!python --versionPython 3.7.15It is important for an inventory manager to maintain inventory at optimal levels for each kind of product. Too much inventory incurs a holding cost while too little inventory gives rise to a stockout cost. This balancing act could be addressed by framing this problem as a Markov Decision Process. In part 1 we looked at the Markov Process (also known as a Markov Chain). Part 2 made use of a Markov Reward Process. Both of these approaches covered sequential uncertainty. In part 3, we will make use of a Markov Decision Process. We will finally be able to address sequential decisioning. To summarize the context, Markov Processes may be presented, in order of increasing complexity, in the following way:
So, in this project we will take the Markov Reward Process from the previous project, and add the concept of an action associated with each transition. This means our inventory problem has become a Markov Decision Process.
Formally, a Markov Decision Process consists of:
There are two main cost elements related to inventory items:
Note that costs may be thought of as negative rewards.
In Part 2, the decision of how much to order (ordering policy) was simple: \[ \theta=\text{max}(C - (\alpha + \beta), 0) \] where: - \(\theta \in \mathbb Z_{\ge0}\) is the order quantity - \(C \in \mathbb Z_{\ge0}\) is the space quantity - \(\alpha\) is the on-hand inventory - \(\beta\) is the on-order inventory - \((\alpha,\beta)\) is the state
This policy tends to carry maximum inventory at all time which means the risk of running out-of-stock is very low, leading to a high holding cost \(h\). It seems that this situation is to be preferred to the other extreme, a high stockout cost \(p\) because stockout costs are generally much higher than holdings costs. In other words, we want to err on the side of having too much inventory rather than too litte. But by how much should we err? What if we can reach the optimal trade-off point which will maximize our profit? This is indeed possible with a Markov Decision Process. Instead of always having a \(\theta\) \(\text{max}(C - (\alpha + \beta), 0)\), we will now have a \(\theta\) from the set \(\{0,1,2,...,\text{max}(C - (\alpha + \beta), 0)\}\). Not only will we be able to pick from a wider array of \(\theta\) values, but the picking action will happen more intelligently. Instead of just being subject to sequential uncertainty, we will be in a position to apply sequential decisioning for better outcomes.
We now have a stochastic ordering policy \[ \begin{aligned} \pi(s,a) &= \pi(a|s) \\ &= \mathbb P[A_t=a|S_t=s] \end{aligned} \] for all \(t=0,1,2,...,\) for all \(s \in \mathcal N\), for all \(a \in \mathcal A\)
At each time step \(t\), we need to pick an action \(A_t\) based upon the currently observed state \(S_t\).
Given the observed state \(S_t\) and a performed action \(A_t\), we can find the probabilities of the next state \(S_{t+1}\) and the next reward \(R_{t+1}\).
The underlying task is to maximize the expected return from each state. This amounts to maximizing the value function.
We need to express the transition probabilities of the Markov Decision Process, taking the rewards and actions into account: \[ \begin{aligned} \mathcal P_R(s,a,s',r) &= p(s',r|s,a) \\ &= \mathbb P[S_{t+1}=s',R_{t+1}=r|S_t=s,A_t=a] \end{aligned} \] for \(t=0,1,2,...\), for all \(s \in \mathcal N, a \in \mathcal A,r \in \mathcal D, s' \in \mathcal S\), such that \[ \sum_{s' \in \mathcal S} \sum_{r \in \mathcal D}\mathcal P_R(s,a,s'r) = 1 \] for all \(s \in \mathcal N, a \in \mathcal A\)
As before, we have the constraints:
NO LONGER: \[ \theta=\text{max}(C - (\alpha + \beta), 0) \]
BUT: \[ \pi^* \] which is associated with the optimal value function
\[ V^*(s) = \underset{\pi \in \Pi}{\text{max}} V^\pi(s) \quad \text{for all} \quad s \in \mathcal N \] where \(\Pi\) is the set of stationary (stochastic) policies over the spaces of \(\mathcal N\) and \(\mathcal A\).
Capture any overnight holding cost
Receive items at 06h00 (if there was an order 36 hours ago)
Open the store at 08h00
Experience random demand according to the demand probability above
Capture any stockout cost due to missed demand
Close the store at 18h00 and
observe the state \[ S_{t+1}=(\text{max}(\alpha+\beta-i,0), \text{max}(C-(\alpha+\beta),0)) \qquad \text{(4.1)} \]
capture the expected reward, \(\mathcal R_T \qquad \text{(4.2) and (4.3)}\)
We use the reward transition function, \(\mathcal R_T\) to calculate the rewards. There are two situations to consider: - the on-hand, \(\alpha\) of \(S_{t+1} > 0\) (i.e. the next state’s on-hand inventory is greater than zero) - \(\mathcal R_T((\alpha,\beta),(\alpha+\beta-i,C-(\alpha+\beta)))=-h\alpha \quad\text{for } 0\le i \le \alpha+\beta-1 \quad \text{(4.2)}\) - the on-hand, \(\alpha\) of \(S_{t+1} = 0\) (i.e. the next state’s on-hand inventory is zero) - \(\mathcal R_T((\alpha,\beta),(0,C-(\alpha+\beta)))=-h\alpha -p(\lambda(1-F(\alpha+\beta-1))-(\alpha+\beta)(1-F(\alpha+\beta))) \quad \text{(4.3)}\)
where
- $h$ is the overnight holding cost
- $p$ is the day's stockout cost!python --versionPython 3.7.15We make use of the approach followed in http://web.stanford.edu/class/cme241/.
import operator
from typing import Tuple, Dict, Mapping
import numpy as np
from pprint import pprint
from dataclasses import dataclass
from scipy.stats import poisson
import matplotlib.pyplot as plt
import graphvizfrom __future__ import annotations
from abc import ABC, abstractmethod
from collections import Counter, defaultdict
from dataclasses import dataclass
import numpy as np
import random
from typing import (Callable, DefaultDict, Dict, Generic, Iterator, Iterable,
Generic, Mapping, Optional, Sequence, Tuple, TypeVar, Set)A = TypeVar('A')
B = TypeVar('B')class Distribution(ABC, Generic[A]):
@abstractmethod
def sample(self) -> A:
pass
def sample_n(self, n: int) -> Sequence[A]:
return [self.sample() for _ in range(n)]
@abstractmethod
def expectation(
self,
f: Callable[[A], float]
) -> float:
pass
def map(
self,
f: Callable[[A], B]
) -> Distribution[B]:
return SampledDistribution(lambda: f(self.sample()))
def apply(
self,
f: Callable[[A], Distribution[B]]
) -> Distribution[B]:
def sample():
a = self.sample()
b_dist = f(a)
return b_dist.sample()
return SampledDistribution(sample)class SampledDistribution(Distribution[A]):
sampler: Callable[[], A]
expectation_samples: int
def __init__(
self,
sampler: Callable[[], A],
expectation_samples: int = 10000
):
self.sampler = sampler
self.expectation_samples = expectation_samples
def sample(self) -> A:
return self.sampler()
def expectation(
self,
f: Callable[[A], float]
) -> float:
return sum(f(self.sample()) for _ in
range(self.expectation_samples))/self.expectation_samplesclass FiniteDistribution(Distribution[A], ABC):
@abstractmethod
def table(self) -> Mapping[A, float]:
pass
def probability(self, outcome: A) -> float:
return self.table()[outcome]
def map(self, f: Callable[[A], B]) -> FiniteDistribution[B]:
result: Dict[B, float] = defaultdict(float)
for x, p in self:
result[f(x)] += p
return Categorical(result)
def sample(self) -> A:
outcomes = list(self.table().keys())
weights = list(self.table().values())
return random.choices(outcomes, weights=weights)[0]
def expectation(self, f: Callable[[A], float]) -> float:
return sum(p * f(x) for x, p in self)
def __iter__(self) -> Iterator[Tuple[A, float]]:
return iter(self.table().items())
def __eq__(self, other: object) -> bool:
if isinstance(other, FiniteDistribution):
return self.table() == other.table()
else:
return False
def __repr__(self) -> str:
return repr(self.table())class Choose(FiniteDistribution[A]):
options: Sequence[A]
_table: Optional[Mapping[A, float]] = None
def __init__(self, options: Iterable[A]):
self.options = list(options)
def sample(self) -> A:
return random.choice(self.options)
def table(self) -> Mapping[A, float]:
if self._table is None:
counter = Counter(self.options)
length = len(self.options)
self._table = {x: counter[x] / length for x in counter}
return self._table
def probability(self, outcome: A) -> float:
return self.table().get(outcome, 0.0)class Categorical(FiniteDistribution[A]):
probabilities: Mapping[A, float]
def __init__(self, distribution: Mapping[A, float]):
total = sum(distribution.values())
# Normalize probabilities to sum to 1
self.probabilities = {outcome: probability/total
for outcome, probability in distribution.items()}
def table(self) -> Mapping[A, float]:
return self.probabilities
def probability(self, outcome: A) -> float:
return self.probabilities.get(outcome, 0.)@dataclass(frozen=True)
class Constant(FiniteDistribution[A]):
value: A
def sample(self) -> A:
return self.value
def table(self) -> Mapping[A, float]:
return {self.value: 1}
def probability(self, outcome: A) -> float:
return 1. if outcome == self.value else 0.S = TypeVar('S')
X = TypeVar('X')
class State(ABC, Generic[S]):
state: S
def on_non_terminal(
self,
f: Callable[[NonTerminal[S]], X],
default: X
) -> X:
if isinstance(self, NonTerminal):
return f(self)
else:
return default@dataclass(frozen=True)
class Terminal(State[S]):
state: S@dataclass(frozen=True)
class NonTerminal(State[S]):
state: S
def __eq__(self, other):
return self.state == other.state
def __lt__(self, other):
return self.state < other.stateclass MarkovProcess(ABC, Generic[S]):
#. transition from this state
@abstractmethod
def transition(
self,
state: NonTerminal[S]
) -> Distribution[State[S]]: #s'|s or s->s'
pass
def simulate(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[State[S]]:
state: State[S] = start_state_distribution.sample()
yield state
while isinstance(state, NonTerminal):
state = self.transition(state).sample()
yield state
def traces(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[Iterable[State[S]]]:
while True:
yield self.simulate(start_state_distribution)@dataclass(frozen=True)
class TransitionStep(Generic[S]):
state: NonTerminal[S]
next_state: State[S]
reward: float
def add_return(self, γ: float, return_: float) -> ReturnStep[S]:
return ReturnStep( # s -> s'r
self.state,
self.next_state,
self.reward,
return_=self.reward + γ*return_
)@dataclass(frozen=True)
class ReturnStep(TransitionStep[S]):
return_: float
class MarkovRewardProcess(MarkovProcess[S]):
#. transition from this state
def transition(self, state: NonTerminal[S]) -> Distribution[State[S]]: #s'|s or s->s'
distribution = self.transition_reward(state)
def next_state(distribution=distribution):
next_s, _ = distribution.sample() #.ignores reward
return next_s
return SampledDistribution(next_state)
@abstractmethod
def transition_reward(#. transition from this state
self,
state: NonTerminal[S]
) -> Distribution[Tuple[State[S], float]]: #s',r|s or s->s',r
pass
def simulate_reward(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[TransitionStep[S]]:
state: State[S] = start_state_distribution.sample()
reward: float = 0.
while isinstance(state, NonTerminal):
next_distribution = self.transition_reward(state)
next_state, reward = next_distribution.sample()
yield TransitionStep(state, next_state, reward) # s -> s'r
state = next_state
def reward_traces(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[Iterable[TransitionStep[S]]]:
while True:
yield self.simulate_reward(start_state_distribution)Transition = Mapping[NonTerminal[S], FiniteDistribution[State[S]]]class FiniteMarkovProcess(MarkovProcess[S]):
non_terminal_states: Sequence[NonTerminal[S]]
transition_map: Transition[S]
def __init__(self, transition_map: Mapping[S, FiniteDistribution[S]]):
non_terminals: Set[S] = set(transition_map.keys())
self.transition_map = {
NonTerminal(s): Categorical(
{(NonTerminal(s1) if s1 in non_terminals else Terminal(s1)): p
for s1, p in v}
) for s, v in transition_map.items()
}
self.non_terminal_states = list(self.transition_map.keys())
def __repr__(self) -> str:
display = ""
for s, d in self.transition_map.items():
display += f"From State {s.state}:\n"
for s1, p in d:
opt = "Terminal " if isinstance(s1, Terminal) else ""
display += f" To {opt}State {s1.state} with Probability {p:.3f}\n"
return display
def get_transition_matrix(self) -> np.ndarray:
sz = len(self.non_terminal_states)
mat = np.zeros((sz, sz))
for i, s1 in enumerate(self.non_terminal_states):
for j, s2 in enumerate(self.non_terminal_states):
mat[i, j] = self.transition(s1).probability(s2)
return mat
def transition(self, state: NonTerminal[S]) -> FiniteDistribution[State[S]]:
return self.transition_map[state]
def get_stationary_distribution(self) -> FiniteDistribution[S]:
eig_vals, eig_vecs = np.linalg.eig(self.get_transition_matrix().T)
index_of_first_unit_eig_val = np.where(
np.abs(eig_vals - 1) < 1e-8)[0][0]
eig_vec_of_unit_eig_val = np.real(
eig_vecs[:, index_of_first_unit_eig_val])
return Categorical({
self.non_terminal_states[i].state: ev
for i, ev in enumerate(eig_vec_of_unit_eig_val /
sum(eig_vec_of_unit_eig_val))
})
def display_stationary_distribution(self):
pprint({
s: round(p, 3)
for s, p in self.get_stationary_distribution()
})
def generate_image(self) -> graphviz.Digraph:
d = graphviz.Digraph()
for s in self.transition_map.keys():
#d.node(str(s)) #.
d.node(f"{(s.state.on_hand, s.state.on_order)}") #.
for s, v in self.transition_map.items():
for s1, p in v:
#d.edge(str(s), str(s1), label=str(p)) #.
#d.edge(str(s), str(s1), label=f'{p:.3f}') #.
d.edge(f"{(s.state.on_hand, s.state.on_order)}", f"{(s1.state.on_hand, s1.state.on_order)}", label=f'{p:.2f}') #.
return dStateReward = FiniteDistribution[Tuple[State[S], float]] #. s'r
RewardTransition = Mapping[NonTerminal[S], StateReward[S]] #. s->s'rclass FiniteMarkovRewardProcess(FiniteMarkovProcess[S], MarkovRewardProcess[S]):
transition_reward_map: RewardTransition[S]
reward_function_vec: np.ndarray
def __init__(
self,
transition_reward_map: Mapping[S, FiniteDistribution[Tuple[S, float]]]
):
transition_map: Dict[S, FiniteDistribution[S]] = {}
for state, trans in transition_reward_map.items():
probabilities: Dict[S, float] = defaultdict(float)
for (next_state, _), probability in trans:
probabilities[next_state] += probability
transition_map[state] = Categorical(probabilities)
super().__init__(transition_map)
nt: Set[S] = set(transition_reward_map.keys())
self.transition_reward_map = {
NonTerminal(s): Categorical(
{(NonTerminal(s1) if s1 in nt else Terminal(s1), r): p
for (s1, r), p in v}
) for s, v in transition_reward_map.items()
}
self.reward_function_vec = np.array([
sum(probability * reward for (_, reward), probability in
self.transition_reward_map[state])
for state in self.non_terminal_states
])
def __repr__(self) -> str:
display = ""
for s, d in self.transition_reward_map.items():
display += f"From State {s.state}:\n"
for (s1, r), p in d:
opt = "Terminal " if isinstance(s1, Terminal) else ""
display +=\
f" To [{opt}State {s1.state} and Reward {r:.3f}]"\
+ f" with Probability {p:.3f}\n"
return display
def transition_reward(self, state: NonTerminal[S]) -> StateReward[S]:
return self.transition_reward_map[state]
def get_value_function_vec(self, gamma: float) -> np.ndarray:
return np.linalg.solve(
np.eye(len(self.non_terminal_states)) -
gamma * self.get_transition_matrix(),
self.reward_function_vec
)
def display_reward_function(self):
pprint({
self.non_terminal_states[i]: round(r, 3)
for i, r in enumerate(self.reward_function_vec)
})
def display_value_function(self, gamma: float):
pprint({
self.non_terminal_states[i]: round(v, 3)
for i, v in enumerate(self.get_value_function_vec(gamma))
})class MarkovDecisionProcess(ABC, Generic[S, A]):
def apply_policy(self, policy: Policy[S, A]) -> MarkovRewardProcess[S]: #.implied MRP
mdp = self
class RewardProcess(MarkovRewardProcess[S]):
def transition_reward(
self,
state: NonTerminal[S]
) -> Distribution[Tuple[State[S], float]]:
actions: Distribution[A] = policy.act(state)
#.return actions.apply(lambda a: mdp.step(state, a))
return actions.apply(lambda a: mdp.transition_action(state, a))#.
return RewardProcess()
@abstractmethod
def actions(self, state: NonTerminal[S]) -> Iterable[A]:
pass
@abstractmethod
def transition_action(#. transition from this state,action (called transition() elsewhere)
self,
state: NonTerminal[S],
action: A
) -> Distribution[Tuple[State[S], float]]:
pass
def simulate_action(#.
self,
#.start_states: Distribution[NonTerminal[S]],
start_state_distribution: Distribution[NonTerminal[S]],#.
policy: Policy[S, A]
) -> Iterable[TransitionStep[S, A]]:
#.state: State[S] = start_states.sample()
state: State[S] = start_state_distribution.sample()#.
while isinstance(state, NonTerminal):
action_distribution = policy.act(state)
action = action_distribution.sample()
#.next_distribution = self.step(state, action)
next_distribution = self.transition_action(state, action)#.
next_state, reward = next_distribution.sample()
yield TransitionStep(state, action, next_state, reward) # sa -> s'r
state = next_state
def action_traces(
self,
start_states: Distribution[NonTerminal[S]],
policy: Policy[S, A]
) -> Iterable[Iterable[TransitionStep[S, A]]]:
while True:
#.yield self.simulate_actions(start_states, policy)
yield self.simulate_action(start_states, policy)#.StateReward = FiniteDistribution[Tuple[State[S], float]] #. s'rActionMapping = Mapping[A, StateReward[S]] #. a->s'r
StateActionMapping = Mapping[NonTerminal[S], ActionMapping[A, S]] #. s->(a->s'r)class FiniteMarkovDecisionProcess(MarkovDecisionProcess[S, A]):
mapping: StateActionMapping[S, A]
non_terminal_states: Sequence[NonTerminal[S]]
def __init__(
self,
mapping: Mapping[S, Mapping[A, FiniteDistribution[Tuple[S, float]]]]
):
non_terminals: Set[S] = set(mapping.keys())
self.mapping = {NonTerminal(s): {a: Categorical(
{(NonTerminal(s1) if s1 in non_terminals else Terminal(s1), r): p
for (s1, r), p in v}
) for a, v in d.items()} for s, d in mapping.items()}
self.non_terminal_states = list(self.mapping.keys())
def __repr__(self) -> str:
display = ""
for s, d in self.mapping.items():
display += f"From State {s.state}:\n"
for a, d1 in d.items():
display += f" With Action {a}:\n"
for (s1, r), p in d1:
opt = "Terminal " if isinstance(s1, Terminal) else ""
display += f" To [{opt}State {s1.state} and "\
+ f"Reward {r:.3f}] with Probability {p:.3f}\n"
return display
def transition_action(self, state: NonTerminal[S], action: A) -> StateReward[S]:#. transition from this state,action (called transition() elsewhere)
action_map: ActionMapping[A, S] = self.mapping[state]
#.return action_map[action]
return self.action_map[action]#.
def apply_finite_policy(self, policy: FinitePolicy[S, A])\
-> FiniteMarkovRewardProcess[S]:
transition_mapping: Dict[S, FiniteDistribution[Tuple[S, float]]] = {}
for state in self.mapping:
action_map: ActionMapping[A, S] = self.mapping[state]
outcomes: DefaultDict[Tuple[S, float], float]\
= defaultdict(float)
actions = policy.act(state)
for action, p_action in actions:
for (s1, r), p in action_map[action]:
outcomes[(s1.state, r)] += p_action * p
transition_mapping[state.state] = Categorical(outcomes)
return FiniteMarkovRewardProcess(transition_mapping)
def actions(self, state: NonTerminal[S]) -> Iterable[A]:
return self.mapping[state].keys()A = TypeVar('A')
S = TypeVar('S')
class Policy(ABC, Generic[S, A]):
@abstractmethod
def act(self, state: NonTerminal[S]) -> Distribution[A]:
pass@dataclass(frozen=True)
class FinitePolicy(Policy[S, A]):
policy_map: Mapping[S, FiniteDistribution[A]]
def __repr__(self) -> str:
display = ""
for s, d in self.policy_map.items():
display += f"For State {s}:\n"
for a, p in d:
display += f" Do Action {a} with Probability {p:.3f}\n"
return display
def act(self, state: NonTerminal[S]) -> FiniteDistribution[A]:
return self.policy_map[state.state]class FiniteDeterministicPolicy(FinitePolicy[S, A]):
action_for: Mapping[S, A]
def __init__(self, action_for: Mapping[S, A]):
self.action_for = action_for
super().__init__(policy_map={s: Constant(a) for s, a in
self.action_for.items()})
def __repr__(self) -> str:
display = ""
for s, a in self.action_for.items():
display += f"For State {s}: Do Action {a}\n"
return display@dataclass(frozen=True)
class InventoryState:
on_hand: int
on_order: int
def inventory_position(self) -> int:
return self.on_hand + self.on_orderInvOrderMapping = Mapping[
InventoryState,
Mapping[int, Categorical[Tuple[InventoryState, float]]]
]class SimpleInventoryMDPCap(FiniteMarkovDecisionProcess[InventoryState, int]):
def __init__(
self,
capacity: int,
poisson_lambda: float,
holding_cost: float,
stockout_cost: float
):
self.capacity: int = capacity
self.poisson_lambda: float = poisson_lambda
self.holding_cost: float = holding_cost
self.stockout_cost: float = stockout_cost
self.poisson_distr = poisson(poisson_lambda)
super().__init__(self.get_action_transition_reward_map())
def get_action_transition_reward_map(self) -> InvOrderMapping:
d: Dict[InventoryState, Dict[int, Categorical[Tuple[InventoryState,
float]]]] = {}
for alpha in range(self.capacity + 1): #alpha 0 to C
for beta in range(self.capacity + 1 - alpha): #beta 0 to C - alpha
state: InventoryState = InventoryState(alpha, beta)
ip: int = state.inventory_position()
base_reward: float = - self.holding_cost*alpha
d1: Dict[int, Categorical[Tuple[InventoryState, float]]] = {}
for order in range(self.capacity - ip + 1):
sr_probs_dict: Dict[Tuple[InventoryState, float], float] =\
{(InventoryState(ip - i, order), base_reward):
self.poisson_distr.pmf(i) for i in range(ip)}
probability: float = 1 - self.poisson_distr.cdf(ip - 1)
reward: float = base_reward - self.stockout_cost*\
(probability*(self.poisson_lambda - ip) +
ip*self.poisson_distr.pmf(ip))
sr_probs_dict[(InventoryState(0, order), reward)] = probability
d1[order] = Categorical(sr_probs_dict)
d[state] = d1
return ditem_capacity = 2
item_poisson_lambda = 1.0
item_holding_cost = 1.0
item_stockout_cost = 10.0
item_gamma = 0.9si_mdp: FiniteMarkovDecisionProcess[InventoryState, int] =\
SimpleInventoryMDPCap(
capacity=item_capacity,
poisson_lambda=item_poisson_lambda,
holding_cost=item_holding_cost,
stockout_cost=item_stockout_cost
)
print("MDP Transition Map")
print("------------------")
print(si_mdp)MDP Transition Map
------------------
From State InventoryState(on_hand=0, on_order=0):
With Action 0:
To [State InventoryState(on_hand=0, on_order=0) and Reward -10.000] with Probability 1.000
With Action 1:
To [State InventoryState(on_hand=0, on_order=1) and Reward -10.000] with Probability 1.000
With Action 2:
To [State InventoryState(on_hand=0, on_order=2) and Reward -10.000] with Probability 1.000
From State InventoryState(on_hand=0, on_order=1):
With Action 0:
To [State InventoryState(on_hand=1, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -3.679] with Probability 0.632
With Action 1:
To [State InventoryState(on_hand=1, on_order=1) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -3.679] with Probability 0.632
From State InventoryState(on_hand=0, on_order=2):
With Action 0:
To [State InventoryState(on_hand=2, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -1.036] with Probability 0.264
From State InventoryState(on_hand=1, on_order=0):
With Action 0:
To [State InventoryState(on_hand=1, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -4.679] with Probability 0.632
With Action 1:
To [State InventoryState(on_hand=1, on_order=1) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -4.679] with Probability 0.632
From State InventoryState(on_hand=1, on_order=1):
With Action 0:
To [State InventoryState(on_hand=2, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -2.036] with Probability 0.264
From State InventoryState(on_hand=2, on_order=0):
With Action 0:
To [State InventoryState(on_hand=2, on_order=0) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -3.036] with Probability 0.264
fdp: FiniteDeterministicPolicy[InventoryState, int] = \
FiniteDeterministicPolicy(
{
InventoryState(alpha, beta): item_capacity - (alpha + beta)
for alpha in range(item_capacity + 1)
for beta in range(item_capacity + 1 - alpha)
}
)
print("Deterministic Policy Map")
print("------------------------")
print(fdp)Deterministic Policy Map
------------------------
For State InventoryState(on_hand=0, on_order=0): Do Action 2
For State InventoryState(on_hand=0, on_order=1): Do Action 1
For State InventoryState(on_hand=0, on_order=2): Do Action 0
For State InventoryState(on_hand=1, on_order=0): Do Action 1
For State InventoryState(on_hand=1, on_order=1): Do Action 0
For State InventoryState(on_hand=2, on_order=0): Do Action 0
implied_mrp: FiniteMarkovRewardProcess[InventoryState] =\
si_mdp.apply_finite_policy(fdp)print("Implied MP Transition Map")
print("--------------")
print(FiniteMarkovProcess(
{
s.state: Categorical(
{
s1.state: p for s1, p in v.table().items()
}
)
for s, v in implied_mrp.transition_map.items()
}
))Implied MP Transition Map
--------------
From State InventoryState(on_hand=0, on_order=0):
To State InventoryState(on_hand=0, on_order=2) with Probability 1.000
From State InventoryState(on_hand=0, on_order=1):
To State InventoryState(on_hand=1, on_order=1) with Probability 0.368
To State InventoryState(on_hand=0, on_order=1) with Probability 0.632
From State InventoryState(on_hand=0, on_order=2):
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.368
To State InventoryState(on_hand=0, on_order=0) with Probability 0.264
From State InventoryState(on_hand=1, on_order=0):
To State InventoryState(on_hand=1, on_order=1) with Probability 0.368
To State InventoryState(on_hand=0, on_order=1) with Probability 0.632
From State InventoryState(on_hand=1, on_order=1):
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.368
To State InventoryState(on_hand=0, on_order=0) with Probability 0.264
From State InventoryState(on_hand=2, on_order=0):
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.368
To State InventoryState(on_hand=0, on_order=0) with Probability 0.264
print("Implied MRP Transition Reward Map")
print("---------------------")
print(implied_mrp)Implied MRP Transition Reward Map
---------------------
From State InventoryState(on_hand=0, on_order=0):
To [State InventoryState(on_hand=0, on_order=2) and Reward -10.000] with Probability 1.000
From State InventoryState(on_hand=0, on_order=1):
To [State InventoryState(on_hand=1, on_order=1) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -3.679] with Probability 0.632
From State InventoryState(on_hand=0, on_order=2):
To [State InventoryState(on_hand=2, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -1.036] with Probability 0.264
From State InventoryState(on_hand=1, on_order=0):
To [State InventoryState(on_hand=1, on_order=1) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -4.679] with Probability 0.632
From State InventoryState(on_hand=1, on_order=1):
To [State InventoryState(on_hand=2, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -2.036] with Probability 0.264
From State InventoryState(on_hand=2, on_order=0):
To [State InventoryState(on_hand=2, on_order=0) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=0) and Reward -3.036] with Probability 0.264
print("Implied MP Stationary Distribution")
print("-----------------------")
implied_mrp.display_stationary_distribution()
print()Implied MP Stationary Distribution
-----------------------
{InventoryState(on_hand=0, on_order=0): 0.117,
InventoryState(on_hand=0, on_order=1): 0.279,
InventoryState(on_hand=1, on_order=1): 0.162,
InventoryState(on_hand=0, on_order=2): 0.117,
InventoryState(on_hand=2, on_order=0): 0.162,
InventoryState(on_hand=1, on_order=0): 0.162}
print("Implied MRP Reward Function")
print("---------------")
implied_mrp.display_reward_function()
print()Implied MRP Reward Function
---------------
{NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -2.325,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -10.0,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -1.274,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -3.325,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -2.274,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -0.274}
print("Implied MRP Value Function")
print("--------------")
implied_mrp.display_value_function(gamma=item_gamma)
print()Implied MRP Value Function
--------------
{NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.932,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -35.511,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -29.345,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.932,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -30.345,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -28.345}
# hide
# from rl.dynamic_programming_ANNO import evaluate_mrp_result# hide
from rl.iterate_ANNO import converged, iterate, converge #.#
#. Values provider
def evaluate_mrp(
mrp: FiniteMarkovRewardProcess[S],
gamma: float
) -> Iterator[np.ndarray]:
def update(v: np.ndarray) -> np.ndarray: #. Bellman Policy Operator B^pi
return mrp.reward_function_vec + \
gamma*mrp.get_transition_matrix().dot(v)
v_0: np.ndarray = np.zeros(len(mrp.non_terminal_states))
return iterate(update, v_0) #. m NonTerminals in v#
#. Done test
DEFAULT_TOLERANCE = 1e-5
def almost_equal_np_arrays(
v1: np.ndarray,
v2: np.ndarray,
tolerance: float = DEFAULT_TOLERANCE
) -> bool:
return max(abs(v1 - v2)) < tolerance#
# fixed number of values
gen = evaluate_mrp(mrp=implied_mrp, gamma=item_gamma); gen
vals = [next(gen) for i in range(3)]; vals[array([0., 0., 0., 0., 0., 0.]),
array([-10. , -2.32544158, -0.27385506, -3.32544158,
-1.27385506, -2.27385506]),
array([-10.24646956, -4.07016765, -4.50590463, -5.07016765,
-5.50590463, -6.50590463])]#
# values until done
v_star_values: np.ndarray = converge(
values=evaluate_mrp(mrp=implied_mrp, gamma=item_gamma),
done=almost_equal_np_arrays
)
v_star_values<generator object converge at 0x7fd2bbcf7bd0>v_star_values_lst = list(v_star_values); #v_star_values_lstv_star_values_lst[2]array([-10.24646956, -4.07016765, -4.50590463, -5.07016765,
-5.50590463, -6.50590463])list_of_tuples = [tuple(el) for el in v_star_values_lst]; #list_tupleslist_of_tuples[7](-21.33253398537216,
-13.75395174507661,
-14.16070385432128,
-14.75395174507661,
-15.16070385432128,
-16.16070385432128)list_of_state_values = [list(tup) for tup in zip(*list_of_tuples)]; #list_of_state_valuesfig,axs = plt.subplots(figsize=(13,10))
axs.set_xlabel('Iterations', fontsize=20)
axs.set_title(f'Convergence of state values during Policy Evaluation', fontsize=24)
for i in range(len(list_of_state_values)):
axs.plot(list_of_state_values[i], label=f'{implied_mrp.non_terminal_states[i].state}')
axs.legend(fontsize=20);
#
#. Converged value
def evaluate_mrp_result(
mrp: FiniteMarkovRewardProcess[S],
gamma: float
) -> V[S]:
v_star: np.ndarray = converged(
values=evaluate_mrp(mrp=mrp, gamma=gamma),
done=almost_equal_np_arrays
)
return {s: v_star[i] for i, s in enumerate(mrp.non_terminal_states)}print("Implied MRP Policy Evaluation Value Function")
print("--------------")
# pprint(evaluate_mrp_result(implied_mrp, gamma=item_gamma))
result = evaluate_mrp_result(implied_mrp, gamma=item_gamma)
pprint(result)
print()Implied MRP Policy Evaluation Value Function
--------------
{NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.93217421014731,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -35.510518165628724,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -29.345029758390766,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.93217421014731,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -30.345029758390766,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -28.345029758390766}
#
# A representation of a value function for a finite MDP with states of type S
V = Mapping[NonTerminal[S], float] #. V(s)
def extended_vf(v: V[S], s: State[S]) -> float: #. W(s')
def non_terminal_vf(st: NonTerminal[S], v=v) -> float:
return v[st]
return s.on_non_terminal(non_terminal_vf, 0.0)def greedy_policy_from_vf( #. Improvement: pi = G(V)
mdp: FiniteMarkovDecisionProcess[S, A],
vf: V[S],
gamma: float
) -> FiniteDeterministicPolicy[S, A]:
greedy_policy_dict: Dict[S, A] = {}
for s in mdp.non_terminal_states: #. (RJ5.4)
# s1r[0] is s'
# s1r[1] is r
q_values: Iterator[Tuple[A, float]] = \
( #generator comprehension because of (), i.e. not []
(
a,
mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + gamma*extended_vf(vf, s1r[0]))
)
for a in mdp.actions(s)
)
greedy_policy_dict[s.state] = \
max(q_values, key=operator.itemgetter(1))[0] #. argmax_a of (RJ5.4)
return FiniteDeterministicPolicy(greedy_policy_dict)#
# ===study greedy_policy_from_vf()#
# ======study si_mdp.mappings = si_mdp.non_terminal_states[3]#
# each action for this state maps to a StateReward, s'r,
# which is a FiniteDistribution of s'r with probabilities
pprint( si_mdp.mapping[s] ){0: {(NonTerminal(state=InventoryState(on_hand=1, on_order=0)), -1.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -4.678794411714423): 0.6321205588285577},
1: {(NonTerminal(state=InventoryState(on_hand=1, on_order=1)), -1.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=1)), -4.678794411714423): 0.6321205588285577}}#
# let's pick a=1:
a = 1#
# this is the FiniteDistribution of s'r s (plural) for this (s,a):
fd = si_mdp.mapping[s][a]; fd{(NonTerminal(state=InventoryState(on_hand=1, on_order=1)), -1.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=1)), -4.678794411714423): 0.6321205588285577}#
# just for sake of interest:# s'r values
[it[0] for it in fd.table().items()][(NonTerminal(state=InventoryState(on_hand=1, on_order=1)), -1.0),
(NonTerminal(state=InventoryState(on_hand=0, on_order=1)),
-4.678794411714423)]#
# probabilities
[it[1] for it in fd.table().items()][0.3678794411714424, 0.6321205588285577]#
# ------study si_mdp.mapping#
# expectation of the function in (RJ5.4)
# e.g. E[f(x)] = E[2x + 1] = Sum_x{ f(x)p(x) }
# s1r[0] is s'
# s1r[1] is r
v_0: V[S] = {s: 0.0 for s in si_mdp.non_terminal_states}
si_mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v_0, s1r[0]))-3.3254415793482965#
# get the (a, expectation) for all the actions of state ssi_mdp.actions(s)dict_keys([0, 1])s = si_mdp.non_terminal_states[3]
v_0: V[S] = {s: 0.0 for s in si_mdp.non_terminal_states}
q_values = \
( #generator comprehension because of (), i.e. not []
(
a,
si_mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v_0, s1r[0]))
)
for a in si_mdp.actions(s)
)
q_values #we don't use an iterator here for simplicity<generator object <genexpr> at 0x7fd2bbd4f150># hide
# list( q_values ) #consumes the valuesmax(q_values, key=operator.itemgetter(1))[0] #. argmax_a of (RJ5.4)0#
# create the greedy_policy_dictv_0: V[S] = {s: 0.0 for s in si_mdp.non_terminal_states}
greedy_policy_dict: Dict[S, A] = {}
for s in si_mdp.non_terminal_states:
# s1r[0] is s'
# s1r[1] is r
q_values: Iterator[Tuple[A, float]] = \
( #generator comprehension because of (), i.e. not []
(
a,
si_mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v_0, s1r[0]))
)
for a in si_mdp.actions(s)
)
greedy_policy_dict[s.state] = \
max(q_values, key=operator.itemgetter(1))[0] #. argmax_a of (RJ5.4)
greedy_policy_dict{InventoryState(on_hand=0, on_order=0): 0,
InventoryState(on_hand=0, on_order=1): 0,
InventoryState(on_hand=0, on_order=2): 0,
InventoryState(on_hand=1, on_order=0): 0,
InventoryState(on_hand=1, on_order=1): 0,
InventoryState(on_hand=2, on_order=0): 0}#
# means action 0 is currently the best for all statesFiniteDeterministicPolicy(greedy_policy_dict)For State InventoryState(on_hand=0, on_order=0): Do Action 0
For State InventoryState(on_hand=0, on_order=1): Do Action 0
For State InventoryState(on_hand=0, on_order=2): Do Action 0
For State InventoryState(on_hand=1, on_order=0): Do Action 0
For State InventoryState(on_hand=1, on_order=1): Do Action 0
For State InventoryState(on_hand=2, on_order=0): Do Action 0#
# ---study greedy_policy_from_vf()#
#. Values provider
def policy_iteration(
mdp: FiniteMarkovDecisionProcess[S, A],
gamma: float,
matrix_method_for_mrp_eval: bool = False
) -> Iterator[Tuple[V[S], FinitePolicy[S, A]]]:
def update(vf_policy: Tuple[V[S], FinitePolicy[S, A]])\
-> Tuple[V[S], FiniteDeterministicPolicy[S, A]]:
vf, pi = vf_policy
mrp: FiniteMarkovRewardProcess[S] = mdp.apply_finite_policy(pi)
#. Policy Evaluation: V = V^pi
policy_vf: V[S] = {\
mrp.non_terminal_states[i]: v \
for i, v in enumerate(mrp.get_value_function_vec(gamma))}\
if matrix_method_for_mrp_eval else evaluate_mrp_result(mrp, gamma)
#. Policy Improvement: pi = G(V)
improved_pi: FiniteDeterministicPolicy[S, A] = greedy_policy_from_vf(
mdp,
policy_vf,
gamma
)
return policy_vf, improved_pi
v_0: V[S] = {s: 0.0 for s in mdp.non_terminal_states}
pi_0: FinitePolicy[S, A] = FinitePolicy(
{s.state: Choose(mdp.actions(s)) for s in mdp.non_terminal_states}
)
return iterate(update, (v_0, pi_0))#
#. Done test
def almost_equal_vf_pis(
x1: Tuple[V[S], FinitePolicy[S, A]],
x2: Tuple[V[S], FinitePolicy[S, A]]
) -> bool:
return max(
abs(x1[0][s] - x2[0][s]) for s in x1[0]
) < DEFAULT_TOLERANCE#
# fixed number of values
gen = policy_iteration(
mdp=si_mdp, gamma=item_gamma, matrix_method_for_mrp_eval=False); gen
vals = [next(gen) for i in range(3)]; vals
val = vals[1]; val({NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -50.737965419560346,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -43.560729247484375,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -41.49455240942006,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -44.560729247484375,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -42.49455240942006,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -43.49455240942006},
For State InventoryState(on_hand=0, on_order=0): Do Action 2
For State InventoryState(on_hand=0, on_order=1): Do Action 1
For State InventoryState(on_hand=0, on_order=2): Do Action 0
For State InventoryState(on_hand=1, on_order=0): Do Action 1
For State InventoryState(on_hand=1, on_order=1): Do Action 0
For State InventoryState(on_hand=2, on_order=0): Do Action 0)val[0] #V, the value function{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -50.737965419560346,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -43.560729247484375,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -41.49455240942006,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -44.560729247484375,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -42.49455240942006,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -43.49455240942006}val[1] #pi, the policyFor State InventoryState(on_hand=0, on_order=0): Do Action 2
For State InventoryState(on_hand=0, on_order=1): Do Action 1
For State InventoryState(on_hand=0, on_order=2): Do Action 0
For State InventoryState(on_hand=1, on_order=0): Do Action 1
For State InventoryState(on_hand=1, on_order=1): Do Action 0
For State InventoryState(on_hand=2, on_order=0): Do Action 0#
# values until done
converge_values: np.ndarray = converge(
values=policy_iteration(
mdp=si_mdp, gamma=item_gamma, matrix_method_for_mrp_eval=False),
done=almost_equal_vf_pis)
converge_values<generator object converge at 0x7fd2bb7624d0>converge_values_lst = list(converge_values); #converge_values_lstvf_values_lst = [it[0] for it in converge_values_lst]; vf_values_lst[{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): 0.0,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): 0.0,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): 0.0,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): 0.0,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): 0.0,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): 0.0},
{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -50.737965419560346,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -43.560729247484375,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -41.49455240942006,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -44.560729247484375,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -42.49455240942006,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -43.49455240942006},
{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -35.510518165628724,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.93217421014731,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -28.345029758390766,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.93217421014731,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -29.345029758390766,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -30.345029758390766},
{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -34.894855781630035,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.660960231637507,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -27.991900091403533,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.660960231637507,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -28.991900091403533,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -29.991900091403533},
{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -34.894855781630035,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.660960231637507,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -27.991900091403533,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.660960231637507,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -28.991900091403533,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -29.991900091403533}]pi_values_lst = [it[1].policy_map for it in converge_values_lst]; pi_values_lst[{InventoryState(on_hand=0, on_order=0): {0: 0.3333333333333333, 1: 0.3333333333333333, 2: 0.3333333333333333},
InventoryState(on_hand=0, on_order=1): {0: 0.5, 1: 0.5},
InventoryState(on_hand=0, on_order=2): {0: 1.0},
InventoryState(on_hand=1, on_order=0): {0: 0.5, 1: 0.5},
InventoryState(on_hand=1, on_order=1): {0: 1.0},
InventoryState(on_hand=2, on_order=0): {0: 1.0}},
{InventoryState(on_hand=0, on_order=0): Constant(value=2),
InventoryState(on_hand=0, on_order=1): Constant(value=1),
InventoryState(on_hand=0, on_order=2): Constant(value=0),
InventoryState(on_hand=1, on_order=0): Constant(value=1),
InventoryState(on_hand=1, on_order=1): Constant(value=0),
InventoryState(on_hand=2, on_order=0): Constant(value=0)},
{InventoryState(on_hand=0, on_order=0): Constant(value=1),
InventoryState(on_hand=0, on_order=1): Constant(value=1),
InventoryState(on_hand=0, on_order=2): Constant(value=0),
InventoryState(on_hand=1, on_order=0): Constant(value=1),
InventoryState(on_hand=1, on_order=1): Constant(value=0),
InventoryState(on_hand=2, on_order=0): Constant(value=0)},
{InventoryState(on_hand=0, on_order=0): Constant(value=1),
InventoryState(on_hand=0, on_order=1): Constant(value=1),
InventoryState(on_hand=0, on_order=2): Constant(value=0),
InventoryState(on_hand=1, on_order=0): Constant(value=1),
InventoryState(on_hand=1, on_order=1): Constant(value=0),
InventoryState(on_hand=2, on_order=0): Constant(value=0)},
{InventoryState(on_hand=0, on_order=0): Constant(value=1),
InventoryState(on_hand=0, on_order=1): Constant(value=1),
InventoryState(on_hand=0, on_order=2): Constant(value=0),
InventoryState(on_hand=1, on_order=0): Constant(value=1),
InventoryState(on_hand=1, on_order=1): Constant(value=0),
InventoryState(on_hand=2, on_order=0): Constant(value=0)}]# not all keys are always present in all dicts; most general
# https://stackoverflow.com/questions/5946236/how-to-merge-dicts-collecting-values-from-matching-keys
from collections import defaultdict
ds = vf_values_lst
vf_values_dict = defaultdict(list)
for d in ds: #input dicts
for key, value in d.items():
vf_values_dict[key].append(value)
vf_values_dictdefaultdict(list,
{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): [0.0,
-50.737965419560346,
-35.510518165628724,
-34.894855781630035,
-34.894855781630035],
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): [0.0,
-43.560729247484375,
-27.93217421014731,
-27.660960231637507,
-27.660960231637507],
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): [0.0,
-41.49455240942006,
-28.345029758390766,
-27.991900091403533,
-27.991900091403533],
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): [0.0,
-44.560729247484375,
-28.93217421014731,
-28.660960231637507,
-28.660960231637507],
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): [0.0,
-42.49455240942006,
-29.345029758390766,
-28.991900091403533,
-28.991900091403533],
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): [0.0,
-43.49455240942006,
-30.345029758390766,
-29.991900091403533,
-29.991900091403533]})len(vf_values_dict)6fig,axs = plt.subplots(figsize=(13,10))
axs.set_xlabel('Iterations', fontsize=20)
axs.set_title(f'Convergence of state values during Policy Iteration', fontsize=24)
for it in vf_values_dict.items():
axs.plot(it[1], label=f'{it[0].state}')
axs.legend(fontsize=20);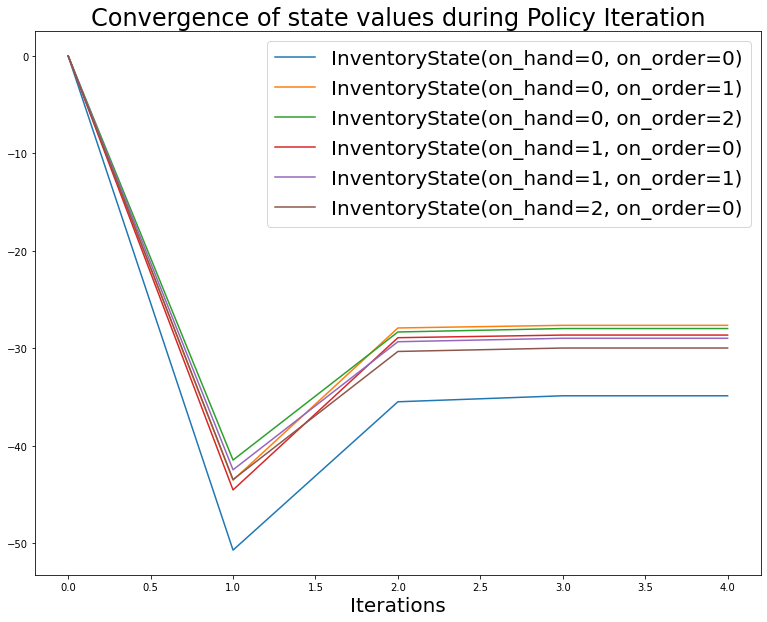
for it in vf_values_dict.items():
print(it[0].state)InventoryState(on_hand=0, on_order=0)
InventoryState(on_hand=0, on_order=1)
InventoryState(on_hand=0, on_order=2)
InventoryState(on_hand=1, on_order=0)
InventoryState(on_hand=1, on_order=1)
InventoryState(on_hand=2, on_order=0)# not all keys are always present in all dicts; most general
# https://stackoverflow.com/questions/5946236/how-to-merge-dicts-collecting-values-from-matching-keys
from collections import defaultdict
ds = pi_values_lst
pi_values_dict = defaultdict(list)
for d in ds: #input dicts
for key, value in d.items():
pi_values_dict[key].append(value)
pi_values_dictdefaultdict(list,
{InventoryState(on_hand=0, on_order=0): [{0: 0.3333333333333333, 1: 0.3333333333333333, 2: 0.3333333333333333},
Constant(value=2),
Constant(value=1),
Constant(value=1),
Constant(value=1)],
InventoryState(on_hand=0, on_order=1): [{0: 0.5, 1: 0.5},
Constant(value=1),
Constant(value=1),
Constant(value=1),
Constant(value=1)],
InventoryState(on_hand=0, on_order=2): [{0: 1.0},
Constant(value=0),
Constant(value=0),
Constant(value=0),
Constant(value=0)],
InventoryState(on_hand=1, on_order=0): [{0: 0.5, 1: 0.5},
Constant(value=1),
Constant(value=1),
Constant(value=1),
Constant(value=1)],
InventoryState(on_hand=1, on_order=1): [{0: 1.0},
Constant(value=0),
Constant(value=0),
Constant(value=0),
Constant(value=0)],
InventoryState(on_hand=2, on_order=0): [{0: 1.0},
Constant(value=0),
Constant(value=0),
Constant(value=0),
Constant(value=0)]})#
#. Converged value
def policy_iteration_result(
mdp: FiniteMarkovDecisionProcess[S, A],
gamma: float,
) -> Tuple[V[S], FiniteDeterministicPolicy[S, A]]:
return converged( #.
values=policy_iteration(mdp, gamma),
done=almost_equal_vf_pis)print("MDP Policy Iteration Optimal Value Function and Optimal Policy")
print("--------------")
opt_vf_pi, opt_policy_pi = policy_iteration_result(mdp=si_mdp, gamma=item_gamma)
pprint(opt_vf_pi)
print(opt_policy_pi)
print()MDP Policy Iteration Optimal Value Function and Optimal Policy
--------------
{NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -28.991900091403533,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -29.991900091403533,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.660960231637507,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -27.991900091403533,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -34.894855781630035,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.660960231637507}
For State InventoryState(on_hand=0, on_order=0): Do Action 1
For State InventoryState(on_hand=0, on_order=1): Do Action 1
For State InventoryState(on_hand=0, on_order=2): Do Action 0
For State InventoryState(on_hand=1, on_order=0): Do Action 1
For State InventoryState(on_hand=1, on_order=1): Do Action 0
For State InventoryState(on_hand=2, on_order=0): Do Action 0
# hide
# from rl.dynamic_programming_ANNO import value_iteration_result#
# ===study update()v: V[S] = {s: 1.2 for s in si_mdp.non_terminal_states}; v{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): 1.2,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): 1.2,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): 1.2,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): 1.2,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): 1.2,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): 1.2}[si_mdp.actions(s) for s in v][dict_keys([0, 1, 2]),
dict_keys([0, 1]),
dict_keys([0]),
dict_keys([0, 1]),
dict_keys([0]),
dict_keys([0])][[a for a in si_mdp.actions(s)] for s in v][[0, 1, 2], [0, 1], [0], [0, 1], [0], [0]]{s: [a for a in si_mdp.actions(s)] for s in v}{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): [0, 1, 2],
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): [0, 1],
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): [0],
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): [0, 1],
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): [0],
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): [0]}{s: [si_mdp.mapping[s][a] for a in si_mdp.actions(s)] for s in v}{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): [{(NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -10.0): 1.0},
{(NonTerminal(state=InventoryState(on_hand=0, on_order=1)), -10.0): 1.0},
{(NonTerminal(state=InventoryState(on_hand=0, on_order=2)), -10.0): 1.0}],
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): [{(NonTerminal(state=InventoryState(on_hand=1, on_order=0)), -0.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -3.6787944117144233): 0.6321205588285577},
{(NonTerminal(state=InventoryState(on_hand=1, on_order=1)), -0.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=1)), -3.6787944117144233): 0.6321205588285577}],
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): [{(NonTerminal(state=InventoryState(on_hand=2, on_order=0)), -0.0): 0.36787944117144233, (NonTerminal(state=InventoryState(on_hand=1, on_order=0)), -0.0): 0.36787944117144233, (NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -1.0363832351432696): 0.26424111765711533}],
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): [{(NonTerminal(state=InventoryState(on_hand=1, on_order=0)), -1.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -4.678794411714423): 0.6321205588285577},
{(NonTerminal(state=InventoryState(on_hand=1, on_order=1)), -1.0): 0.3678794411714424, (NonTerminal(state=InventoryState(on_hand=0, on_order=1)), -4.678794411714423): 0.6321205588285577}],
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): [{(NonTerminal(state=InventoryState(on_hand=2, on_order=0)), -1.0): 0.36787944117144233, (NonTerminal(state=InventoryState(on_hand=1, on_order=0)), -1.0): 0.36787944117144233, (NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -2.0363832351432696): 0.26424111765711533}],
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): [{(NonTerminal(state=InventoryState(on_hand=2, on_order=0)), -2.0): 0.36787944117144233, (NonTerminal(state=InventoryState(on_hand=1, on_order=0)), -2.0): 0.36787944117144233, (NonTerminal(state=InventoryState(on_hand=0, on_order=0)), -3.0363832351432696): 0.26424111765711533}]}# .expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v, s1r[0]))
{s: [si_mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v, s1r[0])) for a in si_mdp.actions(s)] for s in v}{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): [-8.92,
-8.92,
-8.92],
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): [-1.2454415793482962,
-1.2454415793482962],
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): [0.8061449356246455],
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): [-2.2454415793482965,
-2.2454415793482965],
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): [-0.1938550643753545],
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): [-1.1938550643753545]}{s: [max(si_mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v, s1r[0])) for a in si_mdp.actions(s))] for s in v}{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): [-8.92],
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): [-1.2454415793482962],
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): [0.8061449356246455],
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): [-2.2454415793482965],
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): [-0.1938550643753545],
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): [-1.1938550643753545]}#
# remove inner list
{s: max(si_mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + item_gamma*extended_vf(v, s1r[0])) for a in si_mdp.actions(s)) for s in v}{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -8.92,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -1.2454415793482962,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): 0.8061449356246455,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -2.2454415793482965,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -0.1938550643753545,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -1.1938550643753545}#
# ---study update()#
#. Values provider
def value_iteration(
mdp: FiniteMarkovDecisionProcess[S, A],
gamma: float
) -> Iterator[V[S]]:
def update(v: V[S]) -> V[S]:
#. s1r[0] is s'
#. s1r[1] is r
return \
{s: max(mdp.mapping[s][a].expectation(lambda s1r: s1r[1] + gamma*extended_vf(v, s1r[0]))
for a in mdp.actions(s)) for s in v}
v_0: V[S] = {s: 0.0 for s in mdp.non_terminal_states}
return iterate(update, v_0)#
#. Done test
def almost_equal_vfs(
v1: V[S],
v2: V[S],
tolerance: float = DEFAULT_TOLERANCE
) -> bool:
return max(abs(v1[s] - v2[s]) for s in v1) < tolerance#
# fixed number of values
gen = value_iteration(mdp=si_mdp, gamma=item_gamma); gen
vals = [next(gen) for i in range(3)]; vals
val = vals[1]; val{NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -10.0,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -2.3254415793482965,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -0.2738550643753545,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -3.3254415793482965,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -1.2738550643753546,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -2.2738550643753546}#
# values until done
converge_values: np.ndarray = converge(
values=value_iteration(mdp=si_mdp, gamma=item_gamma),
done=almost_equal_vfs)
converge_values<generator object converge at 0x7fd2ba6cae50>vf_values_lst = list(converge_values); #vf_values_lst# not all keys are always present in all dicts; most general
# https://stackoverflow.com/questions/5946236/how-to-merge-dicts-collecting-values-from-matching-keys
from collections import defaultdict
ds = vf_values_lst
vf_values_dict = defaultdict(list)
for d in ds: #input dicts
for key, value in d.items():
vf_values_dict[key].append(value)
# vf_values_dictlen(vf_values_dict)6fig,axs = plt.subplots(figsize=(13,10))
axs.set_xlabel('Iterations', fontsize=20)
axs.set_title(f'Convergence of state values during Value Iteration', fontsize=24)
for it in vf_values_dict.items():
axs.plot(it[1], label=f'{it[0].state}')
axs.legend(fontsize=20);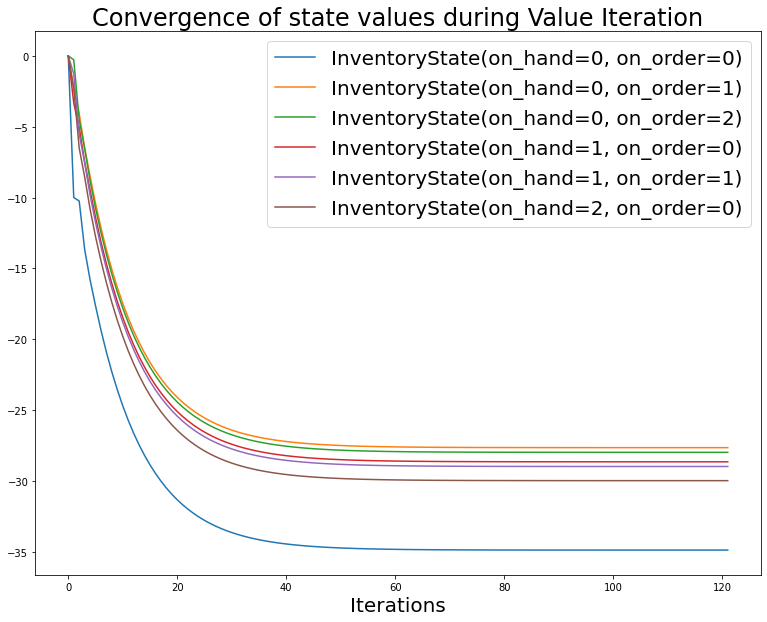
#
#. Converged value
def value_iteration_result(
mdp: FiniteMarkovDecisionProcess[S, A],
gamma: float
) -> Tuple[V[S], FiniteDeterministicPolicy[S, A]]:
opt_vf: V[S] = converged(
values=value_iteration(mdp, gamma), #.
done=almost_equal_vfs
)
opt_policy: FiniteDeterministicPolicy[S, A] = greedy_policy_from_vf(
mdp,
opt_vf,
gamma
)
return opt_vf, opt_policyprint("MDP Value Iteration Optimal Value Function and Optimal Policy")
print("--------------")
opt_vf_vi, opt_pi_vi = value_iteration_result(mdp=si_mdp, gamma=item_gamma) #.
pprint(opt_vf_vi)
print(opt_pi_vi)
print()MDP Value Iteration Optimal Value Function and Optimal Policy
--------------
{NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -29.991899504444792,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -28.99189950444479,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -28.66095964467877,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -27.66095964467877,
NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -27.99189950444479,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -34.894855194671294}
For State InventoryState(on_hand=0, on_order=0): Do Action 1
For State InventoryState(on_hand=0, on_order=1): Do Action 1
For State InventoryState(on_hand=0, on_order=2): Do Action 0
For State InventoryState(on_hand=1, on_order=0): Do Action 1
For State InventoryState(on_hand=1, on_order=1): Do Action 0
For State InventoryState(on_hand=2, on_order=0): Do Action 0
As we see from both the Policy Iteration as well as the Value Iteration algoritms, the optimal policy is to: - not order if the inventory position (sum of on-order and on-hand) is greater than 1 unit - order 1 unit if the inventory position is 0 or 1
implied_mrp.generate_image()
si_mdp.non_terminal_states[NonTerminal(state=InventoryState(on_hand=0, on_order=0)),
NonTerminal(state=InventoryState(on_hand=0, on_order=1)),
NonTerminal(state=InventoryState(on_hand=0, on_order=2)),
NonTerminal(state=InventoryState(on_hand=1, on_order=0)),
NonTerminal(state=InventoryState(on_hand=1, on_order=1)),
NonTerminal(state=InventoryState(on_hand=2, on_order=0))]fig = plt.figure(figsize=(15, 10))
ax1 = fig.add_subplot(111, projection='3d')
values = {si_mdp.non_terminal_states[i]: round(v, 3) for i, v in enumerate(implied_mrp.get_value_function_vec(item_gamma))}
list_of_tuples = [(k.state.on_hand, k.state.on_order, -v) for k,v in values.items()]
x3, y3, dz = [list(tup) for tup in zip(*list_of_tuples)]; x3, y3, dz
n = len(dz)
z3 = np.zeros(n)
dx = np.ones(n)
dy = np.ones(n)
ax1.bar3d(x3, y3, z3, dx, dy, dz)
ax1.set_xticks([e+0.5 for e in range(n - 1)])
ax1.set_xticklabels(range(n - 1))
ax1.set_xlabel(r'on-hand inventory, $\alpha$', fontsize=15)
ax1.set_yticks([e+0.5 for e in range(n - 1)])
ax1.set_yticklabels(range(n - 1))
ax1.set_ylabel(r'on-order inventory, $\beta$', fontsize=15)
ax1.set_zlabel(r'value, $-V$', fontsize=15)
ax1.set_title('Negative of the Value Function', fontsize=20)
ax1.view_init(ax1.elev + 20, -200)
# ax.elev + 10, -160
plt.show()