In this project the client offers an Enterprise Resource Planning (ERP) system that consists of a number of modules. The system runs as a SaaS (Software-as-a-Service). The client’s need is to consider the feasibility of adding a ‘Collective Intelligence’ module to the suite of modules. A subscriber to the ERP offering can potentially identify a number of entities, for example, business units to operate as agents which may learn from each other. One scenario regards learning from the tensions inherent in the budgeting process. A business unit often asks for the maximum allocation possible even if this amount is not strictly necessary. If budgeting agents could learn from each other and a globally more optimal partitioning of funds could emerge, this could lead to a situation where the collective intelligence of the budgeting agents exceeds the sum of the intelligences of the individual agents. Less monetary resources would be wasted and an agent will only ask for money needed in the context of the needs of the company as a whole.
To get initial traction for this problem, it was decided to focus on the paper:
Kaufmann, R.; Gupta, P.; Taylor, J. An Active Inference Model of Collective Intelligence. Entropy 2021, 23, 830. https://doi.org/10.3390/e23070830
In the current part of the project, the contents of the paper as well as the Python code associated with the paper was adapted to make it clearer. Some of the changes were:
Changing the mathematical symbols
Adding some visualizations
Rearranging the contents to fit into the (modified) CIRSP-DM project standard
If in any doubt, please consult the original paper and code.
Some of the graphics from the paper were included here.
In future parts of this project, an attempt will be made to migrate the Python code to Julia code, making use of the RxInfer package for inference.
## import pdb## pdb.set_trace()from collections import defaultdictimport numpy as npimport pandas as pdfrom datetime import datetimefrom matplotlib import pyplot as pltpd.options.display.float_format ='{:20,.4f}'.formatimport seaborn as snssns.set_style("whitegrid")! python --version
Python 3.10.12
2 DATA UNDERSTANDING
There is no pre-existing data to be analyzed.
3 DATA PREPARATION
There is no pre-existing data to be prepared.
4 MODELING
4.1 Narrative
Please review the narrative in section 1.
4.2 Core Elements
This section attempts to answer three important questions:
What metrics are we going to track?
What decisions do we intend to make?
What are the sources of uncertainty?
For this problem, each agent will track:
its own position \(s^{\mathrm{Own}}\)
its partner’s position \(s^{\mathrm{Oth}}\)
Decisions will be in the form of agent-prescribed move actions.
The sources of uncertainty relating to the environment will be
the noise associated with the strength of the chemical deposit in each cell
the noise associated with the location of the food
an observation (measurement noise).
4.3 System-Under-Steer / Environment / Generative Process
The system-under-steer/environment/generative process is the body of an agent which finds inside a one-dimensional circular environment with 60 positions which can wrap around (period \(N = 60\)).
4.3.1 State variables
The state at time \(t\) of the system-under-steer (sustr), also referred to as the environment (envir), or the generative process (genpr) will be given by:
\[
\tilde{\mathbf{s}}_t = (\tilde{s}_t)
\] where
\(\tilde{s}_t \in [0 ... N-1]\) is the position of the agent in a circular environment with period \(N\). This variable is hidden and only indirectly available by means of an observation
4.3.2 Decision variables
Decisions are in the form of actions: \[
\mathbf{a}_t = (a^{\mathrm{Own}}, a^{\mathrm{Oth}})
\]
where
\(a^{\mathrm{Own}} \in \{ -1, 0, 1 \}\) is the agent’s own action at time \(t\)
\(a^{\mathrm{Oth}} \in \{ -1, 0, 1 \}\) is the other’s (partner’s) action at time \(t\)
4.3.3 Exogenous information variables
The FOOD_POSITION is exogenous.
4.3.4 Transition and Observation functions
The transition function captures the dynamics of the environment/system-under-steer/generative process:
The observation function can be represented by: \[
\mathbf{y}_t = (y^{\mathrm{Own}}, \Delta, a^{\mathrm{pp}})
\]
where
\(y^{\mathrm{Own}} \in \{ 0, 1 \}\) is the one-bit sensory input from the environment at time \(t\)
\(\Delta \in [0 ... N-1]\) is the perceived difference between the agent’s own position and its partner’s at time \(t\)
\(a^{\mathrm{pp}}\) is the partner’s last action at time \(t\)
4.3.5 Objective function
The objective function is such that the free energy is minimized. This aspect will eventually be handled by the RxInfer Julia package.
4.5 Agent / Generative Model
4.5.1 State variables
According to the agent the state of the system-under-steer/environment/generative process will be \(s_t\), rather than \(s̃_t\), which will then be given by
\[
\mathbf{s}_t = (s^{\mathrm{Own}}, s^{\mathrm{Own}}_+, s^{\mathrm{Oth}}, s^{\mathrm{Oth}}_+)
\] This is known as the internal of “belief” state, where
\(s^{\mathrm{Own}}\) is the actual belief about its own position
\(s^{\mathrm{Own}}_+\) is the desired belief about its own position
\(s^{\mathrm{Oth}}\) is the actual belief about its partner’s position
\(s^{\mathrm{Oth}}_+\) is the desired belief about its partner’s position
4.5.2 Decision variables
According to the agent the action on the environment at time \(t\) will be represented by \(u_t\), also known as the control state of the agent. In this part of the project no active or control states will be inferred.
4.5.3 Implementation
## Declarations## Environmental ConstantsENV_SIZE =60## note: pick a number divisible by 6SHORTEST_PATH =int(ENV_SIZE/3) ## distance of shared target from agent's initial positionTARGET_DELTA =int(ENV_SIZE/3) ## distance of unshared target from shared target## Agent ConstantsACTIONS = (0, -1, 1) ## possible space of actions (stay, left, right)ACTIONS_SQUARED = ((0,0),(0,-1),(0,1), ## possible combined action space for 2 agents (-1,0),(-1,-1),(-1,1), (1,0),(1,-1),(1,1))MAX_SENSE_PROBABILITY = [0.99, 0.05] ## (strong, weak) agentsSENSE_DECAY_RATE = np.log(4)/ENV_SIZE ## omega (ensures p=0.5 at ENV/2)## Simulation parametersEPOCHS =200## Number of epochs (simulation steps)N_STEPS =50## Number of gradient descent steps made to update beliefs in each epochLEARNING_RATE =0.7## Stochastic gradient descent learning rate## Experimental parameters ## ALTERITY parameter for level of ToM (0, 1)## ALIGNMENT parameter for goal alignment (0, 1)CONDITIONS = {1: { 'model': 1, 'tom': [0, 0], 'gal': 0},2: { 'model': 2, 'tom': [0, 0.5], 'gal': 0},3: { 'model': 3, 'tom': [0, 0], 'gal': 1},4: { 'model': 4, 'tom': [0, 0.5], 'gal': 1}} #.
## Helper Functions## Probability of occupying specific position as encoded in the internal statedef model_encoding(s): #.return softmax(s) #.## Derivative of the model encoding for free energy gradient calculationdef model_encoding_derivative(s): #.return D_softmax(model_encoding(s)) #.## P(stil | s)## Agent's belief about the external states (i.e. its current position in the ## world) or intention (i.e. desired position in the world) as encoded in the## internal state.def variational_density(s): #.return model_encoding(s) #.def logdiff(p1, p2):return (np.log(p1) - np.log(p2))def KLv(p1, p2):return np.multiply(p1, logdiff(p1, p2))## Kullback-Leibler divergence between densities p1 and p2. #.def KL(p1, p2):return np.sum(KLv(p1, p2))## Softmax function. The shift by s.max() is for numerical stability #.def softmax(s): #.sum= np.sum(np.exp(s - s.max())) #.return np.exp(s - s.max())/sum#.## Gradient of softmax functiondef D_softmax(q):return np.diag(q) - np.outer(q, q)def rerange(q, a):return a*q + (1-a)/ENV_SIZEdef dynamic_rerange(q): S_MIN =-10#. s = np.log(q) #. s -= np.max(s) #.# s_hat = np.maximum(s, S_MIN) #. shat = np.maximum(s, S_MIN) #.# return softmax(s_hat) #.return softmax(shat) #.## probability of partner actiondef p_action(q): p = [] qhat =0.9*q/np.max(q) #. p.append(qhat) ## a_p = 0 #. A = (1-qhat)/(np.roll(q, 1) + np.roll(q, -1)) #. p.append(np.roll(q, -1)*A) ## a_p = -1 p.append(np.roll(q, +1)*A) ## a_p = +1return np.array(p)
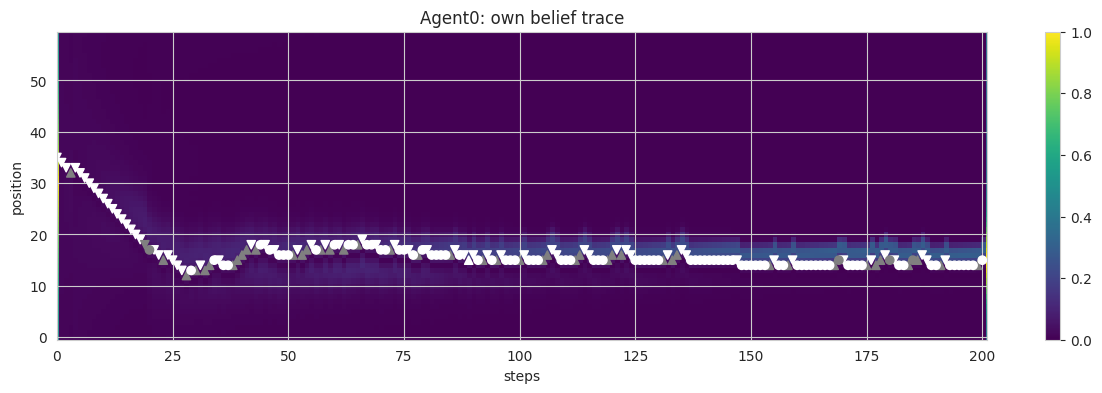
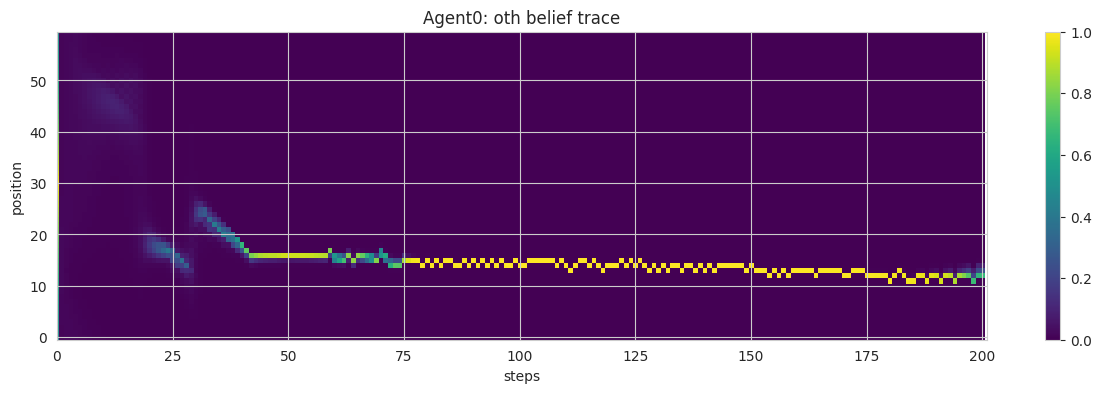
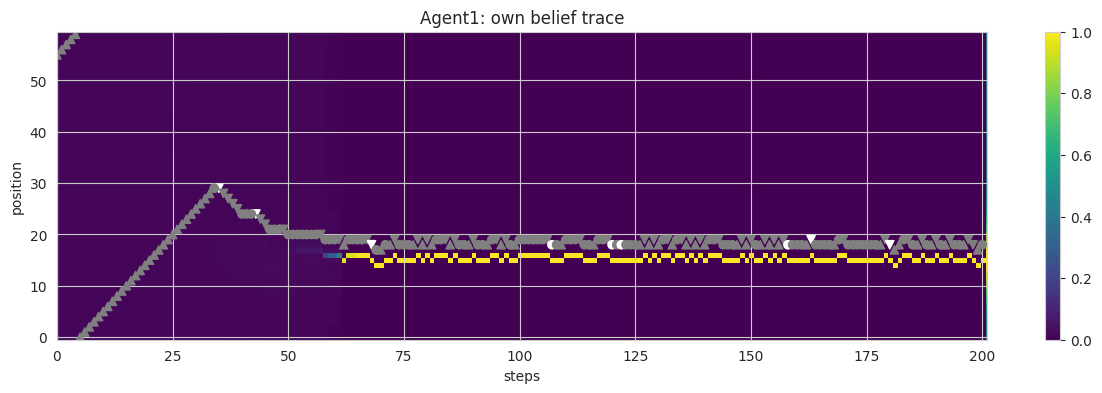
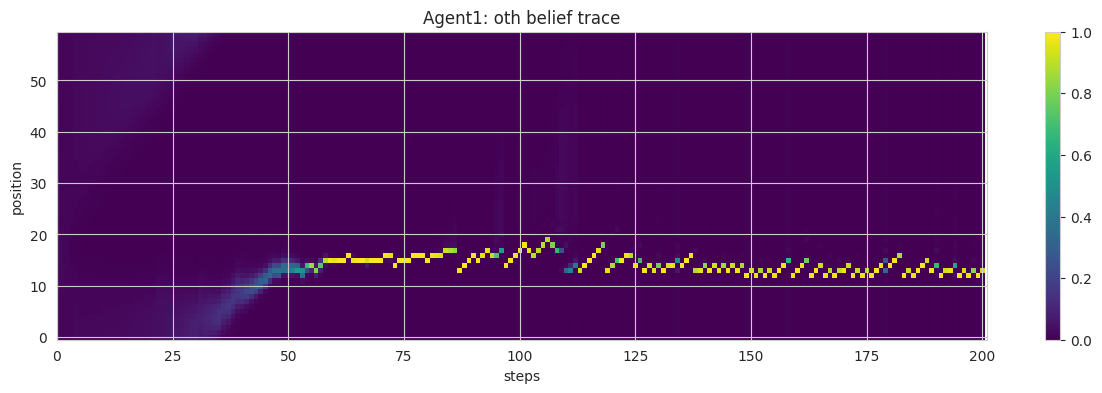
## Agent Class: Core Mechanics of AIF with ToM and Alignmentclass Agent():def__init__(self, stil, sPlus, max_sense_prob, tom, gal): #.## intializationsself.stil = stil #.self.alterity = tom ## alterity/'otherness' env = np.array(range(ENV_SIZE))self.sensory_dynamics = max_sense_prob*np.exp(-SENSE_DECAY_RATE*#. np.minimum(np.abs(env -int(ENV_SIZE/2)), np.abs(env -int(ENV_SIZE/2) - ENV_SIZE)))self.s = (np.zeros(ENV_SIZE), np.zeros(ENV_SIZE)) #.self.sPlus = (sPlus[0] + (1- gal)*sPlus[1], sPlus[0] + (1- gal)*sPlus[2]) #.self.q = (variational_density(self.s[0]), variational_density(self.s[1])) #.self.qPlus = (variational_density(self.sPlus[0]), variational_density(self.sPlus[1])) #.self.p_ap = p_action(self.qPlus[1]) #.self.a = (0, 0)self.a_pp =0self.delta =0self.y =None#.## logsself.stil_trace = [stil] #.self.stilOth_trace = [] #.self.sOwn_trace = [self.sensory_dynamics] #.self.sOth_trace = [self.sensory_dynamics] #.self.y_trace = [] #.self.a_trace = []def free_energy_own(self, a, pOwn, pOth): pOth_reranged = rerange(pOth, self.alterity) #. pOth_shifted = np.roll(pOth_reranged, self.delta + a[0] - a[1]) #.return KL(self.qPlus[0], dynamic_rerange(pOwn*pOth_shifted)) #.def free_energy_oth(self, a, pOwn, pOth): #. pOwn_reranged = rerange(pOwn, self.alterity**2) #. pOwn_shifted = np.roll(pOwn_reranged, - (self.delta + a[0] - a[1])) #.return KL(self.qPlus[1], dynamic_rerange(pOth*pOwn_shifted)) #.## Partial derivatives of the free energy with respect to belief.## FE = KL(qOwn || pOwn*qOth[-delta]) + KL(qOth || pOth*qOwn[+delta]) #.def fe_gradient(self, sPrime, pOwn, pOth, deltaPrime): #. qOwn = variational_density(sPrime[0]) #. qOth = variational_density(sPrime[1]) #. pOwn_reranged = rerange(pOwn, self.alterity**2) #. pOth_reranged = rerange(pOth, self.alterity) #. pOwn_shifted = np.roll(pOwn_reranged, -deltaPrime) #. pOth_shifted = np.roll(pOth_reranged, deltaPrime) #. DqOwn = D_softmax(qOwn) #. DqOth = D_softmax(qOth) #. v = (1+ logdiff(qOwn, dynamic_rerange(pOwn*pOth_shifted)), #.1+ logdiff(qOth, dynamic_rerange(pOth*pOwn_shifted))) #.return np.array([np.dot(DqOwn, v[0]), np.dot(DqOth, v[1])]) #.def generative_density_own(self, a=(0,0)): qOwn =self.q[0] #. sd =self.sensory_dynamics ifself.y ==1else1-self.sensory_dynamics #.return np.roll(sd*qOwn, a[0]) #.def generative_density_oth(self, a=(0,0)): #. qOwn =self.q[0] qOth =self.q[1] #. pDelta = np.roll(qOwn, -self.delta) #. p_app = np.roll(self.p_ap[ACTIONS.index(self.a_pp)], -self.a_pp) p_j_prior = qOth #. p_j_posterior = pDelta*p_app*p_j_prior #.return np.roll(p_j_posterior, a[1])def step(self):## Roll the dice on measuring sensory state y \in {0, 1} #. y =int(np.random.random() <self.sensory_dynamics[self.stil]) #.self.y = y #.## Pick action state, a \in {-1, 0, 1}^2 (pair of own and partner actions)## Calculate the free energy given my ## target (intent) distribution, current state distribution, & sensory input ## Do this for all (three) actions and select the action with minimum free energy. fes = [] epsilon =0.999+ np.random.random(3)*0.002## perturb values to randomize the action chosen if equal FEfor a in ACTIONS_SQUARED: pOwn =self.generative_density_own(a) #. pOth =self.generative_density_oth(a) #. fes.append([self.free_energy_own(a, pOwn, pOth)*epsilon[a[0]+1], #.# self.free_energy_oth(a, p_own, p_oth)]) #.self.free_energy_oth(a, pOwn, pOth)]) #. fes_t = np.transpose(fes) actions_index = [np.argmin(fes_t[0]), np.argmin(fes_t[1])] a = (ACTIONS_SQUARED[actions_index[0]][0], ACTIONS_SQUARED[actions_index[1]][1])self.a = a deltaPrime =self.delta + a[0] - a[1] #.## Update actual (own) position by taking action, partner action never gets realized stil = (self.stil + a[0]) % ENV_SIZE #.self.stil = stil #. pOwn =self.generative_density_own() #. pOth =self.generative_density_oth() #. sPrime = np.array([np.roll(self.s[0], a[0]), np.roll(self.s[1], a[1])]) #.## Minimise free energyfor step inrange(N_STEPS): sPrime -= LEARNING_RATE*self.fe_gradient(sPrime, np.roll(pOwn, a[0]), np.roll(pOth, a[1]), deltaPrime) #.## Save position, sensory output, and internal state for plottingself.s = sPrime #.self.q = (variational_density(sPrime[0]), variational_density(sPrime[1])) #.self.y_trace.append(y) #.self.a_trace.append(a[0])self.stil_trace.append(stil) #.self.stilOth_trace.append(stil -self.delta) #.self.sOwn_trace.append(model_encoding(sPrime[0])) #.self.sOth_trace.append(model_encoding(sPrime[1])) #.## Plot agent's internal state and position + agent's beliefs about partner's position #.def plot_traces(self, i): #.## Plot own belief trace fig1 = plt.figure(figsize=(15, 4)) ax = fig1.gca() im = ax.imshow(np.transpose(self.sOwn_trace), #. interpolation="nearest", aspect ="auto", vmin =0, vmax =1, cmap ="viridis") c = np.asarray(['white'if y==1else'grey'for y inself.y_trace]) #. stil = np.asarray(self.stil_trace) #. epochs = np.arange(EPOCHS +1)self.a_trace.append(0) a = np.asarray(self.a_trace) idx = a<0 ax.scatter(epochs[idx], stil[idx], c=c[idx], marker='v') #. idx = a>0 ax.scatter(epochs[idx], stil[idx], c=c[idx], marker='^') #. idx = a==0 ax.scatter(epochs[idx], stil[idx], c=c[idx], marker='o') #. ax.invert_yaxis() ax.set_xlim([0, EPOCHS +1]) fig1.colorbar(im) ax.set_title(f"Agent{i}: own belief trace") #. ax.set_xlabel(f"steps") #. ax.set_ylabel(f"position") #.## Then plot oth belief trace #. fig2 = plt.figure(figsize=(15, 4)) ax = fig2.gca() im = ax.imshow(np.transpose(self.sOth_trace), #. interpolation="nearest", aspect ="auto", vmin =0, vmax =1, cmap ="viridis") ax.invert_yaxis() ax.set_xlim([0, EPOCHS +1]) fig2.colorbar(im) ax.set_title(f"Agent{i}: oth belief trace") #. ax.set_xlabel(f"steps") #. ax.set_ylabel(f"position") #.return fig1, fig2## Calculate absolute distance from target position #.def log_convergence(self, targets): stil = np.array(self.stil_trace) #. c0 = np.minimum(np.abs(stil - targets[0]), #. np.minimum(np.abs(stil - targets[0] - ENV_SIZE), np.abs(stil - targets[0] + ENV_SIZE)))iflen(targets) ==1:return'shared target', c0 c1 = np.minimum(np.abs(stil - targets[1]), np.minimum(np.abs(stil - targets[1] - ENV_SIZE), np.abs(stil - targets[1] + ENV_SIZE)))## return the convergent distance from closest targetif c0[-1] <= c1[-1]:return'shared target', c0else:return'unshared target', c1
## Functions for capturing run datadef targetData(dft1, dft2):## collate target data and calculate % time agents pursue primary/secondary target dft1.columns = ['Target'] dft1['Agent'] ='strong' dft2.columns = ['Target'] dft2['Agent'] ='weak'return pd.concat([dft1, dft2], ignore_index=True)def convergenceData(dfc1, dfc2):## collate and plot convergence to target dfc1 = dfc1.melt() dfc1.columns = ["Time", "Distance from Target"] dfc1['Agent'] ='strong' dfc2 = dfc2.melt() dfc2.columns = ["Time", "Distance from Target"] dfc2['Agent'] ='weak'return pd.concat([dfc1, dfc2], ignore_index=True)def beliefData(dfb1, dfb2):## collate and plot final belief distribution (primary target fixed at the middle of the env.) dfb1 = dfb1.melt() dfb1.columns = ["Relative Location", "Belief"] dfb1['Agent'] ='strong' dfb2 = dfb2.melt() dfb2.columns = ["Relative Location", "Belief"] dfb2['Agent'] ='weak'return pd.concat([dfb1, dfb2], ignore_index=True)def systemFreeEnergyData(q_empirical):## Collate and plot FE based on distribution across all runs# global_p = initialize_s_star([0], 30) #. global_p = initialize_sPlus([0], 30) #. global_p = global_p/np.sum(global_p) fe = np.zeros(EPOCHS)for t inrange(EPOCHS): q = (q_empirical[t] +0.01)/(np.sum(q_empirical[t]) +0.01*ENV_SIZE) fe[t] = KL(q, global_p)return pd.DataFrame(fe, columns=['FE'])
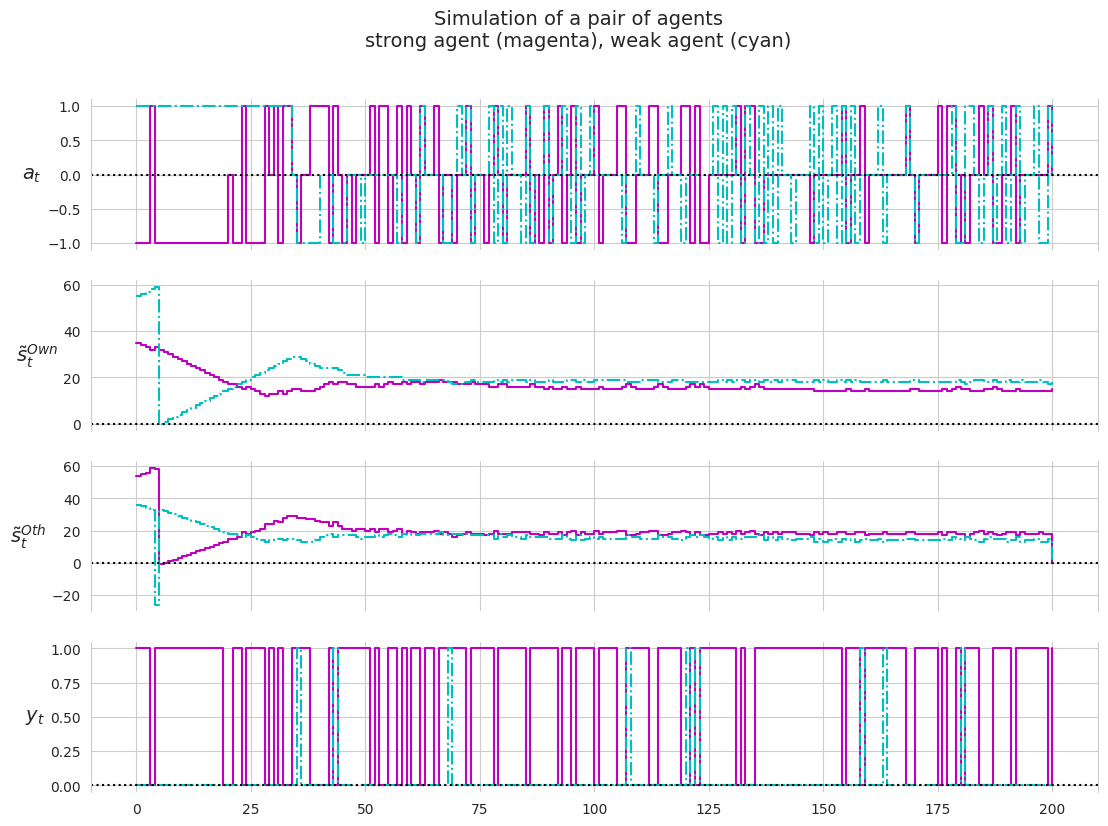
We do not have the ability to create policies based on inference yet. Nor do we make provision for simulation of collective bahavior yet. However, in this initial part of the project we will do a limited simulation consisting of a single run (making use of MODEL = 4) that will simulate the behavior of a single pair of agents.
## OVERIDES #.## Declarations## Environmental ConstantsENV_SIZE =60## note: pick a number divisible by 6SHORTEST_PATH =int(ENV_SIZE /3) ## distance of shared target from agent's initial positionTARGET_DELTA =int(ENV_SIZE /3) ## distance unshared target from shared target## Agent ConstantsACTIONS = (0, -1, 1) ## possible space of actions (stay, left, right)ACTIONS_SQUARED = ((0,0),(0,-1),(0,1), ## possible combined action space for 2 agents (-1,0),(-1,-1),(-1,1), (1,0),(1,-1),(1,1))MAX_SENSE_PROBABILITY = [0.99, 0.05] ## (strong, weak) agentsSENSE_DECAY_RATE = np.log(4)/ENV_SIZE ## omega (ensures p=0.5 at ENV/2)## Simulation parametersEPOCHS =200## Number of epochs (simulation steps).N_STEPS =50## Number of gradient descent steps made to update beliefs in each epoch.LEARNING_RATE =0.7## Stochastic gradient descent learning rate## Experimental parameters ## ALTERITY parameter for level of ToM (0, 1)## ALIGNMENT parameter for goal alignment (0, 1)CONDITIONS = {1: { 'model': 1, 'tom': [0, 0], 'gal': 0},2: { 'model': 2, 'tom': [0, 0.5], 'gal': 0},3: { 'model': 3, 'tom': [0, 0], 'gal': 1},4: { 'model': 4, 'tom': [0, 0.5], 'gal': 1}} #.
## single run## MODEL = 1 ## specify model you want to run #.## MODEL = 2 ## specify model you want to run #.## MODEL = 3 ## specify model you want to run #.MODEL =4## specify model you want to runFOOD_POSITION =15print(FOOD_POSITION)agents, t1, c1, s1, stil1, t2, c2, s2, stil2 = singleRun( #. FOOD_POSITION, ## shared_target #. MAX_SENSE_PROBABILITY, ## max_sense_prob CONDITIONS[MODEL]['tom'], ## theory-of-mind/alterity CONDITIONS[MODEL]['gal'], ## goal alignment #. plot=True)
15
## collect some traces for the strong agent in a dataframedf_strong = pd.DataFrame({'a': agents[0].a_trace,'stilOwn': agents[0].stil_trace,'stilOth': agents[0].stilOth_trace + [0],'y': agents[0].y_trace,})df_strong
a
stilOwn
stilOth
y
0
-1
35
54
1
1
-1
34
55
1
2
-1
33
56
1
3
1
32
59
0
4
-1
33
58
1
...
...
...
...
...
196
0
14
18
1
197
0
14
19
1
198
0
14
18
1
199
1
14
18
0
200
0
15
0
1
201 rows × 4 columns
## collect some traces for the weak agent in a dataframedf_weak = pd.DataFrame({'a': agents[1].a_trace,'stilOwn': agents[1].stil_trace,'stilOth': agents[1].stilOth_trace + [0],'y': agents[1].y_trace,})df_weak