In this project the client is a newly appointed district manager that is responsible for the optimal running of 4 retail stores in Washington state at the locations:
Bellingham
Ferndale
Lynden
Blaine
Symbols/Nomenclature/Notation (KUF)
[informed by Powell Universal Framework (PUF), Bert DeVries, AIF literature]
Taxonomy of Machine Learning
Supervised Learning (Regression, Classification)
next state function
next state starts with provision: aquisition of another state/datapoint
sequence of (ordered) correlated observations \(y\) (time/spatial)
Overall Structure
Experiment has one-to-many Batches
Batch (into the page) has one-to-many Sequences
Sequence (down the page) has one-to-many Datapoints
Datapoint (into the page) has one-to-many Matrices
Matrix (down the page) has one-to-many Vectors
Vector (towards right) has one-to-many Components
Component/Element of type
Numerical [continuous/proportional]
int/real/float (continuous)
Categorical [non-continuous/non-formal]
AIF calls it ‘discrete’
ordinal (ordered)
nominal (no order)
for computers, elements need to be numbers, so categoricals encoded as numbers too
Most complex Datapoint handled is a multispectral image, i.e. 3D
Generative Model
\(\mathbf{A}\): Observation matrix
\(\mathbf{B}\): Transition matrix
\(\mathbf{C}\): Preference matrix
\(\mathbf{D}\): Initial state matrix
\(\mathbf{E}\): Behavior matrix
0 Active Inference: Bridging Minds and Machines
In recent years, the landscape of machine learning has undergone a profound transformation with the emergence of active inference, a novel paradigm that draws inspiration from the principles of biological systems to inform intelligent decision-making processes. Unlike traditional approaches to machine learning, which often passively receive data and adjust internal parameters to optimize performance, active inference represents a dynamic and interactive framework where agents actively engage with their environment to gather information and make decisions in real-time.
At its core, active inference is rooted in the notion of agents as embodied entities situated within their environments, constantly interacting with and influencing their surroundings. This perspective mirrors the fundamental processes observed in living organisms, where perception, action, and cognition are deeply intertwined to facilitate adaptive behavior. By leveraging this holistic view of intelligence, active inference offers a unified framework that seamlessly integrates perception, decision-making, and action, thereby enabling agents to navigate complex and uncertain environments more effectively.
One of the defining features of active inference is its emphasis on the active acquisition of information. Rather than waiting passively for sensory inputs, agents proactively select actions that are expected to yield the most informative outcomes, thus guiding their interactions with the environment. This active exploration not only enables agents to reduce uncertainty and make more informed decisions but also allows them to actively shape their environments to better suit their goals and objectives.
Furthermore, active inference places a strong emphasis on the hierarchical organization of decision-making processes, recognizing that complex behaviors often emerge from the interaction of multiple levels of abstraction. At each level, agents engage in a continuous cycle of prediction, inference, and action, where higher-level representations guide lower-level processes while simultaneously being refined and updated based on incoming sensory information.
The applications of active inference span a wide range of domains, including robotics, autonomous systems, neuroscience, and cognitive science. In robotics, active inference offers a promising approach for developing robots that can adapt and learn in real-time, even in unpredictable and dynamic environments. In neuroscience and cognitive science, active inference provides a theoretical framework for understanding the computational principles underlying perception, action, and decision-making in biological systems.
In conclusion, active inference represents a paradigm shift in machine learning, offering a principled and unified framework for understanding and implementing intelligent behavior in artificial systems. By drawing inspiration from the principles of biological systems, active inference holds the promise of revolutionizing our approach to building intelligent machines and understanding the nature of intelligence itself.
1 BUSINESS UNDERSTANDING
In this project the client is a newly appointed district manager that is responsible for the optimal running of 4 retail stores in Washington state at the locations:
Bellingham
Ferndale
Lynden
Blaine
His engagement with each of these branches will happen in terms of full weeks. The decision to engage with a specific store is up to the district manager. What is expected is for the district manager to engage with a store and to help improve and optimize operations. From past engagement data it is not clear how engagements decisions were made. Sometimes they appear to be random. There are also quick changes rather than longer running engagements, likely to put out sudden fires. The client wants to minimize the effect of his appointment to the role and would like, at least for a while, to follow the past pattern of engagements as closely as possible.
This analysis will make use of Bayesian inference within the larger scope of an approach known as Active Inference. In particular, the past manager engagements will be modeled as a Hidden Markov Model. This model can then be used by the client for suggestions on how to engage with the stores.
versioninfo() ## Julia version
Julia Version 1.11.1
Commit 8f5b7ca12ad (2024-10-16 10:53 UTC)
Build Info:
Official https://julialang.org/ release
Platform Info:
OS: Linux (x86_64-linux-gnu)
CPU: 12 × Intel(R) Core(TM) i7-8700B CPU @ 3.20GHz
WORD_SIZE: 64
LLVM: libLLVM-16.0.6 (ORCJIT, skylake)
Threads: 1 default, 0 interactive, 1 GC (on 12 virtual cores)
Environment:
JULIA_NUM_THREADS =
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Resolving package versions...
No Changes to `~/.julia/environments/v1.11/Project.toml`
No Changes to `~/.julia/environments/v1.11/Manifest.toml`
Pkg.status()
Status `~/.julia/environments/v1.11/Project.toml`
[6e4b80f9] BenchmarkTools v1.5.0
[a93c6f00] DataFrames v1.7.0
[31c24e10] Distributions v0.25.113
[b964fa9f] LaTeXStrings v1.4.0
⌃ [91a5bcdd] Plots v1.40.8
[54e16d92] PrettyPrinting v0.4.2
[86711068] RxInfer v3.7.1
[fdbf4ff8] XLSX v0.10.4
[9a3f8284] Random v1.11.0
Info Packages marked with ⌃ have new versions available and may be upgradable.
2 DATA UNDERSTANDING
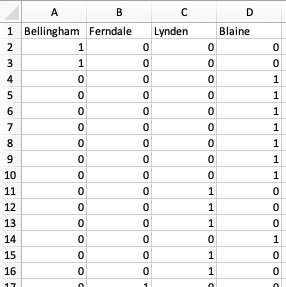
The historical data spans a period of 9 years’ worth of weekly engagement data. Each weekly record consists of a 1-hot encoded engagement state vector. When the associated component of the state vector is a 1, the district manager was engaged with the associated store:
ManagerEngagements_states
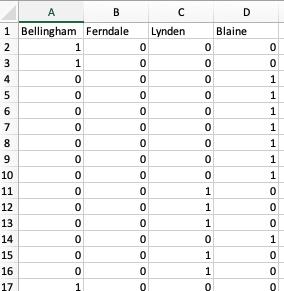
Similarly, we also have the observation vectors for each week:
ManagerEngagements_observations
The observations do not always agree with the states due to administrative errors. For example, a district manager might have failed to capture a specific engagement and eventually the capture was done with a misremenbered date.
3 DATA PREPARATION
We will use the data from the simulator and from the field directly. There is no need to perform additional data preparation.
4 MODELING
4.1 Narrative
Please review the narrative in section 1.
4.2 Core Elements
This section attempts to answer three important questions:
What metrics are we going to track?
What decisions do we intend to make?
What are the sources of uncertainty?
The only metric we are interested in is the engagement store of the district manager, i.e. at which of the 4 stores the manager is working for the week.
There are no control/steering decisions to be made. We are simply interested in understanding and modeling the past engagement behavior.
There are two sources of uncertainty. The first has to do with the fact that the state transitions are not deterministic but rather stochastic. This will be captured in the transition matrix \(\mathbf B\). The second relates to observations. Engagements were not always recorded accurately. This means observations of past engagements sometimes differ from what they really were. This uncertainty will be captured in the observation matrix \(\mathbf A\).
4.3 Environment Model (Generative Process)
To get insight into the engagement behavior, we need to formulate a model. Since we have a finite (and small number of) stores, we can use a categorical distribution to represent the district manager’s engagement. There are four stores which means we will have four distinct values with associated probabilities in the categorical distribution. For time we will use \(t\). The state of the engagement at time \(t\) will be indicated by \(\mathbf{s}_t\). The associated observation will be indicated by \(\mathbf{y}_t\).
The probabilities for switching between stores will be captured in a transition matrix \(\mathbf{B}\). To test our approach we will assign these probabilities manually in a simulation and then see to what extent the model can learn these. From the past data it appears that transition probabilities can vary quite a bit. Once we are confident in our approach we will use the past data from the field to learn the transition probabilities without a reference to compare them against.
We will also learn the observation matrix \(\mathbf{A}\) which reflects how well observations of the true state were made. At time \(t\), the observation will be indicated by \(\mathbf{y}_t\). The observation matrix encodes the likelihood that the record of an engagement was a mistake so that a wrong observation is made. The model may be specified as follows:
This type of discrete state space model is known as a Hidden Markov Model (HMM). In summary, our goal is to learn the matrices \(\mathbf{B}\) and \(\mathbf{A}\) so we can use them to understand the past engagement behavior of district managers.
"""Returns a one-hot encoding of a random sample from a categorical distribution. The sample is drawn with the `rng` random number generator."""functionrand_1hot_vec(rng, distribution::Categorical) k =ncategories(distribution) s =zeros(k) drawn_category =rand(rng, distribution) s[drawn_category] =1.0return send
rand_1hot_vec
4.3.1 State variables
The state variables represent what we need to know. These are captured in a state vector \(\mathbf{s}_t\).
4.3.2 Decision variables
There are no decisions to be made. We are simply observing the past behavior of district manager engagements, i.e. there is no control/steering applied to the engagement environment.
4.3.3 Exogenous information variables
There are no exogenous information variables.
4.3.4 Next State function
The provision function, \(f_p()\), provides another state/datapoint, called the provision/pre-state. Because this is a sequential system, the provision function transitions to the next state/datapoint from the previous state making use of a simulation or a data set.
The breve/bowls indicate that the parameters and variables are hidden and not observed.
4.3.5 Observation function
The response function, \(f_r()\), provides the response to the state/datapoint, called the response: \[\mathbf{r}_{t} = f_{r}(\breve{\mathbf{s}}_{t}) = f_A(\breve{\mathbf{s}}_{t}) = \mathbf{\breve{A}} \breve{\mathbf{s}}_{t}\]
## response function, provides the response to a state/datapointfunctionfᵣ(s̆, Ă, rng) odis_t =Ă*first(first(s̆)) o_t =rand_1hot_vec(rng, Categorical(odis_t))return [[o_t]]end_Ăˢⁱᵐ = [0.940.020.020.02;0.020.940.020.02;0.020.020.940.02;0.020.020.020.94]fᵣ(_s̆, _Ăˢⁱᵐ, _rng)
To simulate the engagement behavior, we need to specify:
the actual transition probabilities between the states (how likely is the manager to move from one store to another)
the observation probabilities (i.e., how reliably will engagements be captured)
These specifications will allow us to generate observations from the hidden Markov model (HMM).
Here are the steps to generate observation data:
Assume an initial engagement state (store) for the district manager. We will have the initial engagement at Bellingham.
Determine where the manager went next by drawing from a Categorical distribution with the transition probabilities between the different stores.
Determine the observation encountered in the capture records by drawing from a Categorical distribution with the corresponding observation probabilities.
Repeat steps 2 and 3 for as many samples as needed.
The following code implements the above process and generates our simulated observation data:
## Data comes from either a simulation/lab (sim|lab) OR from the field (fld)## Data are handled either in batches (batch) OR online as individual points (point)functionsim_data(rng, 𝚂, 𝙳, 𝙼, 𝚅, 𝙲, B̆, Ă, s₀) p =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂) s̆ =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂) r =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂) y =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂)for s in1:𝚂 ## Sequences p[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) s̆[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) r[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) y[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) s̆ₜ₋₁ = s₀ ## keep previous statefor d in1:𝙳 ## Datapoints p[s][d] =fˢⁱᵐₚ(s̆ₜ₋₁; B̆=B̆, 𝙼=𝙼, 𝚅=𝚅, 𝙲=𝙲, rng=rng) s̆[s][d] = p[s][d] ## no system noise r[s][d] =fᵣ(s̆[s][d], Ă, rng) y[s][d] = r[s][d] s̆ₜ₋₁ = s̆[s][d]endendreturn y, s̆end;## Not used because the state is not availablefunctionfld_data(df, 𝚂, 𝙳, 𝙼, 𝚅, 𝙲) p =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂) s̆ =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂) r =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂) y =Vector{Vector{Vector{Vector{Vector{Float64}}}}}(undef, 𝚂)for s in1:𝚂 ## Sequences p[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) s̆[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) r[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳) y[s] =Vector{Vector{Vector{Vector{Float64}}}}(undef, 𝙳)for d in1:𝙳 ## Datapoints## p[s][d] = fᶠˡᵈₚ(d; 𝙼=𝙼, 𝚅=𝚅, 𝙲=𝙲, df=df)## s̆[s][d] = p[s][d] ## no system noise## r[s][d] = fᵣ(s̆[s][d])## y[s][d] = r[s][d] y[s][d] = [[Vector(df[d, :])]]endendreturn yend;
Next we will generate a number of weekly data points to simulate engagements. xSim will contain the measurements (capture records) and sSim will contain information on the actual engagements.
## number of Batches in an experiment## _𝙱 = 1 ## not used yet## number of Sequences/examples in a batch_𝚂 =1## number of Datapoints in a sequence# _𝙳 = 600# _𝙳 = 700# _𝙳 = 1000# _𝙳 = 1500 #usable# _𝙳 = 1600 #better# _𝙳 = 1700 #worse# _𝙳 = 2000 #worse_𝙳 =1600#better## number of Matrices in a datapoint_𝙼 =1## number of Vectors in a matrix_𝚅 =1## number of Components in a vector_𝙲 =4_B̆ˢⁱᵐ = [0.900.050.100.05;0.000.850.050.00;0.050.050.800.05;0.050.050.050.90]_Ăˢⁱᵐ = [0.940.020.020.02;0.020.940.020.02;0.020.020.940.02;0.020.020.020.94]_s₀ = [[[1.0, 0.0, 0.0, 0.0]]] ## initial state_seed =42_rng =MersenneTwister(_seed)
The uncertainty model is captured in the transition matrix \(\mathbf{B}\) and the observation matrix \(\mathbf{A}\).
4.5 Agent Model (Generative Model)
4.5.1 Implementation of the Agent Model (Generative Model)
We will use the RxInfer Julia package. RxInfer stands at the forefront of Bayesian inference tools within the Julia ecosystem, offering a powerful and versatile platform for probabilistic modeling and analysis. Built upon the robust foundation of the Julia programming language, RxInfer provides researchers, data scientists, and practitioners with a streamlined workflow for conducting Bayesian inference tasks with unprecedented speed and efficiency.
At its core, RxInfer leverages cutting-edge techniques from the realm of reactive programming to enable dynamic and interactive model specification and estimation. This unique approach empowers users to define complex probabilistic models with ease, seamlessly integrating prior knowledge, data, and domain expertise into the modeling process.
With RxInfer, conducting Bayesian inference tasks becomes a seamless and intuitive experience. The package offers a rich set of tools for performing parameter estimation, model comparison, and uncertainty quantification, all while leveraging the high-performance capabilities of Julia to deliver results in a fraction of the time required by traditional methods.
Whether tackling problems in machine learning, statistics, finance, or any other field where uncertainty reigns supreme, RxInfer equips users with the tools they need to extract meaningful insights from their data and make informed decisions with confidence.
RxInfer represents a paradigm shift in the world of Bayesian inference, combining the expressive power of Julia with the flexibility of reactive programming to deliver a state-of-the-art toolkit for probabilistic modeling and analysis. With its focus on speed, simplicity, and scalability, RxInfer is poised to become an indispensable tool for researchers and practitioners seeking to harness the power of Bayesian methods in their work.
To configure the model in RxInfer, we will use Categorical distributions for the states and observations. To learn the \(B\) and \(A\) matrices we can use MatrixDirichlet priors. Since we have no apriori idea how the engagements will play out we will assume that it happens randomly. For the \(\mathbf{B}\)-matrix, we can represent this by filling our MatrixDirichlet prior on \(\mathbf{B}\) with all ones. These values will get updated once learning starts.
For the observations, it is reasonable to assume that record keeping for engagements are very accurate. To configure this, we will have large values on the diagonal of \(\mathbf{A}\)’s prior. However, to allow for the odd errors in record keeping, we will add some noise on the off-diagonal entries.
We will use Variational Inference. This means we will have to specify inference constraints. Using a structured variational approximation to the true posterior distribution, we will decouple the variational posterior over the states (q(s_0, s)) from the posteriors over the transition matrices (q(B) and q(A)). This dependency decoupling in the approximate posterior distribution ensures that inference is tractable.
Next, we specify this model in RxInfer. We will make use of the following nodes in the Forney Factor Graph (FFG):
MatrixDirichlet
Categorical
Transition
Kronecker-\(\delta\) nodes (for the N observations)
## Model specification@modelfunctionhidden_markov_model(x, N) B ~MatrixDirichlet(ones(4, 4)) ## transition matrix A ~MatrixDirichlet([10.01.01.01.0; ## observation matrix1.010.01.01.0; 1.01.010.01.0;1.01.01.010.0]) s₀ ~Categorical(fill(1.0/4.0, 4)) ## initial state## s = randomvar(N)## x = datavar(Vector{Float64}, N) sₜ₋₁ = s₀ ## initialize the previous statefor t in1:N s[t] ~Transition(sₜ₋₁, B) x[t] ~Transition(s[t], A) sₜ₋₁ = s[t] ## keep the previous stateendend## Constraints specification@constraintsfunctionhidden_markov_model_constraints()q(s₀, s, B, A) =q(s₀, s)q(B)q(A)end
hidden_markov_model_constraints (generic function with 1 method)
4.6 Agent Evaluation
Next we will perform inference to see how engagements changed.
Using Variational Inference to perform inference, means we need to set some initial marginals as a starting point. This is made easy in RxInfer by using the vague function, which provides an uninformative guess. Different initial guesses can also be tried.
We are only interested in the final result - the best guess about the engagement store. So we will only keep the last results.
We obtain the estimated posteriors for \(\mathbf{B}\) and \(\mathbf{A}\). Then we compare them with the \(\mathbf{B}\) and \(\mathbf{A}\) matrices we setup for the simulation. For both matrices the estimates are quite good. This gives us confidence that we might get useful results for the field data as well.
println("Posterior Marginal for B:")_Bˢⁱᵐ =mean(_resultSim.posteriors[:B])
Next we visualize the results by comparing the real states with the inferred states. We also verify if the model has converged by looking at the Free Energy.
Now it is time to evaluate the agent/model with the historical field data. There are 468 weekly records. So 468 weeks = 9 years * 52 weeks/year.
_yᶠˡᵈ_df =DataFrame(XLSX.readtable("ManagerEngagements_observations.xlsx", "Sheet1"));_yᶠˡᵈ_mat =Float64.(Matrix(_yᶠˡᵈ_df))_yᶠˡᵈ = [_yᶠˡᵈ_mat[r,1:end] for r in1:size(_yᶠˡᵈ_mat)[1]]## Not used because the state is not available:## _yᶠˡᵈ = fld_data(_yᶠˡᵈ_df, _𝚂, _𝙳, _𝙼, _𝚅, _𝙲) ## field data## _yᶠˡᵈ = _yᶠˡᵈ[1] ## first (and only) sequence## _yᶠˡᵈ = first.(first.(_yᶠˡᵈ));## pprint(IOContext(stdout, :displaysize => (24, 30)), _yᶠˡᵈ)
_s̆ᶠˡᵈ_df =DataFrame(XLSX.readtable("ManagerEngagements_states.xlsx", "Sheet1"));_s̆ᶠˡᵈ_mat =Float64.(Matrix(_s̆ᶠˡᵈ_df))_s̆ᶠˡᵈ = [_s̆ᶠˡᵈ_mat[r,1:end] for r in1:size(_s̆ᶠˡᵈ_mat)[1]]
The model showed good conversion based on the free energy. However, we have less data for the agent to learn from (468 data points) than we had in the case of the simulation (1,600 data points). Our field agent model will probably be not as good as the simulation agent. We also do not have access to the \(\mathbf{B}\) and \(\mathbf{A}\) matrices that generated the field data. However, we do take comfort in the good declining behavior of the free energy chart.
Let’s look at the matrices (here rounded to 2 decimal places):
Consider the \(\mathbf{B}\) matrix and assume the manager is currently engaged at the Lynden store. This means there is a 75% probability that he will still be at this store next week, a 13% probability that he will move to the Bellingham store, a 5% probability that he will move to the Ferndal store, and a 7% probability that he will move to the Blaine store next week. Sampling the categorical distribution of each store and changing engagement accordingly will ensure that the district manager’s engagement behavior is consistent with past engagement behavior.