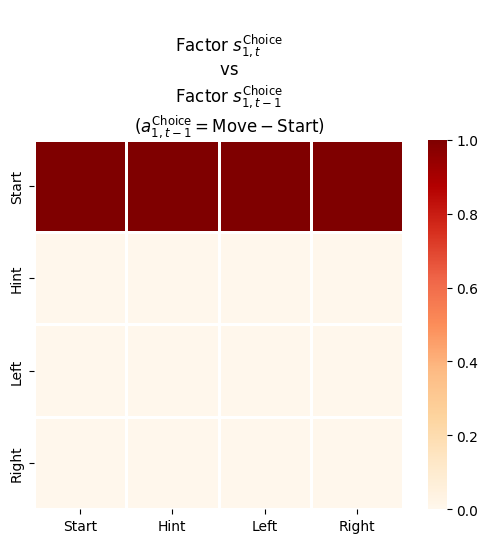
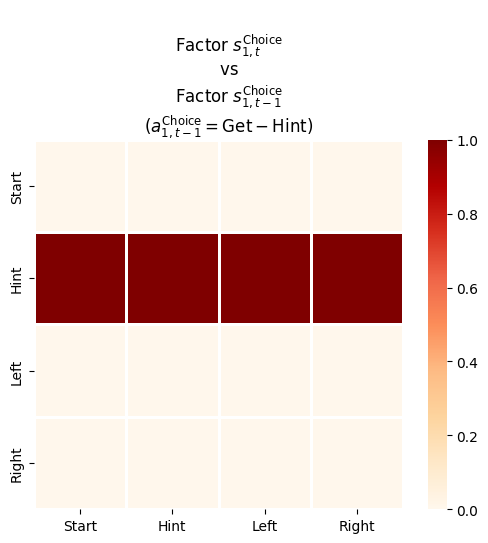
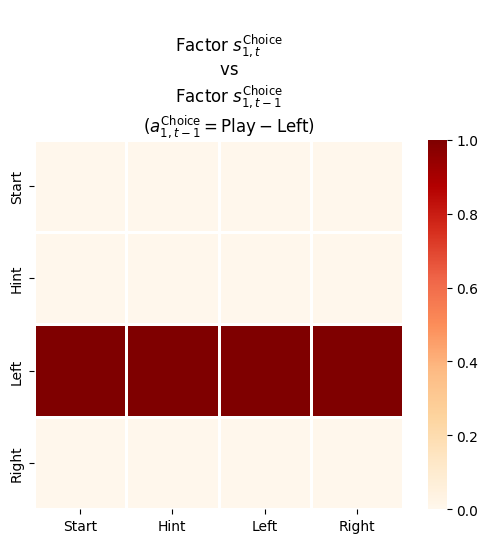
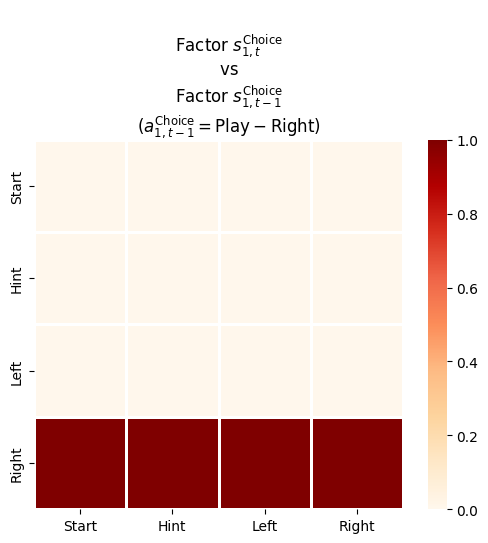
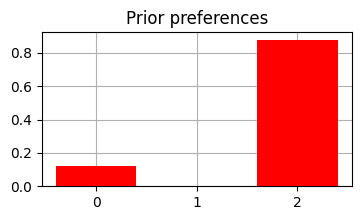
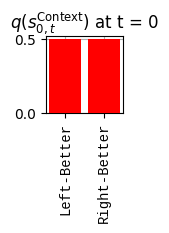
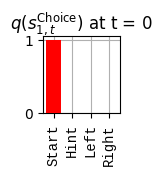
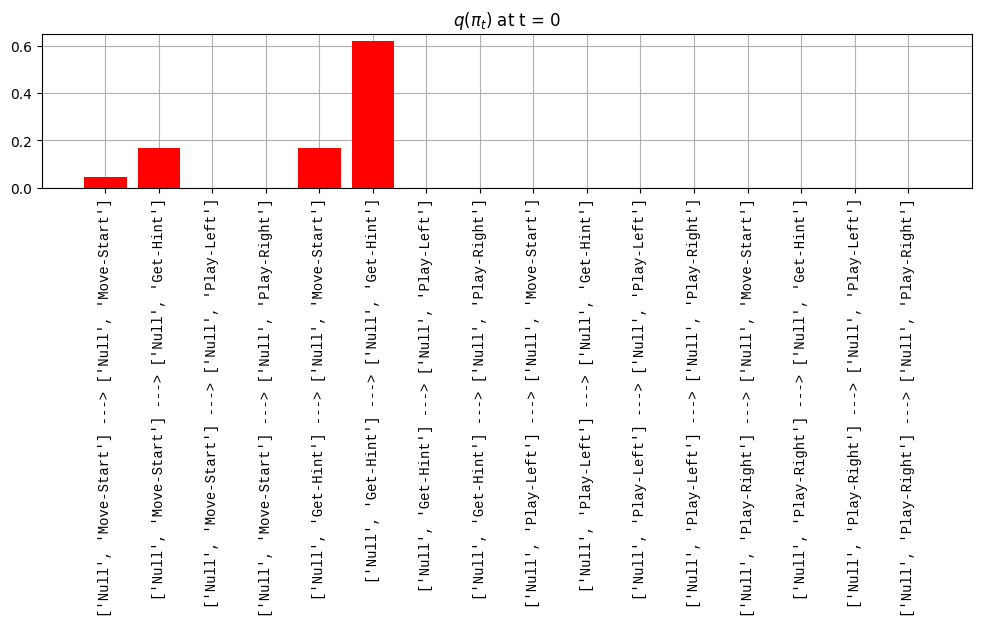
In this project we refactor one of the PyMDP examples to serve as a baseline for a future client project. Here are some of the changes:
add a lookup table _lup to lookup a value/level
label, given the index
index, given the label
use zero-based factors and modalities to align better with Python’s convention
plot variables against time
add get_policy_labels(policies) to provide text tick labels (rather than indexes) in distribution bar plots
A few coding conventions:
Global variable names usually start with an underscore, i.e. _
This notebook follows a standardized framework. This is my own framework, developed over a number of years, and is informed by the CRISP-DM framework, the work of Warren Powell (Princeton), the work of Bert De Vries, the work of Karl Friston as well as that of the larger Active Inference community.
Python 3.10.12
inferactively-pymdp 0.0.7.1
[notice] A new release of pip is available: 23.0.1 -> 25.1
[notice] To update, run: pip install --upgrade pip
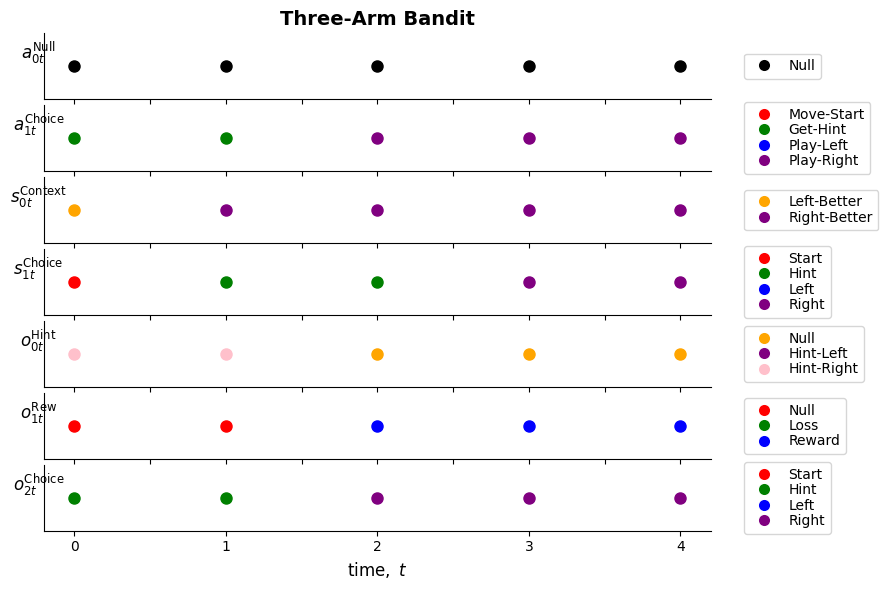
import numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport pymdpfrom pymdp import utilsfrom pymdp.agent import Agentimport matplotlib.pyplot as pltfrom matplotlib.gridspec import GridSpecfrom matplotlib.lines import Line2Dfrom matplotlib.ticker import MaxNLocatorimport math
Define some utilities
def plot_likelihood( matrix, ## conditional distribution title_str="Likelihood distribution (A)", xlabels=None, ylabels=None, size=None): """ Plots a 2-D likelihood matrix as a heatmap """ifnot np.isclose(matrix.sum(axis=0), 1.0).all():raiseValueError("Distribution not column-normalized! Please normalize (ensure matrix.sum(axis=0) == 1.0 for all columns)")if size ==None: fig = plt.figure(figsize = (5,5))else: fig = plt.figure(figsize = size)## fig = plt.figure(figsize = (6,6)) fig = plt.figure(figsize = size)if ylabels ==Noneand xlabels ==None: sns.heatmap( matrix, cmap='OrRd', linewidths=1, cbar=True, vmin=0.0, vmax=1.0)else: ax = sns.heatmap( matrix, xticklabels = xlabels, yticklabels = ylabels, ## cmap = 'gray', cmap ="OrRd", linewidths=1, cbar =True, square=True, vmin =0.0, vmax =1.0) plt.title(title_str) plt.show()def plot_beliefs( vector, ## belief distribution title_str="", xlabels=None, size=None): """ Plot a categorical distribution or belief distribution, stored in the 1-D numpy vector `vector` """ifnot np.isclose(vector.sum(), 1.0):raiseValueError("Distribution not normalized! Please normalize")if size ==None: fig = plt.figure(figsize = (1,1))else: fig = plt.figure(figsize = size) plt.grid(zorder=0) plt.bar(range(vector.shape[0]), vector, color='r', zorder=3)if xlabels ==None: plt.xticks(range(vector.shape[0]))else:##+ plt.xticks(range(len(xlabels)), xlabels, rotation='vertical', fontname='DejaVu Sans Mono') ##.fixed-width font plt.xticks(range(len(xlabels)), xlabels, rotation='vertical', fontname='Liberation Mono') ##.fixed-width font plt.title(title_str) plt.show()def plot_efe( vector, title_str="", xlabels=None, size=None): if size ==None: fig = plt.figure(figsize = (1,1))else: fig = plt.figure(figsize = size) plt.grid(zorder=0) plt.bar(range(vector.shape[0]), vector, color='r', zorder=3)if xlabels ==None: plt.xticks(range(vector.shape[0]))else: plt.xticks(range(len(xlabels)), xlabels, rotation='vertical') plt.title(title_str) plt.show()_lup = { ## lookup between indexes & labels## control/action factors"aNull_0": [ 'Null'], ## 'Null'; s_0 uncontrollable"aChoice_1": ['Move-Start', 'Get-Hint', 'Play-Left', 'Play-Right'],## state factors"sContext_0": [ ## uncontrollable (exog info)'Left-Better', 'Right-Better'],"sChoice_1": ['Start', 'Hint', 'Left', 'Right'],"s̆Context_0": [ ## uncontrollable (exog info)'Left-Better', 'Right-Better'],"s̆Choice_1": ['Start', 'Hint', 'Left', 'Right'],## observation modalities"oHint_0": ['Null', ## Hint not played'Hint-Left', ## Hint said left'Hint-Right'## Hint said right ],"oRew_1": ['Null', 'Loss', 'Reward'],"oChoice_2": ['Start', ## Move-start played'Hint', ## Get-hint played'Left', ## Play-left played'Right'## Play-right played ],}
1 BUSINESS UNDERSTANDING
The current problem involves an explore/exploit task with an epistemic two-armed bandit. The multi-armed bandit (or MAB) is a classic decision-making task that captures the core features of the “explore/exploit tradeoff”. The multi-armed bandit formulation is ubiquitous across problem spaces that require sequential decision-making under uncertainty – this includes disciplines ranging from economics, neuroscience, machine learning, engineering all the way to advertising.
In the standard MAB problem formulation, an agent must choose between mutually-exclusive alternatives (also known as ‘arms’) in order to maximize reward over time. The probability of reward depends on which arm the agent chooses. A common real-world analogy for a MAB problem is imagining a special slot machine with three possible levers to pull (rather than the usual one), where playing each lever has different probabilities of payoff (e.g. getting a winning combination of symbols or bonus). In fact, the ‘standard’ slot machine, which usually only has one lever, was historically referred to as a ‘one-armed bandit’ – this was the direct ancestor of the name for the generic machine learning / decision-making problem class, the MAB.
Crucially, MAB problems are interesting and difficult because in general, the reward statistics of each arm are unknown or only partially known. In a probabilistic or Bayesian context, an agent must therefore act based on beliefs about the reward statistics, since they don’t have perfect access to this information.
The inherent partial-observability of the task creates a conflict between exploitation or choosing the arm that is currently believed to be most rewarding, and exploration or gathering information about the remaining arms, in the hopes of discovering a potentially more rewarding option.
The fact that expected reward or utility is contextualized by beliefs – i.e. which arm is currently thought to be the most rewarding – motivates the use of active inference in this context. This is because the key objective function for action-selection, the expected free energy \(\mathbf{G}\), depends on the agent’s beliefs about the world. And not only that, but expected free energy balances the desire to maximize rewards with the drive to resolve uncertainty about unknown parts of the agent’s model. The more accurate the agent’s beliefs are, the more faithfully decision-making can be guided by maximizing expected utility or rewards.
MAB with an epistemic twist
In the MAB formulation we’ll be exploring in this problem, the agent must choose to play among two possible arms, each of which has unknown reward statistics. These reward statistics take the form of Bernoulli distributions over two possible reward outcomes: “Loss” and “Reward”. However, one of the arms has probability \(p\) of yielding “Reward”” and probabiliity \((1-p)\) of yielding “Loss”. The other arm has swapped statistics. In this example, the agent knows that the bandit has this general reward structure, except they don’t know which of the two arms is the rewarding one (the arm where reward probability is \(p\), assuming \(p \in [0.5, 1]\)).
However, we introduce an additional feature in the environment, that induces an explicit trade-off in decision-making between exploration (information-seeking) and exploitation (reward-seeking). In this special “epistemic bandit” problem, there is an additional action available to the agent, besides playing the two arms. We call this third action “Get Hint”, and allows the agent to acquire information that reveals (potentially probabilistically) which arm is the more rewarding one. There is a trade-off here, because by choosing to acquire the hint, the agent forgoes the possibility of playing an arm and thus the possibility of getting a reward at that moment. The mutual exclusivity of hint-acquisition and arm-playing imbues the system with an explore/exploit trade-off, which active inference is particularly equipped to handle, when compared to simple reinforcement learning schemes (e.g. epsilon-greedy reward maximization).
##. Visualize: 3 levers, button in the center (Move-Start) ## Play-Left Play-Right## Move-Start## Get-Hint
2 DATA UNDERSTANDING
There is no pre-existing data to be analyzed.
3 DATA PREPARATION
There is no pre-existing data to be prepared.
4 MODELING
4.1 Narrative
Please review the narrative in section 1.
4.2 Core Elements
This section attempts to answer three important questions:
What metrics are we going to track?
What decisions do we intend to make?
What are the sources of uncertainty?
For this problem, the main metric we are interested in is the probability of observing a Reward. In addition, we want to keep track of what the hint lever reveals as well as the choices played by the agent.
The only source of uncertainty is which lever is more profitable to play: left or right.
4.3 System-Under-Steer / Environment / Generative Process
4.3.1 State variables
The state at time \(t\) of the system-under-steer/environment (envir) is given by
\[
\begin{aligned}
\breve{\mathbf{s}}_t &= (\breve{s}^{\mathrm{Context}}_{0,t}, \breve{s}^{\mathrm{Choice}}_{1,t})
\end{aligned}
\] where
The environment is steered by decisions/actions \(\mathbf{a}_t\). Each component of this vector is called a control factor or control state factor. The action at time \(t\) is given by
\[
\begin{aligned}
\breve{\mathbf{a}}_t &= (a^{\mathrm{Null}}_{0,t}, a^{\mathrm{Choice}}_{1,t})
\end{aligned}
\] where
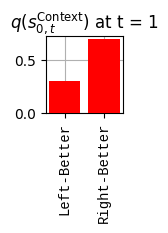
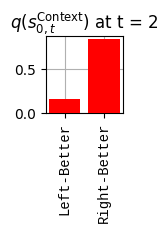
The exogenous information is not controllable by the agent. It is captured in the state factor \[\breve{s}^{\mathrm{Context}}_{0,t} \in \{\text{Left-Better}, \text{Right-Better}\}\]
4.3.4 Next State
To find the next state for each time step, the generative process starts with the transition function\(f\). To this is added exogenous information and system noise to arrive at the next state.
4.3.5 Observation
To find the observation generated by the external state of the generative process for each time step, the generative process starts with the generating function\(g\). To this is added observation or measurement noise to arrive at the observation.
4.3.6 Implementation of the System-Under-Steer / Environment / Generative Process
We assume that the reality of the generative process is given by the following implementation:
According to the agent the state of the system-under-steer/environment/generative process will be \(\mathbf{s}_t\), rather than \(\mathbf{\breve s}_t\). It is given by
\[
\begin{aligned}
\mathbf{s}_t &= (s^{\mathrm{Context}}_{0,t}, s^{\mathrm{Choice}}_{1,t})
\end{aligned}
\] where
According to the agent the action on the environment at time \(t\) will be represented by \(\mathbf{u}_t\), also known as the control state of the agent.
4.5.3 Implementation of the Agent / Generative Model / Internal Model
4.5.3.1 Observation likelihood matrix, \(\mathbf A\) or \(P(o_t\mid s_t)\)
print(_s_dims)print(_o_dims)
[2, 4]
[3, 3, 4]
_A_shapes = [[o_dim] + _s_dims for o_dim in _o_dims]_A_shapes
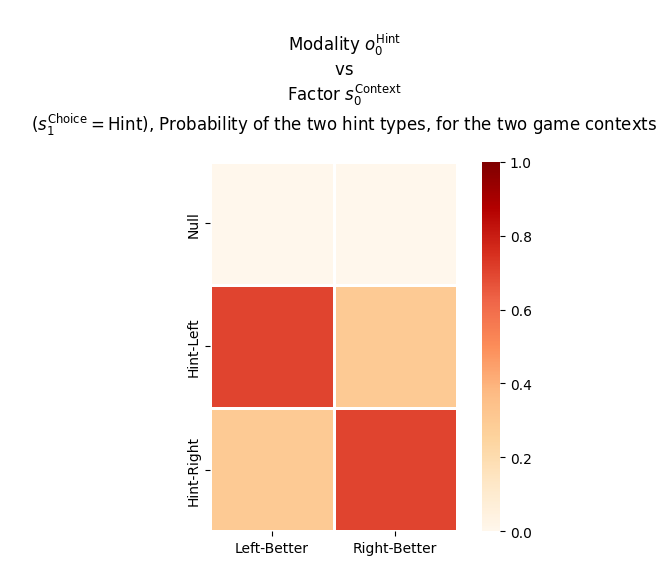
plot_likelihood( _A[0][:,:,1], title_str=""" Modality $o^{\mathrm{Hint}}_0$ vs Factor $s^{\mathrm{Context}}_0$ ($s^{\mathrm{Choice}}_1=\mathrm{Hint}$), Probability of the two hint types, for the two game contexts """, ylabels=_lup['oHint_0'], xlabels=_lup['sContext_0'])## look at cuboid & see slice## lift slice up and roll backwards## look at slice from left## now original cuboid rows increase left-to-right## and original cuboid mats increase from top-to-bottom (depth)
<Figure size 500x500 with 0 Axes>
4.5.3.1.2 Modality \(o^{\mathrm{Rew}}_1\)
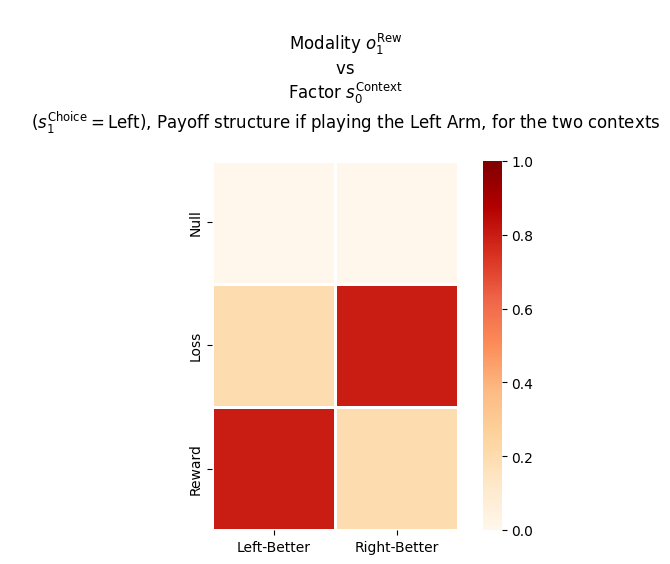
_p_reward =0.8## probability of getting a rewarding outcome, if you are sampling the more rewarding banditfor s1_idx, s1_nam inenumerate(_lup['sChoice_1']):if s1_nam =='Start': _A[1][0, :, s1_idx] =1.0elif s1_nam =='Hint': _A[1][0, :, s1_idx] =1.0elif s1_nam =='Left': _A[1][1:, :, s1_idx] = np.array([ [1.0-_p_reward, _p_reward], [_p_reward, 1.0-_p_reward] ])elif s1_nam =='Right': _A[1][1:, :, s1_idx] = np.array([ [ _p_reward, 1.0- _p_reward], [1-_p_reward, _p_reward] ])_A[1]## 3 matrices of 2x4
plot_likelihood( _A[1][:,:,2], title_str=""" Modality $o^{\mathrm{Rew}}_1$ vs Factor $s^{\mathrm{Context}}_0$ ($s^{\mathrm{Choice}}_1=\mathrm{Left}$), Payoff structure if playing the Left Arm, for the two contexts """, ylabels=_lup['oRew_1'], xlabels=_lup['sContext_0'])
<Figure size 500x500 with 0 Axes>
4.5.3.1.3 Modality \(o^{\mathrm{Choice}}_2\)
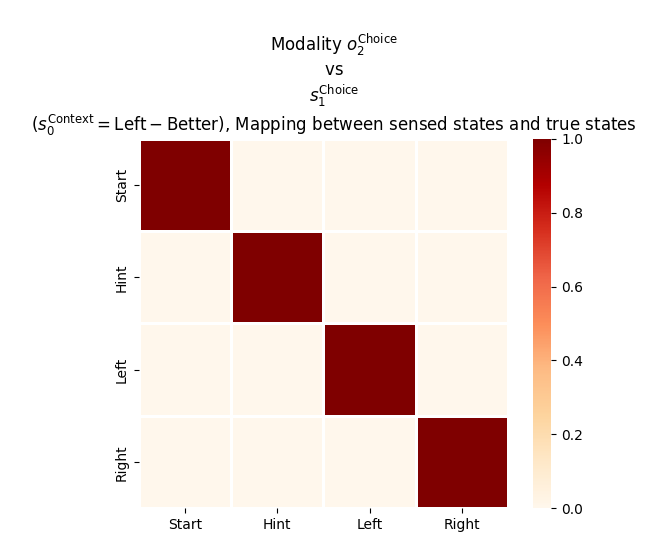
for s1_idx inrange(len(_lup['sChoice_1'])): _A[2][s1_idx, :, s1_idx] =1.0_A[2]## 4 matrices of 2x4
"""Condition on context (first hidden state factor) and display the remaining indices (outcome and choice state) """plot_likelihood( _A[2][:,0,:], title_str=""" Modality $o^{\mathrm{Choice}}_2$ vs $s^{\mathrm{Choice}}_1$ ($s^{\mathrm{Context}}_0=\mathrm{Left-Better}$), Mapping between sensed states and true states""", ylabels=_lup['oChoice_2'], xlabels=_lup['sChoice_1'],)
<Figure size 500x500 with 0 Axes>
utils.is_normalized(_A)
True
4.5.3.2 Transition likelihood matrix, \(\mathbf B\) or \(P(s_{t}\mid s_{t-1}, u_{t-1})\)
print(_a_dims)print(_s_dims)
[1, 4]
[2, 4]
_B_shapes = [[s_dim, s_dim, _a_dims[f]] for f,s_dim inenumerate(_s_dims)]_B_shapes
[[2, 2, 1], [4, 4, 4]]
_B = utils.obj_array_zeros(_B_shapes)_B## 2 matrices of 2x1## 4 matrices of 4x4
from pymdp.maths import softmax## leave _C[0]_C[1][1] =-4.0##. do not want to see the oRew_1 == 'Loss' observation_C[1][2] =2.0##. want to see the oRew_1 == 'Reward' observation ## leave _C[2]_C
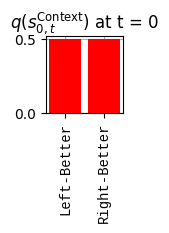
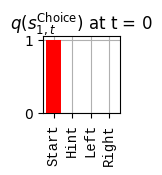
print(f'Beliefs about which arm is better: {_D[0]}')print(f'Beliefs about starting location: {_D[1]}')
Beliefs about which arm is better: [0.5 0.5]
Beliefs about starting location: [1. 0. 0. 0.]
4.6 Agent Evaluation
Now we’ll write a function that will take the agent, the environment, and a time length and run the active inference loop
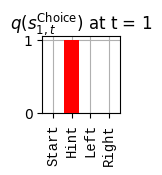
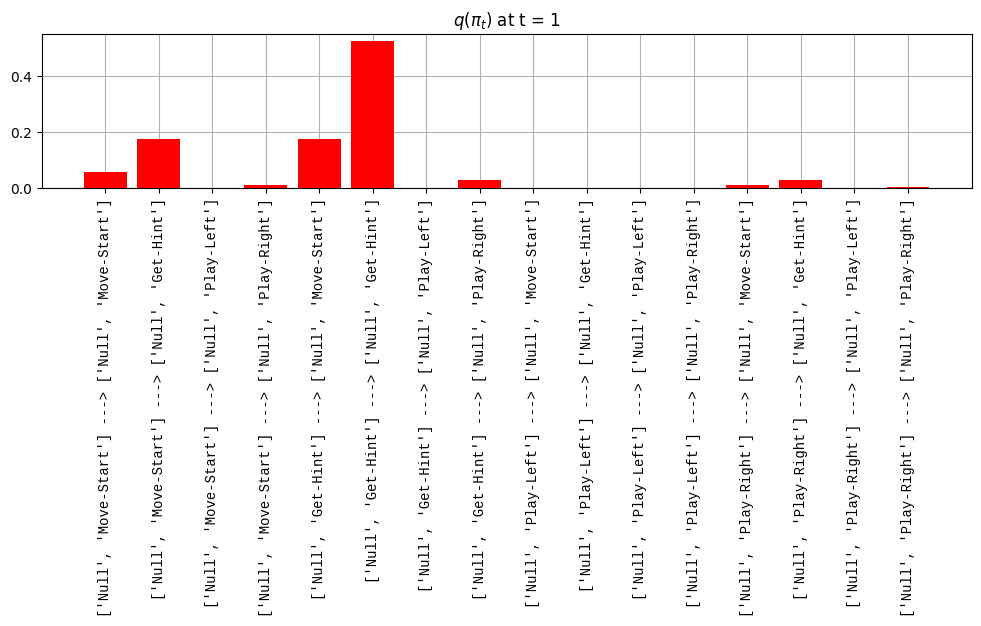
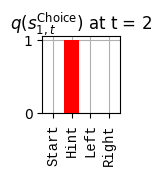
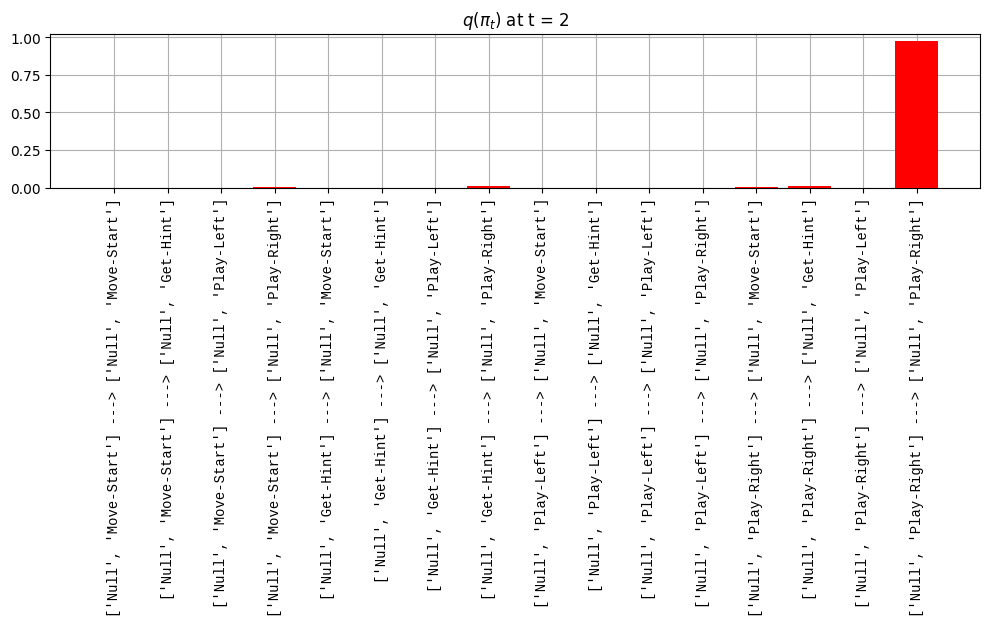
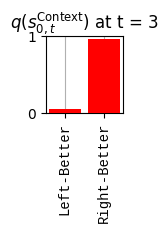
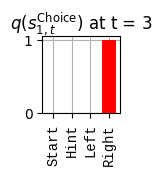
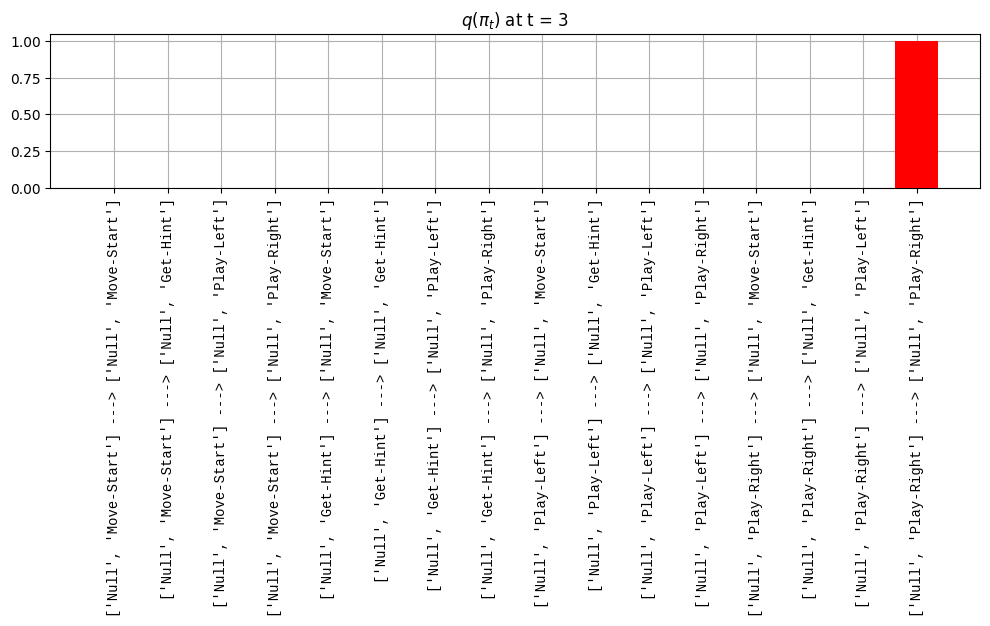
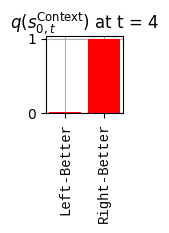
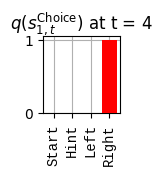
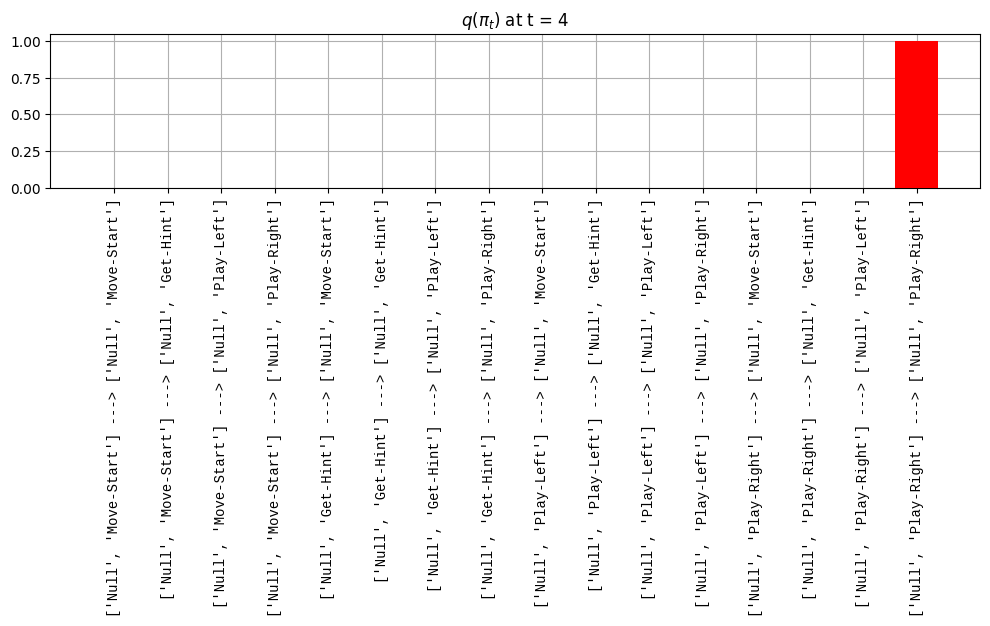
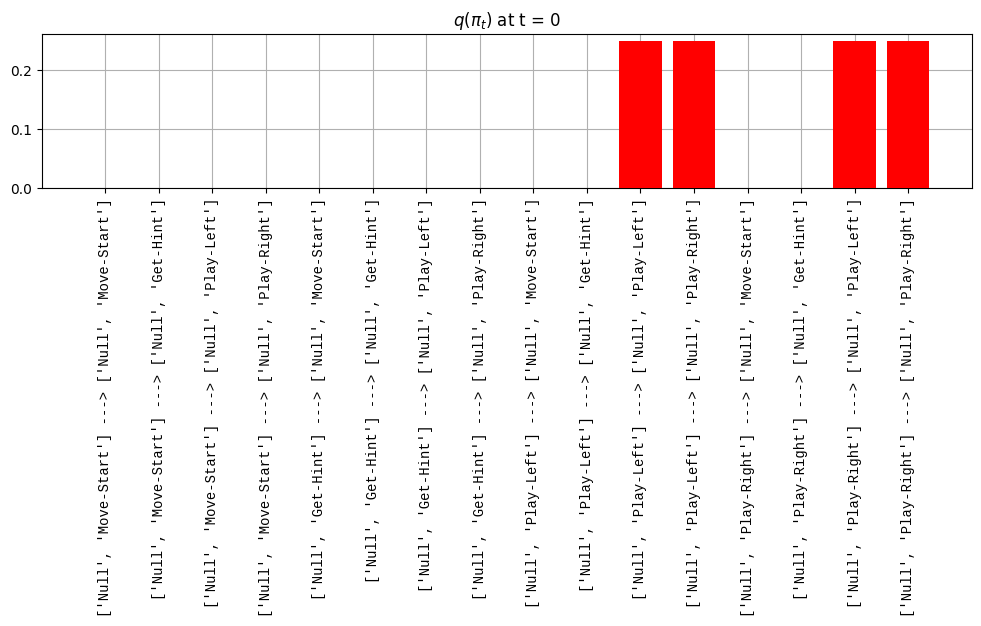
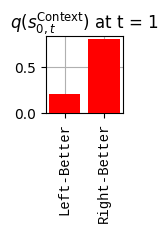
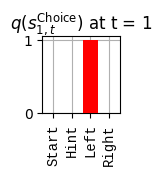
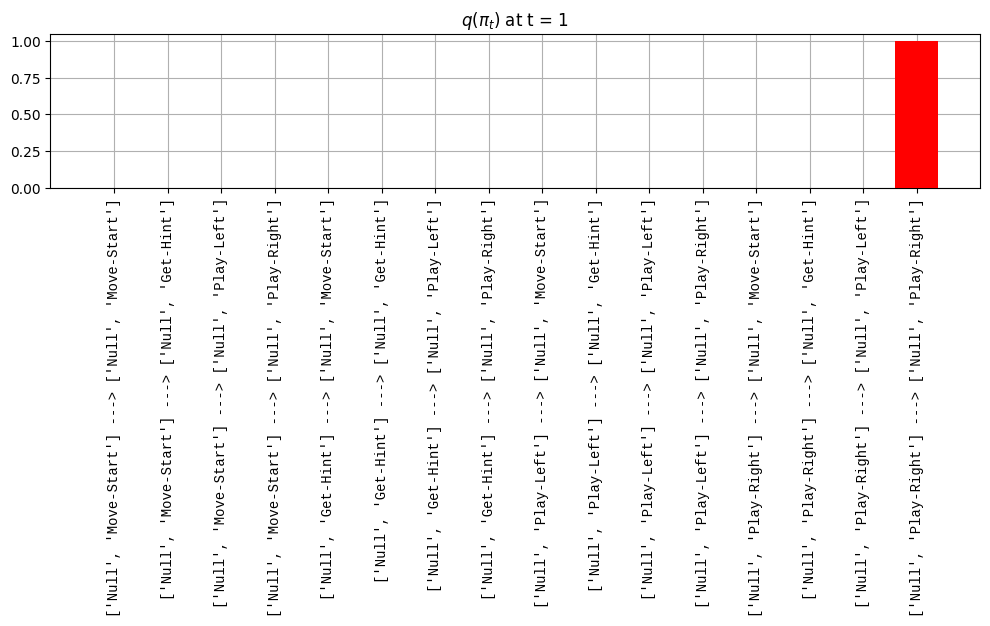
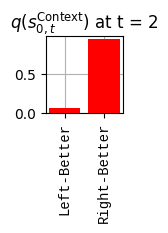
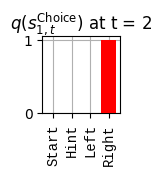
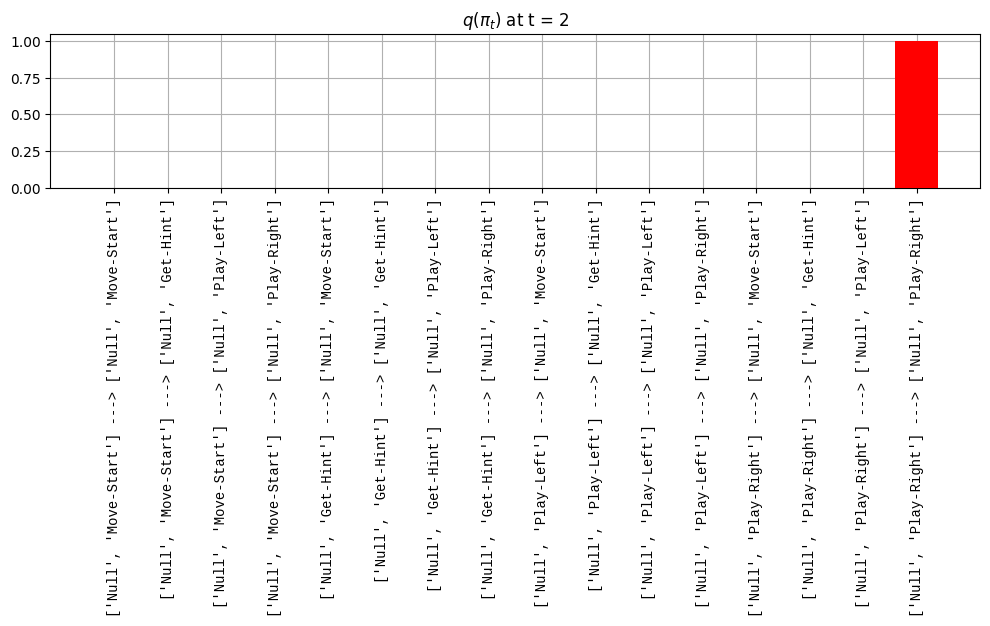
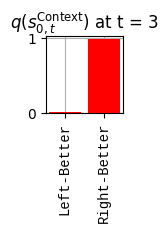
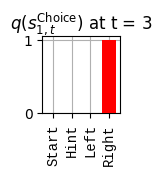
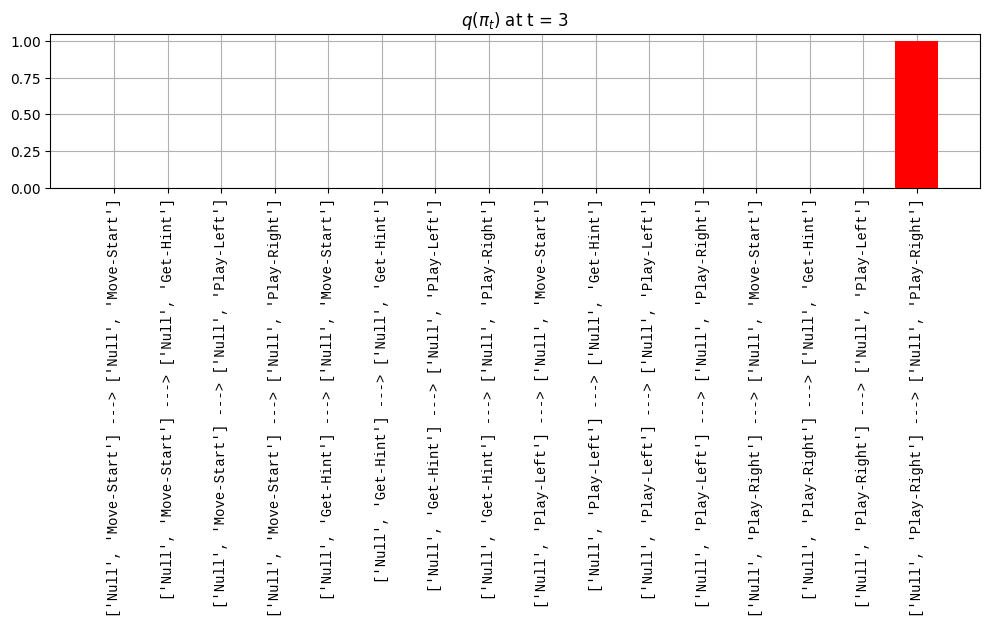
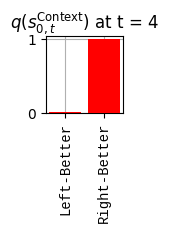
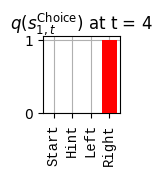
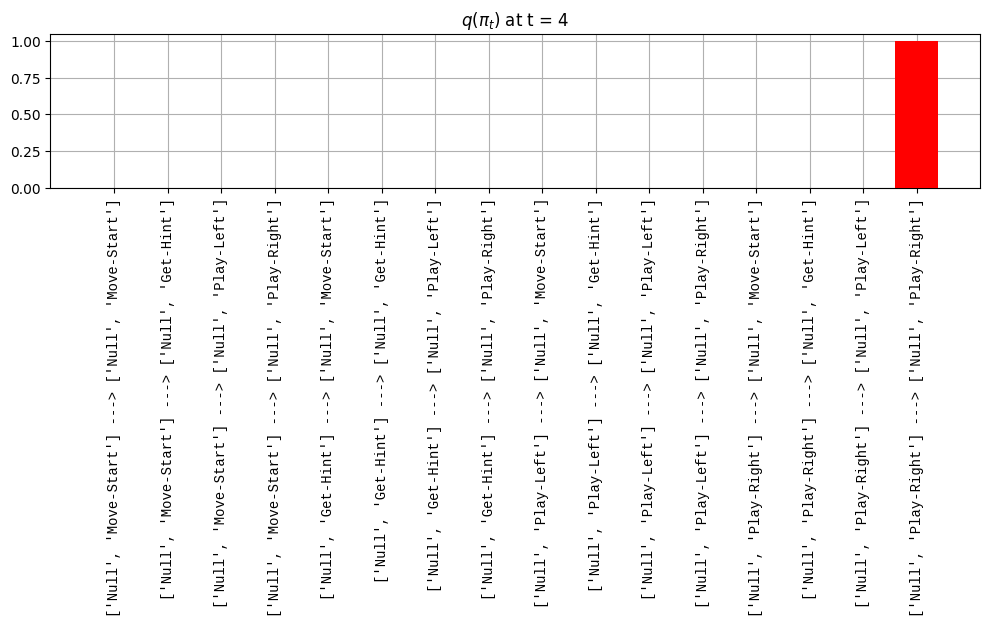
def get_policy_labels(policies): policy_len =len(policies[0]) ## use first policy to find policy_len labels = []for p inrange(len(policies)): ## for each action-sequence / policy lab =''for a inrange(policy_len): ## for each actionif a < policy_len -1: lab = lab+f"{[_lup['aNull_0'][policies[p][a][0]],_lup['aChoice_1'][policies[p][a][1]]]} ---> "else: lab = lab+f"{[_lup['aNull_0'][policies[p][a][0]],_lup['aChoice_1'][policies[p][a][1]]]}" labels.append(lab)return labelsdef run_active_inference_loop(my_agt, my_env, T=5):""" Initialize the first observation """## agent observes itself seeing a `Null` hint, getting a `Null` reward, ## and seeing itself in the `Start` location obs_lab = my_env.reset() ## reset the environment and get an initial observation obs_idx = [ _lup['oHint_0'].index(obs_lab[0]), _lup['oRew_1'].index(obs_lab[1]), _lup['oChoice_2'].index(obs_lab[2])]print(f'Number of policies: {math.prod(_a_dims)**my_agt.policy_len=}')print(f'\tbecause {_a_dims=}, {my_agt.policy_len=}')for t inrange(T): ##. with a slideprint(f"\n===================== Time {t}: =====================") qIsI = my_agt.infer_states(obs_idx) ##. infer. plot_beliefs(qIsI[0], title_str=r"$q(s^{\mathrm{Context}}_{0,t})$"+f" at t = {t}", xlabels=_lup['sContext_0']) plot_beliefs(qIsI[1], title_str=r"$q(s^{\mathrm{Choice}}_{1,t})$"+f" at t = {t}", xlabels=_lup['sChoice_1'])for sfi, sfn inenumerate(_s_fac_names): _s_facs[sfn].append( _lup[sfn][int(np.argmax(qIsI[sfi].round(3).T))] ) qIpiI, efe = my_agt.infer_policies()## efeprint(f'{len(efe)=}');print(f'EFE: {np.round(efe, 2)}')print(f'{np.argmin(efe)=}');print(f'{np.min(efe)=}') lowest_efe_idx = np.round(np.argmin(efe), 2)print(f'LOWEST efe in {lowest_efe_idx}: {efe[lowest_efe_idx]}') plot_efe( efe, title_str=r"$G$"+f" at t = {t}", size=(12,1) ) _GNegs.append(efe)## qIpiIprint(f'{len(qIpiI)=}');print(f'qIpiI: {np.round(qIpiI, 2)}')print(f'{np.argmax(qIpiI)=}');print(f'{np.max(qIpiI)=}')print(f'BEST qIpiI: {np.round(qIpiI[lowest_efe_idx], 2)}') ps = my_agt.policies plot_beliefs( qIpiI, title_str=r"$q(\pi_{t})$"+f" at t = {t}", xlabels=get_policy_labels(my_agt.policies), size=(12,2) ) _qIpiIs.append(qIpiI) act_idx = my_agt.sample_action() ##. Act future & act_idx_controllable =int(act_idx[1]) act_lab_controllable = _lup['aChoice_1'][act_idx_controllable] ##.for afi, afn inenumerate(_a_fac_names): _a_facs[afn].append(_a_val_names[afi][int(act_idx[afi])]) obs_lab = my_env.step(act_lab_controllable) ##. next observe, howto obs_idx = [ _lup['oHint_0'].index(obs_lab[0]), _lup['oRew_1'].index(obs_lab[1]), _lup['oChoice_2'].index(obs_lab[2])]for omi, omn inenumerate(_o_mod_names): _o_mods[omn].append(_o_val_names[omi][obs_idx[omi]])print(f'Action at time {t}: {act_lab_controllable}')print(f'Reward at time {t}: {obs_lab[1]}')
_a_fac_names = ['aNull_0', 'aChoice_1'] ## control factor names_s_fac_names = ['sContext_0', 'sChoice_1'] ## state factor names_s̆_fac_names = ['s̆Context_0', 's̆Choice_1'] ## state factor names_o_mod_names = ['oHint_0', 'oRew_1', 'oChoice_2'] ## observation modality names_a_val_names = [_lup[cfn] for cfn in _a_fac_names];print(f'{_a_val_names=}')_s_val_names = [_lup[sfn] for sfn in _s_fac_names];print(f'{_s_val_names=}')_s̆_val_names = [_lup[sfn] for sfn in _s̆_fac_names];print(f'{_s̆_val_names=}')_o_val_names = [_lup[omn] for omn in _o_mod_names];print(f'{_o_val_names=}')
Now all we have to do is define the bandit environment, choose the length of the simulation, and run the function we wrote above.
Try playing with the hint accuracy and/or reward statistics of the environment - remember this is different than the agent’s representation of the reward statistics (i.e. the agent’s generative model, e.g. the A or B matrices).
## Create an envir## this is the "true" accuracy of the hint - i.e. how often does the hint actually ## signal which arm is better. REMEMBER: THIS IS INDEPENDENT OF HOW YOU PARAMETERIZE ## THE A MATRIX FOR THE HINT MODALITY_p_hint_env =1.0## this is the "true" reward probability - i.e. how often does the better arm actually ## return a reward, as opposed to a loss. REMEMBER: THIS IS INDEPENDENT OF HOW YOU ## PARAMETERIZE THE A MATRIX FOR THE REWARD MODALITY_p_reward_env =0.7_my_envir = EpistemicMABEnvir( context="Right-Better", p_hint=_p_hint_env, p_reward=_p_reward_env)print(f'Context: {_my_envir.s̆Context_0}')
Context: Right-Better
## Create an agent## list of the indices of the hidden state factors that are controllable## sContext_0: uncontrollable; sChoice_1: controllable_controllable_indices = [1]_my_agent = Agent( A=_A, B=_B, C=_C, D=_D,## number of action values (aChoice_1); aNull_0 has a single value, so 1*4=4# policy_len=1, ##. 4**1 = 4 ele policy_len=2, ##. 4**2 = 16 ele# policy_len=3, ##. 4**3 = 64 ele # policy_len=4, ##. 4**4 = 256 ele control_fac_idx=_controllable_indices )_my_agent
Now let’s try manipulating the agent’s prior preferences over reward observations (\(\mathbf{C}[1]\)) in order to examine the tension between exploration and exploitation.
## Create an envir## re-initialize the environment -- this time, the hint is not always accurate ## (`p_hint = 0.8`)## _my_envir = ThreeArmedBanditEnvir(p_hint=0.8, p_reward=0.8) ##. previously: p_hint=1.0 & p_reward=0.7_my_envir = EpistemicMABEnvir( context="Right-Better", # context="Left-Better", p_hint=0.7, p_reward=0.8) ##. previously: p_hint=1.0 & p_reward=0.7print(f'Context: {_my_envir.s̆Context_0}')
Context: Right-Better
## Create an agent## change the 'shape' of the agent's reward function## makes the Loss "less aversive" than before (higher prior probability assigned ## to seeing the Loss outcome). This should make the agent less ## risk-averse / willing to explore both arms, under uncertainty_C[1][1] =0.0##. previously -4.0 for oRew_1 == 'Loss' observation## redefine the agent with the new preferences_my_agent = Agent( A=_A, B=_B, C=_C, D=_D,## number of action values (aChoice_1); aNull_0 has a single value, 1*4=4# policy_len=1, ##. 4**1 = 4 ele policy_len=2, ##. 4**2 = 16 ele# policy_len=3, ##. 4**3 = 64 ele # policy_len=4, ##. 4**4 = 256 ele control_fac_idx=_controllable_indices ##.)