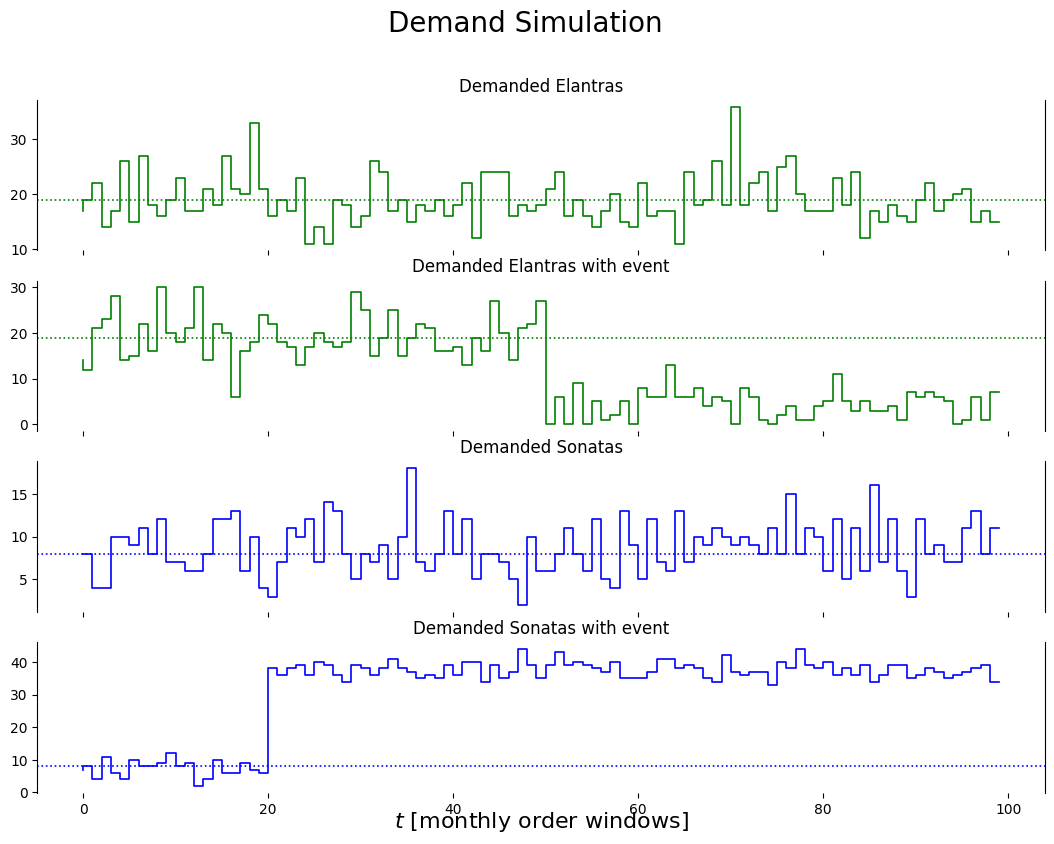
In part 2 Mr. Optimal managed the number of Elantras and Sonatas on his dealership space of 57 lots. In this project we expand the model so that stockout costs as well as holding costs are taken into account for each item. In addition, we expand the demand simulation capability so that we can experiment with abrubt changes in the demand for an item.
We will also demonstrate that these kinds of changes can have a substantial negative effect on the performance of policies that were not trained on the data that have these events. We will not currently consider how this problem might be addressed, for example to have the policy continuously being updated.
The overall structure of this project and report follows the traditional CRISP-DM format. However, instead of the CRISP-DM’S “4 Modeling” section, we inserted the “6 step modeling process” of Dr. Warren Powell in section 4 of this document. Dr Powell’s unified framework shows great promise for unifying the formalisms of at least a dozen different fields. Using his framework enables easier access to thinking patterns in these other fields that might be beneficial and informative to the sequential decision problem at hand. Traditionally, this kind of problem would be approached from the reinforcement learning perspective. However, using Dr. Powell’s wider and more comprehensive perspective almost certainly provides additional value.
In order to make a strong mapping between the code in this notebook and the mathematics in the Powell Unified Framework (PUF), we follow the following convention for naming Python identifier names:
Superscripts
variable names have a double underscore to indicate a superscript
\(X^{\pi}\): has code X__pi, is read X pi
Subscripts
variable names have a single underscore to indicate a subscript
\(S_t\): has code S_t, is read ‘S at t’
\(M^{Spend}_t\) has code M__Spend_t which is read: “MSpend at t”
Arguments
collection variable names may have argument information added
\(X^{\pi}(S_t)\): has code X__piIS_tI, is read ‘X pi in S at t’
the surrounding I’s are used to imitate the parentheses around the argument
Next time/iteration
variable names that indicate one step in the future are quite common
\(R_{t+1}\): has code R_tt1, is read ‘R at t+1’
\(R^{n+1}\): has code R__nt1, is read ‘R at n+1’
Rewards
State-independent terminal reward and cumulative reward
\(F\): has code F for terminal reward
\(\sum_{n}F\): has code cumF for cumulative reward
State-dependent terminal reward and cumulative reward
\(C\): has code C for terminal reward
\(\sum_{t}C\): has code cumC for cumulative reward
Vectors where components use different names
\(S_t(R_t, p_t)\): has code S_t.R_t and S_t.p_t, is read ‘S at t in R at t, and, S at t in p at t’
the code implementation is by means of a named tuple
self.State = namedtuple('State', SVarNames) for the ‘class’ of the vector
self.S_t for the ‘instance’ of the vector
Vectors where components reuse names
\(x_t(x_{t,GB}, x_{t,BL})\): has code x_t.x_t_GB and x_t.x_t_BL, is read ‘x at t in x at t for GB, and, x at t in x at t for BL’
the code implementation is by means of a named tuple
self.Decision = namedtuple('Decision', xVarNames) for the ‘class’ of the vector
self.x_t for the ‘instance’ of the vector
Use of mixed-case variable names
to reduce confusion, sometimes the use of mixed-case variable names are preferred (even though it is not a best practice in the Python community), reserving the use of underscores and double underscores for math-related variables
1 BUSINESS UNDERSTANDING
Inventory management is a critical component of any business, whether it be a small retail store or a multinational corporation. At its core, inventory management is the process of tracking and controlling a company’s inventory, from raw materials to finished products. Proper inventory management is important for several reasons.
First and foremost, inventory management helps businesses avoid stock overages and underages (overstocks and stockouts). By tracking inventory levels and forecasting demand, businesses can ensure that they always have the right amount of product on hand to meet customer needs without overbuying and tying up capital in excess inventory. This helps businesses maintain a healthy cash flow and avoid costly stockouts that can result in lost sales and dissatisfied customers.
In addition, effective inventory management can help businesses streamline their operations and improve their overall efficiency. By reducing excess inventory and optimizing order quantities and lead times, businesses can minimize waste and improve their supply chain management. This can lead to cost savings, improved profitability, and increased customer satisfaction.
Finally, inventory management is critical for businesses that need to comply with regulatory requirements, such as those in the pharmaceutical or food industries. Proper inventory tracking and documentation can help businesses meet these requirements and avoid costly fines and penalties.
Overall, inventory management is an essential function for any business that wants to operate efficiently, meet customer demand, and maximize profitability. Effective inventory management requires careful planning, accurate data, and the right tools and processes to ensure that businesses always have the right amount of product on hand, at the right time, and at the right cost.
In this project the client had a need to be convinced of the benefits of formal optimized sequential decision making. This was provided in the form of a series of POCs.
2 DATA UNDERSTANDING
As in part 2, we will simulate the inventory demand for Elantras, \(D^{ELA}\), by: \[
D^{ELA}_{t+1} = \epsilon_{pois(17)}
\]
Similarly,
the inventory demand for Sonatas, \(D^{SON}\), is given by: \[
D^{SON}_{t+1} = \epsilon_{pois(9)}
\]
The order window is 1 month and these simulations are for the monthly demands.
In this POC we expand the simulator to also handle demand events where the mean demand for an item abrubtly changes.
from collections import namedtuple, defaultdictimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom copy import copyimport timefrom scipy.ndimage.interpolation import shiftimport picklefrom bisect import bisectimport mathfrom pprint import pprintimport matplotlib as mplpd.options.display.float_format ='{:,.4f}'.formatpd.set_option('display.max_columns', None)pd.set_option('display.max_rows', None)pd.set_option('display.max_colwidth', None)! python --version
Python 3.10.11
DeprecationWarning: Please use `shift` from the `scipy.ndimage` namespace, the `scipy.ndimage.interpolation` namespace is deprecated.
from scipy.ndimage.interpolation import shift
# NOTE:# R__max: maximum number of inventory units# R_0: initial number of inventory unitsparDf = pd.read_excel(f'{base_dir}/{file}', sheet_name='ParamsModel', index_col=0);print(f'{parDf}')parDict = parDf.T.to_dict('list') #.params = {key:v for key, value in parDict.items() for v in value}params['seed'] = seedparams['T'] =min(params['T'], 192);print(f'{params=}')
0
Index
Algorithm GridSearch
T 195
eta 1
R__max 57
R_0 0
params={'Algorithm': 'GridSearch', 'T': 192, 'eta': 1, 'R__max': 57, 'R_0': 0, 'seed': 189654913}
parDf = pd.read_excel(f'{base_dir}/{file}', sheet_name='GridSearch', index_col=0);print(parDf)parDict = parDf.T.to_dict('list')paramsPolicy = {key:v for key, value in parDict.items() for v in value};print(f'{paramsPolicy=}')params.update(paramsPolicy); pprint(f'{params=}')
We will use the data provided by the simulator directly. There is no need to perform additional data preparation.
4 MODELING
4.1 Narrative
As pointed out in the introduction, this third project in the Inventory Series expands the problem in part 2 to also take into account the effects of:
holding costs, and
stockout costs
To remind the reader, we have the following setting: Mr. Optimal is an inventory manager for the largest dealership in a big city. He is responsible to manage the inventory levels of the two mentioned Hyundai models. He has a maximum number of lot spaces assigned to him (which is 57). Mr. Optimal decided to reserve a maximum of 40 spaces for the Elantras. The remaining 17 spaces will be used for Sonata. He has a choice to strive to always keep these spaces occupied by new cars. This way he is unlikely to run out of stock and lose a sale due to that. However, capital is tied up by the unsold inventory in his lot space.
At the other extreme, he may choose to work on a just-in-time principle: Each time a potential customer expresses interest in a model, the customer will have to wait until he obtains a new car from the supplier. Of course, he will likely lose the sale, but the upside is that no capital is tied up in his inventory.
It seems intuitive that the optimal levels of inventory will be somewhere between these extremes. The challenge is to find that optimal levels. For now, we will assume that the buy and sell prices will remain constant. The only random variables will be the demands for these models. Another assumption is that ordered inventory will arrive immediately.
Unsatisfied demands are lost, i.e. there will be no ability to backlog unsatisfied demands. However, a stockout cost is incurred when demand is unsatisfied. Moreover, existing inventory brings about a holding cost for each item. The latter cost is usually made up of lost interest on cash used to buy the item as well as upkeep cost. Under upkeep we could think of making sure batteries are kept in a charged state, fuel associated with drive arounds to showcase a vehicle, as well as costs associated with keeping the vehicles clean and groomed.
4.2 Core Elements
This section attempts to answer three important questions: - What metrics are we going to track? - What decisions do we intend to make? - What are the sources of uncertainty?
For this problem, the only metric we are interested in is the amount of profit we make after each decision window. A single type of decision needs to be made at the start of each window - how many new cars to order of each model. The only source of uncertainty are the levels of demand for the models.
4.3 Mathematical Model | SUM Design
The parameters of the inventory system under management (SUM) are:
p__buyELA =19_300#dollarsp__sellELA =23_470#dollarsp__buySON =22_100#dollarsp__sellSON =27_250#dollarsR__maxELA =40#spacesR__maxSON =17#spacesc__interest =0.05/12c__upkeepELA =28.43#dollars per itemc__upkeepSON =34.72#dollars per item
A Python class is used to implement the model for the SUM (System Under Management):
The exogenous information variables represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(x_t\).
We assume that any unsatisfied demand is lost. Additionally, we assume that the demand in each time period is revealed, so that we have:
\[
W_{t+1} = \hat{D}_{t+1}=D_{t+1}
\]
The exogenous information is obtained by a call to
DemandSimulator.simulate(...)
The latest exogenous information can be accessed by calling the following method from class InventoryStorageModel():
The transition function describe how the state variables evolve over time. Because we currently have two state variables in the state, \(S_t=(R_t,D_t)\), we have the equations:
Collectively, they represent the general transition function:
\[
S_{t+1} = S^M(S_t,X^{\pi}(S_t))
\] The transition function is implemented by the following method in class InventoryStorageModel():
def S__M_fn(self, t, x_t, Dhat_tt1_ELA, Dhat_tt1_SON):
R_tt1_ELA = max( 0, self.S_t.R_t_ELA - min(self.S_t.R_t_ELA, self.S_t.D_t_ELA) + x_t.x_t_ELA ) #max to keep >0
R_tt1_SON = max( 0, self.S_t.R_t_SON - min(self.S_t.R_t_SON, self.S_t.D_t_SON) + x_t.x_t_SON ) #max to keep >0
# D_tt1_ELA, D_tt1_SON = self.W_fn(t) #data is skipped/wasted if called again
D_tt1_ELA = Dhat_tt1_ELA
D_tt1_SON = Dhat_tt1_SON
S_tt1 = self.build_state({'R_t_ELA':R_tt1_ELA,'R_t_SON':R_tt1_SON, 'D_t_ELA':D_tt1_ELA,'D_t_SON':D_tt1_SON})
return S_tt1
4.3.5 Objective function
The objective function captures the performance metrics of the solution to the problem.
First, let us state the stockout and holding costs:
\[
\begin{align}
c^{soutELA} &= p^{sellELA}\max\{D_{t,ELA} - R_{t,ELA}, 0 \} \\
c^{soutSON} &= p^{sellSON}\max\{D_{t,SON} - R_{t,SON}, 0 \} \\
c^{holdELA} &= c^{interest}p^{buyELA} + c^{upkeepELA} \\
c^{holdSON} &= c^{interest}p^{buySON} + c^{upkeepSON}
\end{align}
\] where the first two equations represent the opportunity cost of unsatisfied demand. The last two equations represent the interest and upkeep costs for each item over each order window. Each of these costs will have to be subtracted from the contribution, \(C\).
We can write the state-dependant reward (also called contribution) based on what we will receive between \(t-1\) and \(t\) (i.e. looking backward relative to \((S_t,x_t)\)):
\[
\begin{align}
C(S_t,x_t) = p^{sellELA}\min\{R_{t,ELA}, D_{t,ELA}\} - p^{buyELA}x_{t,ELA} - c^{soutELA} - c^{holdELA} \\
+ p^{sellSON}\min\{R_{t,SON}, D_{t,SON}\} - p^{buySON}x_{t,SON} - c^{soutSON} - c^{holdSON}
\end{align}
\] This is a deterministic expression.
Alternatively, we can write the state-dependant reward based on what we will receive between \(t\) and \(t+1\) (i.e. looking forward relative to \((S_t,x_t)\)):
This is a stochastic expression due to the dependence on the random variable \(\hat{D}_{t+1}\). It is random because it comes from a stochastic process but it is also in the future.
Here is the complete implementation of the InventoryStorageModel class:
class InventoryStorageModel():def__init__(self, SVarNames, xVarNames, S_0, params, exogParams, possibleDecisions, p__buyELA, p__sellELA, p__buySON, p__sellSON, W_fn=None, S__M_fn=None, C_fn=None):self.initArgs = paramsself.prng = np.random.RandomState(params['seed'])self.exogParams = exogParamsself.S_0 = S_0self.SVarNames = SVarNamesself.xVarNames = xVarNamesself.possibleDecisions = possibleDecisionsself.p__buyELA = p__buyELAself.p__sellELA = p__sellELAself.p__buySON = p__buySONself.p__sellSON = p__sellSON self.State = namedtuple('State', SVarNames) #. 'class'self.S_t =self.build_state(self.S_0) #. 'instance'self.Decision = namedtuple('Decision', xVarNames) #. 'class'self.cumC =0.0#. cumulative reward; use F or cumF for final (i.e. no cumulative) rewarddef reset(self):self.cumC =0.0self.S_t =self.build_state(self.S_0)def build_state(self, info):returnself.State(*[info[sn] for sn inself.SVarNames])def build_decision(self, info):returnself.Decision(*[info[xn] for xn inself.xVarNames])def W_fn(self, t): W_tt1_ELA, W_tt1_SON = dem_sim.simulate()return (W_tt1_ELA, W_tt1_SON)def S__M_fn(self, t, x_t, Dhat_tt1_ELA, Dhat_tt1_SON): R_tt1_ELA =max( 0, self.S_t.R_t_ELA -min(self.S_t.R_t_ELA, self.S_t.D_t_ELA) + x_t.x_t_ELA ) #max to keep >0 R_tt1_SON =max( 0, self.S_t.R_t_SON -min(self.S_t.R_t_SON, self.S_t.D_t_SON) + x_t.x_t_SON ) #max to keep >0# D_tt1_ELA, D_tt1_SON = self.W_fn(t) #data is skipped/wasted if called again D_tt1_ELA = Dhat_tt1_ELA D_tt1_SON = Dhat_tt1_SON S_tt1 =self.build_state({'R_t_ELA':R_tt1_ELA,'R_t_SON':R_tt1_SON, 'D_t_ELA':D_tt1_ELA,'D_t_SON':D_tt1_SON})return S_tt1# based on what we will receive between t and t+1 (i.e. looking *forward* relative to (S_t,x_t) #.# RLSO-Eq8.5def C_fn(self, x_t): Dhat_tt1_ELA, Dhat_tt1_SON = dem_sim.simulate() c__soutELA =self.p__sellELA*max(self.S_t.D_t_ELA -self.S_t.R_t_ELA, 0) #unmet demand c__soutSON =self.p__sellSON*max(self.S_t.D_t_SON -self.S_t.R_t_SON, 0) #unmet demand c__holdELA = c__interest*self.p__buyELA + c__upkeepELA #interest & upkeep c__holdSON = c__interest*self.p__buySON + c__upkeepSON #interest & upkeep C =\self.p__sellELA*min((self.S_t.R_t_ELA -min(self.S_t.R_t_ELA, self.S_t.D_t_ELA) + x_t.x_t_ELA), Dhat_tt1_ELA) \-self.p__buyELA*x_t.x_t_ELA - c__soutELA - c__holdELA +\self.p__sellSON*min((self.S_t.R_t_SON -min(self.S_t.R_t_SON, self.S_t.D_t_SON) + x_t.x_t_SON), Dhat_tt1_SON) \-self.p__buySON*x_t.x_t_SON - c__soutSON - c__holdSONreturn C, Dhat_tt1_ELA, Dhat_tt1_SON #pass along exog_info, else data is skipped/wasteddef step(self, t, x_t): C, Dhat_tt1_ELA, Dhat_tt1_SON =self.C_fn(x_t)self.cumC += Cself.S_t =self.S__M_fn(t, x_t, Dhat_tt1_ELA, Dhat_tt1_SON)return (self.S_t, self.cumC, x_t) #. for plotting
4.4 Uncertainty Model
We will simulate the inventory demand vector \(D_{t+1} = (D_{t+1,ELA}, D_{t+1,SON})\) as described in section 2.
4.5 Policy Design
There are two main meta-classes of policy design. Each of these has two subclasses: - Policy Search - Policy Function Approximations (PFAs) - Cost Function Approximations (CFAs) - Lookahead - Value Function Approximations (VFAs) - Direct Lookaheads (DLAs)
In this project we will only use one approach: - A simple buy below parameterized policy (from the PFA class)
The buy below policy is implemented by the following method in class InventoryStoragePolicy():
def X__BuyBelow(self, t, S_t, theta, T):
info = {
'x_t_ELA': 0, #number of Elantras ordered
'x_t_SON': 0, #number of Sonatas ordered
}
if t >= T:
print(f"ERROR: t={t} should not reach or exceed the max steps ({T})")
return self.model.build_decision(info)
theta__buy_ELA = theta[0]
if S_t.R_t_ELA <= theta__buy_ELA: # BUY if R_t_ELA <= theta__buy_ELA
info['x_t_ELA'] = self.model.initArgs['R__maxELA'] - S_t.R_t_ELA
theta__buy_SON = theta[1]
if S_t.R_t_SON <= theta__buy_SON: # BUY if R_t_SON <= theta__buy_SON
info['x_t_SON'] = self.model.initArgs['R__maxSON'] - S_t.R_t_SON
return self.model.build_decision(info)
4.5.1 Implementation of Policy Design
The InventoryStoragePolicy() class implements the policy design.
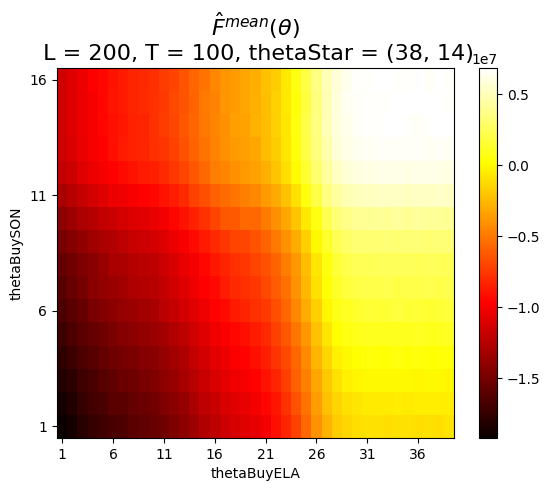
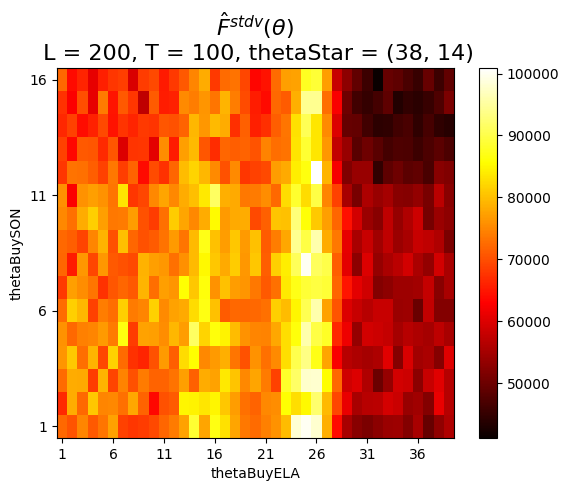
import randomclass InventoryStoragePolicy():def__init__(self, model, piNames):self.model = modelself.piNames = piNamesself.Policy = namedtuple('Policy', piNames)def X__BuyBelow(self, t, S_t, theta, T): #theta is a vector info = {'x_t_ELA': 0, #number of Elantras to order'x_t_SON': 0, #number of Sonatas to order }if t >= T:print(f"ERROR: t={t} should not reach or exceed the max steps ({T})")returnself.model.build_decision(info) theta__buy_ELA = theta[0]if S_t.R_t_ELA <= theta__buy_ELA: # BUY if R_t_ELA <= theta__buy_ELA# info['x_t_ELA'] = self.model.initArgs['R__maxELA'] - S_t.R_t_ELA info['x_t_ELA'] = R__maxELA - S_t.R_t_ELA theta__buy_SON = theta[1]if S_t.R_t_SON <= theta__buy_SON: # BUY if R_t_SON <= theta__buy_SON# info['x_t_SON'] = self.model.initArgs['R__maxSON'] - S_t.R_t_SON info['x_t_SON'] = R__maxSON - S_t.R_t_SONreturnself.model.build_decision(info)def run_policy(self, piInfo, piName, params): model_copy = copy(self.model) T = params['T']for t inrange(T): #for each transition/step x_t =getattr(self, piName)(t, model_copy.S_t, piInfo, T) # piInfo is theta value _, _, _ = model_copy.step(t, x_t) cumC = model_copy.cumC return cumCdef perform_grid_search(self, params, thetas): tS = time.time() cumCI_theta_I = {} bestTheta =None i =0;print(f'... printing every 100th theta ...')for theta in thetas:if i%100==0: print(f'=== {theta=} ===') cumC =self.run_policy(theta, "X__BuyBelow", params) cumCI_theta_I[theta] = cumC best_theta =max(cumCI_theta_I, key=cumCI_theta_I.get)# print(f"Finishing theta {theta} with cumC {cumC:,}. Best theta so far {best_theta}. Best cumC {cumCI_theta_I[best_theta]:,}") i +=1print(f"Finishing GridSearch in {time.time() - tS:.2f} secs")print(f"Best theta: {best_theta}. Best cumC: {cumCI_theta_I[best_theta]:,}")return cumCI_theta_I, best_thetadef run_policy_sample_paths(self, theta, piName, params): #theta could be a vector FhatIomega__lI = []for l inrange(1, params['L'] +1): #for each sample-path model_copy = copy(self.model) record_l = [piName, theta, l] T = params['T']for t inrange(T): #for each transition/step x_t =getattr(self, piName)(t, model_copy.S_t, theta, T) _, _, _ = model_copy.step(t, x_t) FhatIomega__lI.append(model_copy.cumC) # just above (SDAM-eq2.9); Fhat for this sample-path is in model_copy.cumCreturn FhatIomega__lIdef perform_grid_search_sample_paths(self, params, thetas): tS = time.time() Fhat_mean =None Fhat_var =None Fhat__meanI_th_I = {} Fhat__stdvI_th_I = {} Fhat_mean =None i =0;print(f'... printing every 100th theta ...')for theta in thetas:if i%100==0: print(f'=== {theta=} ===') FhatIomega__lI =self.run_policy_sample_paths(theta, "X__BuyBelow", params) Fhat_mean = np.array(FhatIomega__lI).mean() #. (SDAM-eq2.9); call Fbar in future Fhat_var = np.sum(np.square(np.array(FhatIomega__lI) - Fhat_mean))/(params['L'] -1) Fhat__meanI_th_I[theta] = Fhat_mean Fhat__stdvI_th_I[theta]= np.sqrt(Fhat_var/params['L']) best_theta =max(Fhat__meanI_th_I, key=Fhat__meanI_th_I.get)# print(f"Finishing theta {theta} with cumC {Fhat__meanI_th_I[best_theta]:,}. Best theta so far {best_theta}. Best cumC {Fhat__meanI_th_I[best_theta]:,}") i +=1print(f"Finishing GridSearch in {time.time() - tS:.2f} secs")print(f"Best theta: {best_theta}. Best cumC: {Fhat__meanI_th_I[best_theta]:,}")return Fhat__meanI_th_I, Fhat__stdvI_th_I, best_thetadef grid_search_theta_values(self, thetas0): #. using vectors reduces loops in perform_grid_search_sample_paths() thetas = [(th0,) for th0 in thetas0]return thetasdef grid_search_theta_values(self, thetas0, thetas1): #. using vectors reduces loops in perform_grid_search_sample_paths() thetas = [(th0, th1) for th0 in thetas0 for th1 in thetas1]return thetasdef plot_Fhat_map(self, FhatI_theta_I, thetasX, thetasY, labelX, labelY, title): Fhat_values = [FhatI_theta_I[(thetaX,thetaY)] for thetaY in thetasY for thetaX in thetasX] Fhats = np.array(Fhat_values) increment_count =len(thetasX) Fhats = np.reshape(Fhats, (-1, increment_count)) fig, ax = plt.subplots() im = ax.imshow(Fhats, cmap='hot', origin='lower', aspect='auto')# create colorbar cbar = ax.figure.colorbar(im, ax=ax)# cbar.ax.set_ylabel(cbarlabel, rotation=-90, va="bottom")# we want to show all ticks... ax.set_xticks(np.arange(0,len(thetasX), 5)) ax.set_yticks(np.arange(0,len(thetasY), 5))# ... and label them with the respective list entries ax.set_xticklabels(thetasX[::5]) ax.set_yticklabels(thetasY[::5])# rotate the tick labels and set their alignment.#plt.setp(ax.get_xticklabels(), rotation=45, ha="right",rotation_mode="anchor") ax.set_title(title, fontsize=16) ax.set_xlabel(labelX) ax.set_ylabel(labelY)#fig.tight_layout() plt.show()returnTruedef plot_Fhat_chart(self, FhatI_theta_I, thetasX, labelX, labelY, title, color_style): mpl.rcParams['lines.linewidth'] =1.2 xylabelsize =18 plt.figure(figsize=(25, 8)) plt.title(title, fontsize=20) Fhats = FhatI_theta_I.values() plt.plot(thetasX, Fhats, color_style) plt.xlabel(labelX, rotation=0, ha='right', va='center', fontweight='bold', size=xylabelsize) plt.ylabel(labelY, rotation=0, ha='right', va='center', fontweight='bold', size=xylabelsize) plt.show()
4.6 Policy Evaluation
4.6.1 Training/Tuning
# UPDATE PARAMETERSparams.update({'Algorithm': 'GridSearch'}); pprint(f'{params=}')params.update({'R_0': (0, 0)}) #for 'R_t_ELA', 'R_t_SON'params.update({'eta': None})# params.update({'theta_buy_min': 10}) #order level# params.update({'theta_buy_max': 50}) #order levelparams.update({'theta_sell_min': None})params.update({'theta_sell_max': None})# ADDITIONAL PARAMETERSparams.update({'theta_buy_min_ELA': 1}) #order levelparams.update({'theta_buy_max_ELA': 40}) #order levelparams.update({'theta_buy_min_SON': 1}) #order levelparams.update({'theta_buy_max_SON': 17}) #order levelexogParams = {}# we use simulationpiNames = ['X__BuyBelow']SVarNames = ['R_t_ELA', 'R_t_SON', 'D_t_ELA', 'D_t_SON'] #expand each scalar into a vectorS_0 = {'R_t_ELA': params['R_0'][0],'R_t_SON': params['R_0'][1],'D_t_ELA': 0,'D_t_SON': 0,}xVarNames = ['x_t_ELA', 'x_t_SON'] #expand each scalar into a vectorpossibleDecisions =NoneT__sim =100params
# UPDATE PARAMETERSparams.update({'L': 2*T__sim}) #number of sample-pathsparams.update({'T': T__sim}) #number of transitions/steps in each sample-pathparams
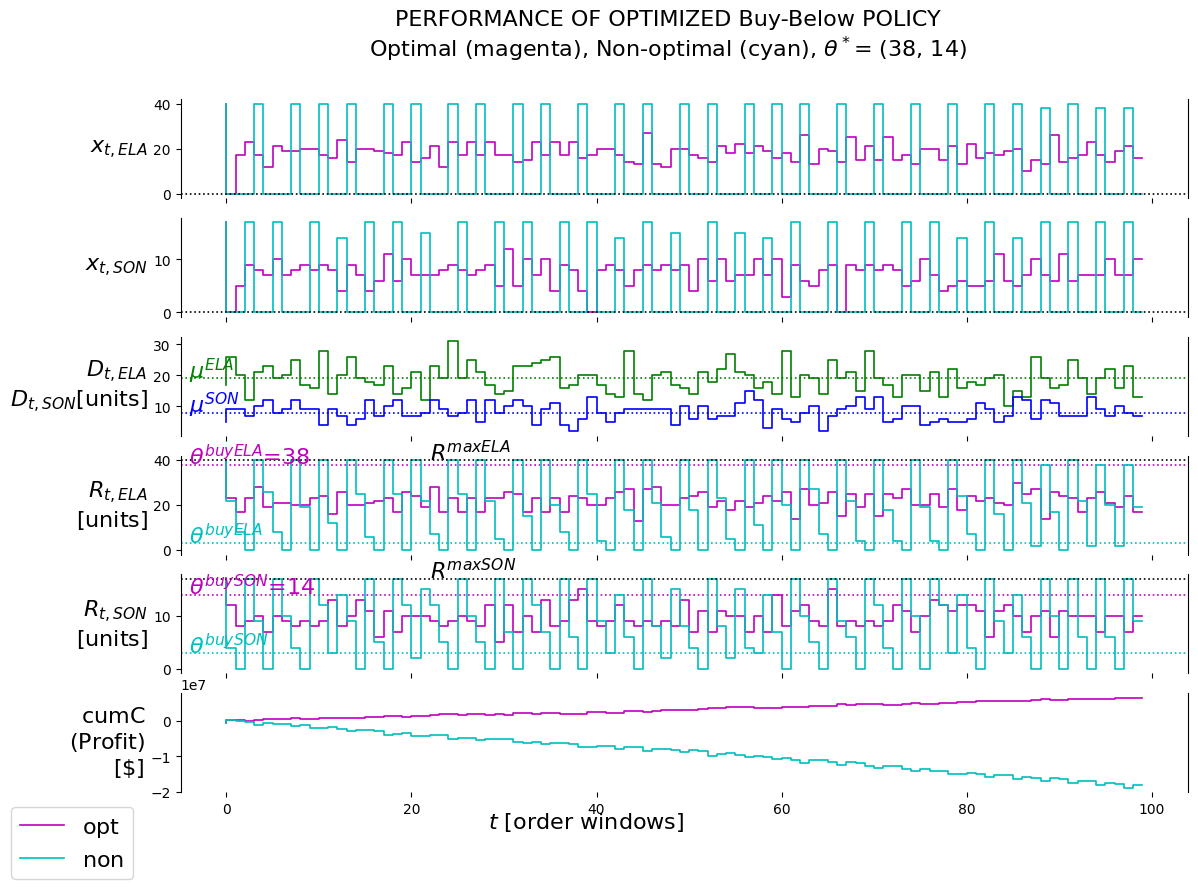
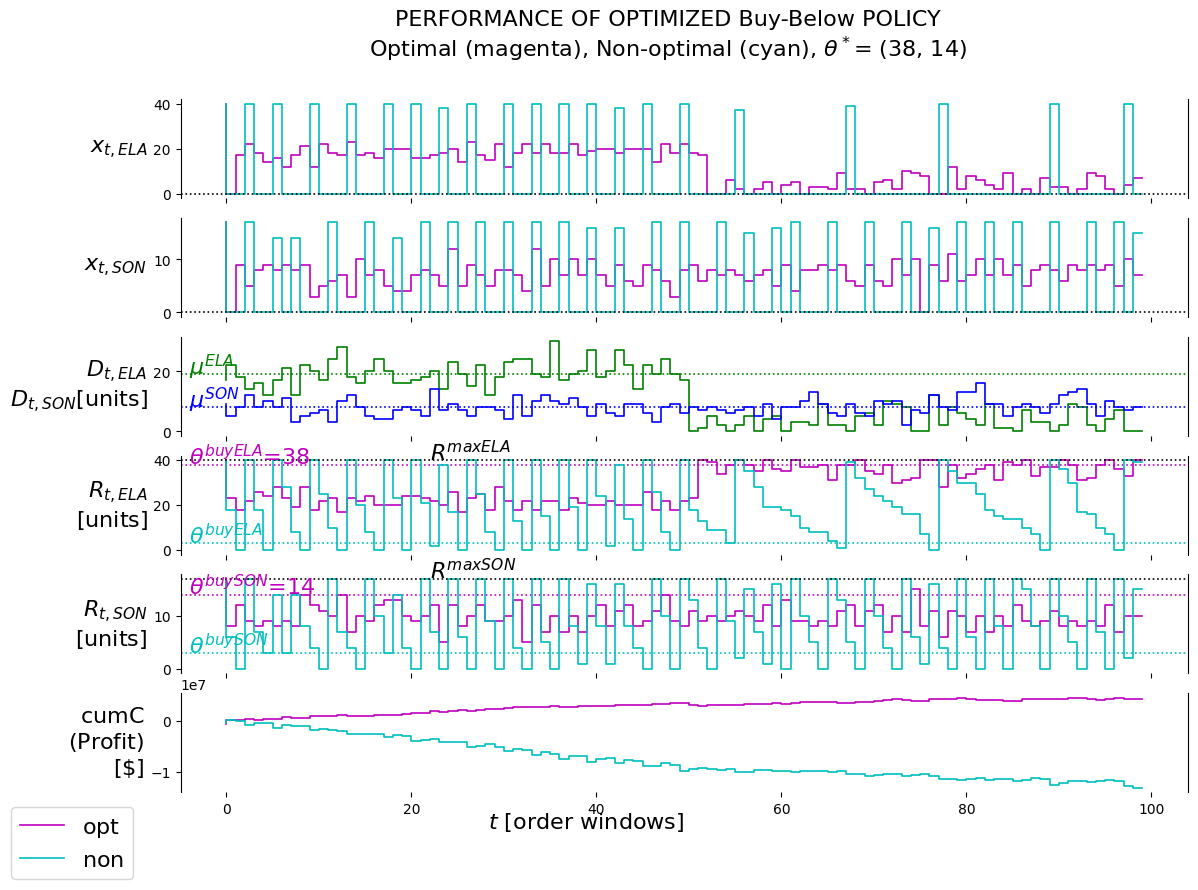
From the cumC plot we see that the cumulative reward for the optimal policy keeps on rising until the Elantra demand event happens. After the event it seems to stay flat.
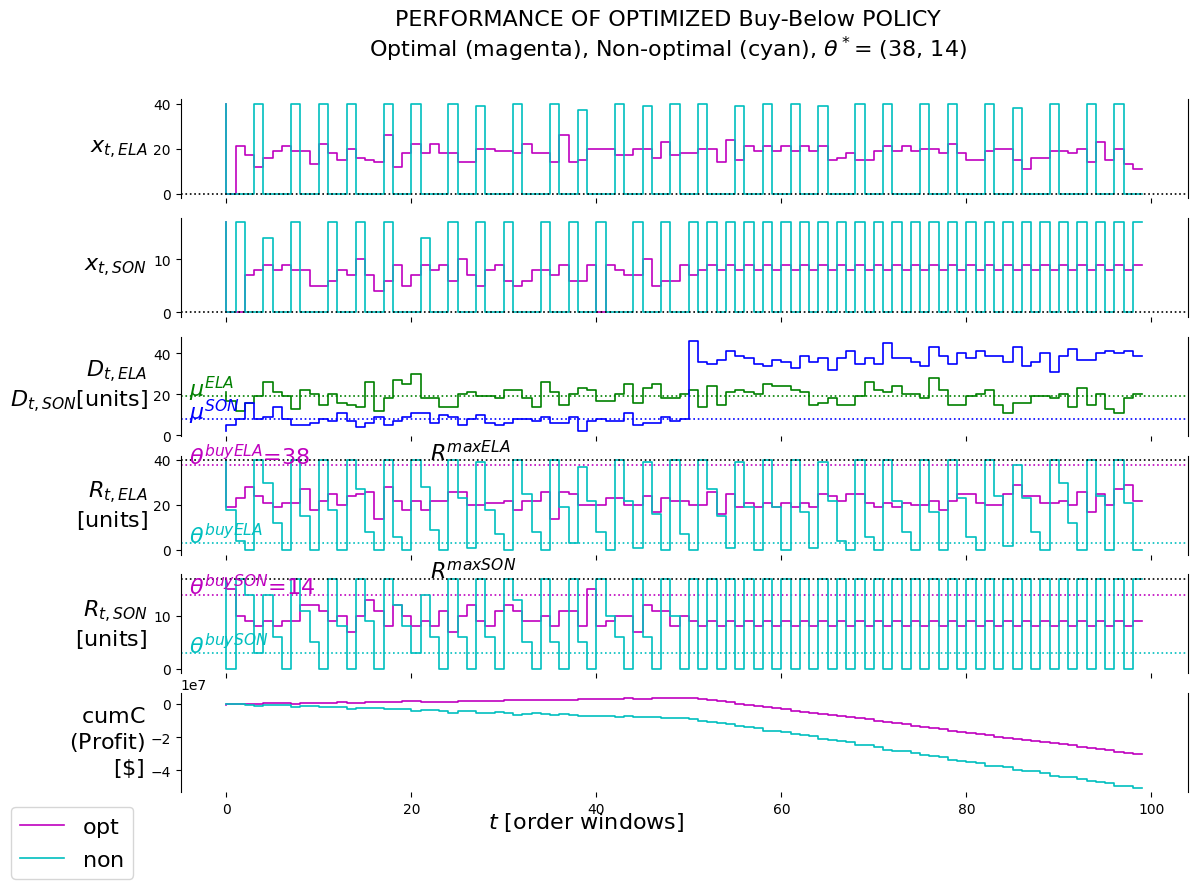
4.6.2.3 Evalutate with data having a demand event for Sonatas
From the cumC plot we see that the cumulative reward for the optimal policy keeps on rising until the Sonata demand event happens. After the event it starts to decline.
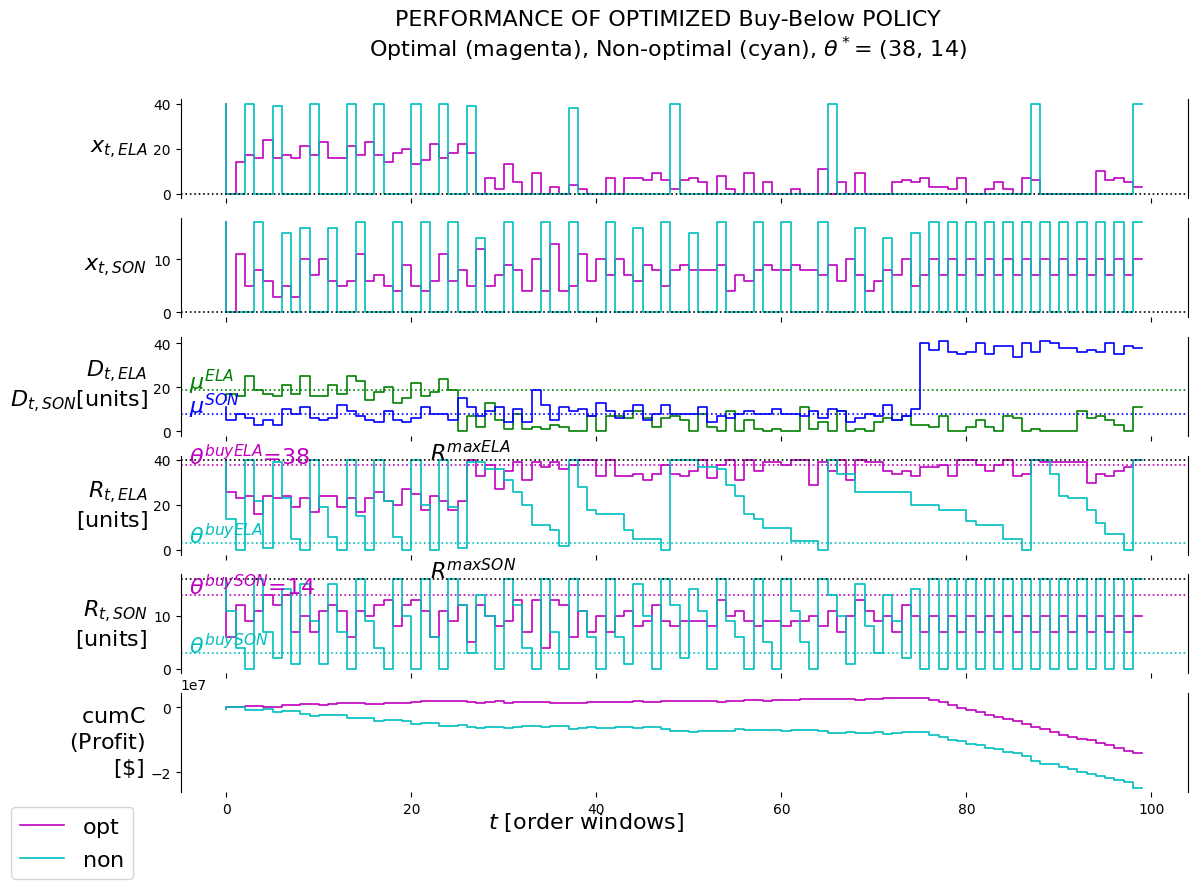
4.6.2.4 Evalutate with data having demand events for both Elantras and Sonatas
From the cumC plot we see that the cumulative reward for the optimal policy keeps on rising until the Elantra demand event happens. After the event it seems to stay flat. Then the Sonata event happens after which it starts to decline.
Overall, the presence of relative significant demand events have a negative influence on the performance of the policy. This is not surprising as the policy was learned on data without these events. Of course, a situation could be setup whereby the policy is continuously updated as the characteristics of exogenous information might change. However, in this POC the need was simply to demonstrate to the client how impactful these kinds of events can be on the performance of policies if this is not planned for and taken into account.