | 2 |
| 1 | 1948-0304 | ENG | 1165 | 15-0902 | n | 1 | 102 | 21 | POR | TE | 50 | 2 |
| 2 | 1948-0304 | ENG | 1165 | 15-0902 | n | 2 | 27 | 6 | GER | TE | 12 | 1 |
| 3 | 1948-0304 | ENG | 1165 | 15-0902 | n | 2 | 27 | 6 | POR | TE | 9 | 1 |
| 4 | 1948-0304 | ENG | 1165 | 15-0902 | n | 3 | 36 | 7 | GER | TE | 9 | 1 |
| 5 | 1948-0304 | ENG | 1165 | 15-0902 | n | 3 | 36 | 7 | POR | TE | 9 | 1 |