In this project the client had a need to be convinced of the benefits of formal optimized sequential decision making. The client’s need relates to automated and optimal human resource scheduling. The current project is the first POC aligned with this need.
The current use case involves a company that maintains a number of human resources on a “bench”. As demands for consulting services come in, an AI agent attempts to make an optimal sequence of allocation decisions related to a stated objective. Note that a single decision, by itself, might not be optimal. The idea is to create an optimal decision sequence that leads to maximization of the stated objective.
For this use case the bench consists of:
7 CEOs
3 CFOs
2 Accountants
4 IT Developers
This pool is expected to grow as new resources are signed up.
The overall structure of this project and report follows the traditional CRISP-DM format. However, instead of the CRISP-DM’S “4 Modeling” section, we inserted the “6 step modeling process” of Dr. Warren Powell in section 4 of this document. Dr Powell’s universal framework shows great promise for unifying the formalisms of at least a dozen different fields. Using his framework enables easier access to thinking patterns in these other fields that might be beneficial and informative to the sequential decision problem at hand. Traditionally, this kind of problem would be approached from the reinforcement learning perspective. However, using Dr. Powell’s wider and more comprehensive perspective almost certainly provides additional value.
In order to make a strong mapping between the code in this notebook and the mathematics in the Powell Universal Framework (PUF), we follow the following convention for naming Python identifier names:
How to read/say
var name & flavor first
at t/n
for entity OR of/with attribute
\(\hat{R}^{fail}_{t+1,a}\) has code Rhat__fail_tt1_a which is read: “Rhatfail at t+1 of/with (attribute) a”
Superscripts
variable names have a double underscore to indicate a superscript
\(X^{\pi}\): has code X__pi, is read X pi
when there is a ‘natural’ distinction between the variable symbol and the superscript (e.g. a change in case), the double underscore is sometimes omitted: Xpi instead of X__pi, or MSpend_t instead of M__Spend_t
Subscripts
variable names have a single underscore to indicate a subscript
\(S_t\): has code S_t, is read ‘S at t’
\(M^{Spend}_t\) has code M__Spend_t which is read: “MSpend at t”
\(\hat{R}^{fail}_{t+1,a}\) has code Rhat__fail_tt1_a which is read: “Rhatfail at t+1 of/with (attribute) a” [RLSO-p436]
Arguments
collection variable names may have argument information added
\(X^{\pi}(S_t)\): has code X__piIS_tI, is read ‘X pi in S at t’
the surrounding I’s are used to imitate the parentheses around the argument
Next time/iteration
variable names that indicate one step in the future are quite common
\(R_{t+1}\): has code R_tt1, is read ‘R at t+1’
\(R^{n+1}\): has code R__nt1, is read ‘R at n+1’
Rewards
State-independent terminal reward and cumulative reward
\(F\): has code F for terminal reward
\(\sum_{n}F\): has code cumF for cumulative reward
State-dependent terminal reward and cumulative reward
\(C\): has code C for terminal reward
\(\sum_{t}C\): has code cumC for cumulative reward
Vectors where components use different names
\(S_t(R_t, p_t)\): has code S_t.R_t and S_t.p_t, is read ‘S at t in R at t, and, S at t in p at t’
the code implementation is by means of a named tuple
self.State = namedtuple('State', SVarNames) for the ‘class’ of the vector
self.S_t for the ‘instance’ of the vector
Vectors where components reuse names
\(x_t(x_{t,GB}, x_{t,BL})\): has code x_t.x_t_GB and x_t.x_t_BL, is read ‘x at t in x at t for GB, and, x at t in x at t for BL’
the code implementation is by means of a named tuple
self.Decision = namedtuple('Decision', xVarNames) for the ‘class’ of the vector
self.x_t for the ‘instance’ of the vector
Use of mixed-case variable names
to reduce confusion, sometimes the use of mixed-case variable names are preferred (even though it is not a best practice in the Python community), reserving the use of underscores and double underscores for math-related variables
1 BUSINESS UNDERSTANDING
Requests for fractional human resources come associated with the number of days a resource is needed. The duration of the assignments may vary from 1 day to 42 days (about 2 months worth of work days). These are the only durations allowed for now.
As requests for fractional resources come in, they are placed in one of two queues:
a short-duration queue
a long-duration queue
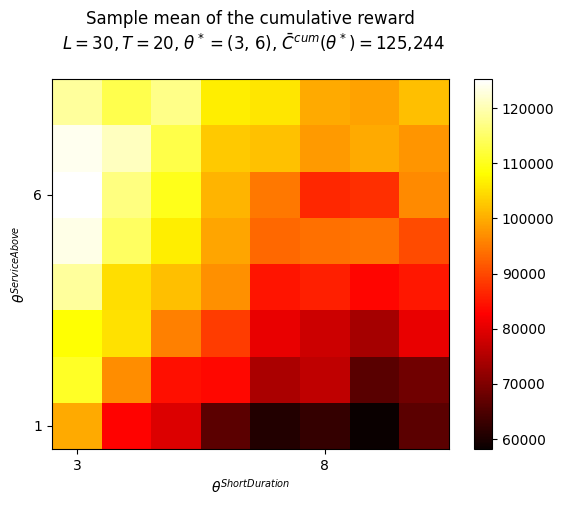
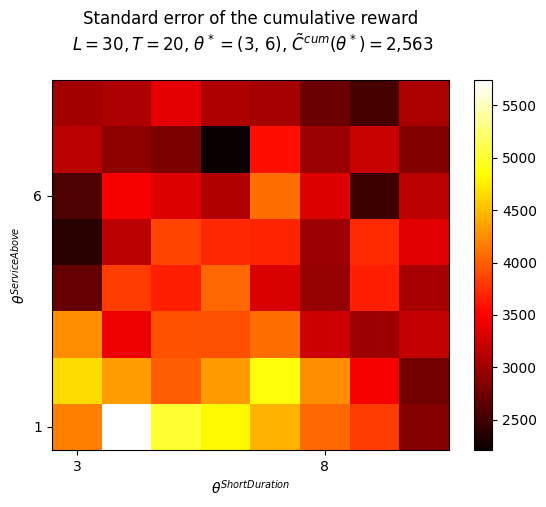
The threshold around which a consulting demand is classified as either a short-duration rental or a long-duration engagement, will be learned by the AI agent. This threshold is represented by a code parameter thShortDuration. Mathematically, it is represented as \(\theta^{ShortDuration}\).
An underlying assumption is that short-duration assignments will be more profitable. A consumer will often be prepared to pay an unusually high premium for the quick access to a knowledgable resource, maybe during an enterprise emergency or unusual situation like a merging activity. The company we are modeling in this POC decided to capitalize on this by having a pricing structure based on a linear sliding scale:
CEO
$380/day for 1 day
$300/day for 21 days
CFO
$370/day for 1 day
$290/day for 21 days
Accountant
$250/day for 1 day
$170/day for 21 days
IT Developer
$300/day for 1 day
$250/day for 21 days
Between the outer values, in each case, the rates slide down linearly depending on the duration of the assignment.
Another important dynamic decision to be made is how the two queues need to be served. This decision is handled by having the AI agent learn another parameter, represented in the code as thServiceAbove. The short-duration queue will be serviced each time its length exceeds the value of the \(\theta^{ServiceAbove}\) parameter. If its length is below this value, the other queue will be serviced.
The overall objective will be to maximize profit, even if it leads to growing queue lengths over time.
2 DATA UNDERSTANDING
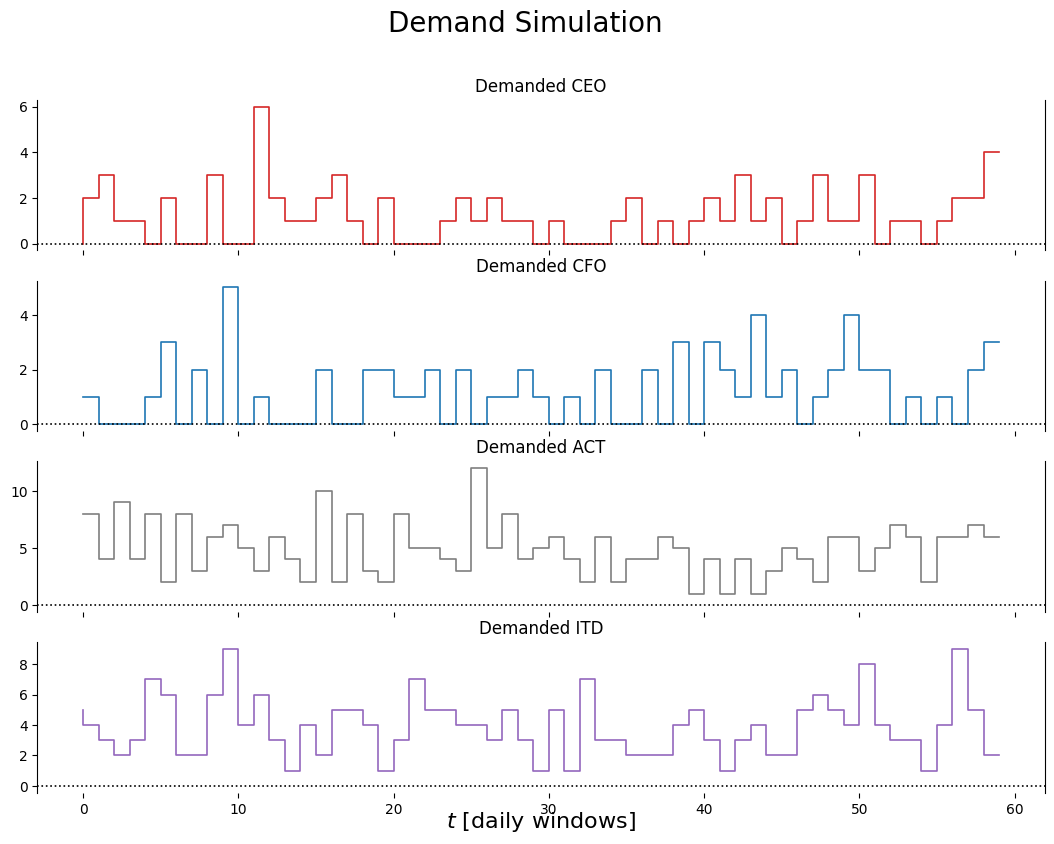
Based on recent market research, the demand may be modeled by a Poisson distribution for each resource type: \[
\begin{aligned}
\mu^{ResourceType} &= \mathrm{SIM\_MU\_D[RESOURCE\_TYPE]}
\end{aligned}
\]
So we have: \[
D^{ResourceType}_{t+1} \sim Pois(\mu^{ResourceType})
\]
The decision window is 1 hour and these simulations are for the hourly demands (during business hours).
DeprecationWarning: Please use `shift` from the `scipy.ndimage` namespace, the `scipy.ndimage.interpolation` namespace is deprecated.
from scipy.ndimage.interpolation import shift
We will use the data provided by the simulator directly. There is no need to perform additional data preparation.
4 MODELING
4.1 Narrative
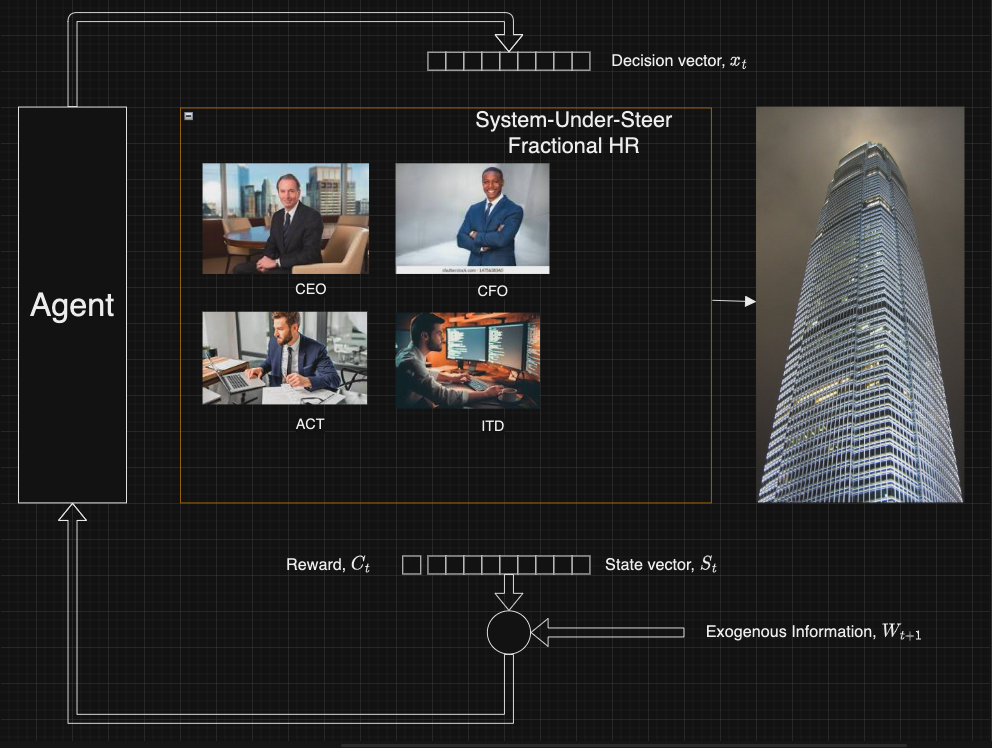
Please review the narrative in section 1. The next figure is a representation of the solution to the problem:
FractionalHR
4.2 Core Elements
This section attempts to answer three important questions:
What metrics are we going to track?
What decisions do we intend to make?
What are the sources of uncertainty?
For this problem, the only metric we are interested in is the amount of profit we make after each decision window. A single type of decision needs to be made at the start of each window - which input queue to serve (short-duration or long-duration). The only source of uncertainty are the levels of demand for each of the resource types.
4.3 Mathematical Model | SUS Design
A Python class is used to implement the model for the SUS (System Under Steer):
class Model():
def __init__(self, S_0_info):
...
...
4.3.1 State variables
The state variables represent what we need to know.
The exogenous information variables represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(x_t\).
When we assume that the demand in each time period is revealed, without any model to predict the demand based on past demands, we have, using approach 1:
We will make use of approach 1 which means that the exogenous information, \(W_{t+1}\), is the directly observed demands of the resources.
The exogenous information is obtained by a call to
DemandSimulator.simulate(...)
4.3.4 Transition function
The transition function describe how the state variables evolve over time. We have the equations:
\[
R^{Avail}_{t+1} =
\begin{cases}
1 & \text{if resource with attribute $a$ has not been allocated} \\
0 & \text{if resource with attribute $a$ has been allocated }
\end{cases}
\]
the assignment duration (in days) above which the assignment is classified as a long-duration assignment
\(\theta^{ServiceAbove}\)
the short-duration queue length above which the queue is processed; below this value allows for the processing of the long-duration queue
4.3.6 Implementation of the System Under Steer (SUS) Model
class Model():def__init__(self, W_fn=None, S__M_fn=None, C_fn=None):self.S_t = {'R_t': pd.DataFrame({'ResourceId': RESOURCE_IDS,'Type': TYPES,'RInvsOut_t': [0]*len(TYPES),'RAvail_t': [True]*len(TYPES),'RDuration_t': [0]*len(TYPES), }),'D_t': pd.DataFrame({'Type': RESOURCE_TYPES,'D_t': [0]*len(RESOURCE_TYPES),'Dcum_t': [0]*len(RESOURCE_TYPES), }), }self.Decision = namedtuple('Decision', xNAMES) #. 'class'self.Ccum =0.0#. cumulative rewardself.shortDurationQueue = []self.longDurationQueue = []def reset(self):self.Ccum =0.0self.S_t =self.build_state(self.S_0)def build_state(self, info):returnself.State(*[info[sn] for sn in SNAMES])def build_decision(self, info):returnself.Decision(*[info[xn] for xn in xNAMES])# exogenous information, dependent on a random process,# the directly observed demandsdef W_fn(self, t):return SIM.simulate()def performServiceAboveDecision(self, x_t, theta): demandsToService = []if x_t.x_t ==1: #service shortDurationQueue## nDemandsToService = max(0, len(self.shortDurationQueue) - theta.thServiceAbove); print(f'{nDemandsToService=}') nDemandsToService =len(self.shortDurationQueue);##print(f'{nDemandsToService=}')## demandsToService = self.shortDurationQueue[:nDemandsToService]; print(f'{demandsToService=}') demandsToService =self.shortDurationQueue;##print(f'{demandsToService=}')elif x_t.x_t ==0: #service longDurationQueue nDemandsToService =len(self.longDurationQueue);##print(f'{nDemandsToService=}')## demandsToService = self.longDurationQueue[:nDemandsToService]; print(f'{demandsToService=}') demandsToService =self.longDurationQueue;##print(f'{demandsToService=}')else: print(f'ERROR in performServiceAboveDecision(). Invalid {x_t=}')for demand in demandsToService: resourceType, duration = demand;##print(f'{resourceType=}, {duration=}') avails =self.S_t['R_t'].loc[ (self.S_t['R_t']['Type']==resourceType)&(self.S_t['R_t']['RAvail_t']==True), ['ResourceId', 'Type', 'RAvail_t', 'RDuration_t'] ];##print(f'avails=\n{avails}')iflen(avails) >0: alloc = avails.iloc[0, :];##print(f'alloc=\n{alloc}')self.S_t['R_t'].loc[self.S_t['R_t']['ResourceId']==alloc['ResourceId'], ['RAvail_t'] ] =Falseself.S_t['R_t'].loc[self.S_t['R_t']['ResourceId']==alloc['ResourceId'], ['RDuration_t'] ] = duration m, c = RENT_PARS[resourceType]['m'], RENT_PARS[resourceType]['c']self.Ccum += p__rent(int(duration), m, c)*int(duration) #sales## c__hold = c__upkeep[resourceType]*duration #bench cost## self.Ccum -= c__hold## print(f'ResourceId {alloc["ResourceId"]} has been allocated for demand {demand}')if x_t.x_t ==1:self.shortDurationQueue.pop(0)elif x_t.x_t ==0:self.longDurationQueue.pop(0)## update Dcumself.S_t['D_t'].loc[self.S_t['D_t']['Type']==resourceType, ['Dcum_t'] ] -=1##1 resource allocatedelse:## print(f'No resource of type {resourceType} available. Demand {demand} kept in queue')## self.Ccum -= c__sout #stockout costs might be calced herepassdef S__M_fn(self, t, S_t, x_t, W_tt1, theta):## perform decision taken this morningself.performServiceAboveDecision(x_t, theta)## D_t #direct approachfor rt in RESOURCE_TYPES: number = W_tt1[rt] S_t['D_t'].loc[S_t['D_t']['Type']==rt, 'D_t'] = number S_t['D_t'].loc[ S_t['D_t']['Type']==rt, ##row-indexor ['Dcum_t'] ##col-indexor ] += number## Simulate the arrival of demands throughout dayfor resourceType in RESOURCE_TYPES: n_demands =int(S_t['D_t'].loc[S_t['D_t']['Type']==resourceType, 'D_t'])for demand inrange(n_demands): duration = np.random.randint(low=DURATION_LO, high=DURATION_HI) #ideal for vintage cars, 24 hoursif duration < theta.thShortDuration:self.shortDurationQueue.append([resourceType, duration])else:self.longDurationQueue.append([resourceType, duration])self.shortDurationQueue = np.random.permutation(self.shortDurationQueue).tolist()self.longDurationQueue = np.random.permutation(self.longDurationQueue).tolist()## Increment RInvsOut_t for all engaged resources S_t['R_t']['RInvsOut_t'] =\ S_t['R_t'].loc[ S_t['R_t']['RAvail_t']==False, ['RInvsOut_t'] ].apply(lambda x: x+1) S_t['R_t'].loc[ ##fix NaNs created by previous statement np.isnan(S_t['R_t']['RInvsOut_t']), ['RInvsOut_t'] ] =0## Return all engaged resources when completed with engagement S_t['R_t'].loc[ S_t['R_t']['RInvsOut_t'] > S_t['R_t']['RDuration_t'].astype(float), ['RInvsOut_t', 'RAvail_t', 'RDuration_t'] ] =0,True,0 record_t = [t] +\list(S_t['R_t']['RInvsOut_t']) +\list(S_t['R_t']['RDuration_t']) +\list(S_t['D_t']['D_t']) +\list(S_t['D_t']['Dcum_t']) +\ [len(self.shortDurationQueue)] +\ [len(self.longDurationQueue)] +\ [self.Ccum] +\ [x_t.x_t]return record_tdef C_fn(self, S_t, x_t, W_tt1, theta):returndef step(self, t, x_t, theta):## IND = '\t\t'## print(f"{IND}..... M. step() .....\n{t=}\n{theta=}") W_tt1 =self.W_fn(t)## update state & reward record_t =self.S__M_fn(t, self.S_t, x_t, W_tt1, theta)return record_t
4.4 Uncertainty Model
We will simulate the resource demand vector \(D_{t+1}\) as described in section 2.
4.5 Policy Design
There are two main meta-classes of policy design. Each of these has two subclasses: - Policy Search - Policy Function Approximations (PFAs) - Cost Function Approximations (CFAs) - Lookahead - Value Function Approximations (VFAs) - Direct Lookaheads (DLAs)
In this project we will only use one approach: - A simple service-above parameterized policy (from the PFA class) which can be summarized as:
if length of shortDurationQueue > \(\theta^{ShortDuration}\):
process the short-duration queue
else:
process the long-duration queue
4.5.1 Implementation of Policy Design
import randomclass Policy():def__init__(self, model):self.model = modelself.Policy = namedtuple('Policy', piNAMES) #. 'class'self.Theta = namedtuple('Theta', thNAMES) #. 'class'def build_policy(self, info):returnself.Policy(*[info[pin] for pin in piNAMES])def build_theta(self, info):returnself.Theta(*[info[thn] for thn in thNAMES])## Service the shortDurationQueue when its length exceeds thServiceAbove,## else, the longDurationQueue.## x_t=1: service shortDurationQueue; x_t=0: service longDurationQueue## Assumption is that shortDurationQueue is more profitable, and the## decision should center around its status; once it's been taken care of,## the longDurationQueue can be serviced.def X__ServiceAbove(self, t, S_t, theta): info = {'x_t': 0 }if t >= T:print(f"ERROR: t={t} should not reach or exceed the max steps ({T})")returnself.model.build_decision(info)iflen(self.model.shortDurationQueue) > theta.thServiceAbove:##service shortDuration queue info['x_t'] =1else:##service longDuration queue info['x_t'] =0returnself.model.build_decision(info)def run_grid_sample_paths(self, theta, piName, record): CcumIomega__lI = []for l inrange(1, L +1): #for each sample-path M = Model()## P = Policy(M) #NO!, overwrite existing global Pself.model = M record_l = [piName, theta, l]for t inrange(T): #for each transition/step## print(f'\t%%% {t=}')## >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> x_t =getattr(self, piName)(t, self.model.S_t, theta) #lookup (new) today's decision## sit in post-decision state until end of cycle (evening)## S_t, Ccum, x_t = self.model.step(t, x_t, theta) record_t =self.model.step(t, x_t, theta) #change from today to tomorrow## >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> record.append(record_l + record_t) CcumIomega__lI.append(self.model.Ccum) #just above (SDAM-eq2.9)return CcumIomega__lIdef perform_grid_search_sample_paths(self, piName, thetas): Cbarcum = defaultdict(float) Ctilcum = defaultdict(float) expCbarcum = defaultdict(float) expCtilcum = defaultdict(float) numThetas =len(thetas) record = []print(f'{numThetas=:,}') nth =1 i =0;print(f'... printing every {nth}th theta (if considered) ...')for theta in thetas:ifTrue: ##in case relationships between thetas can be exploited## a dict cannot be used as a key, so we define theta_key, e.g.## theta_key = ((168.0, 72.0), (200.0, 90.0)):## theta_key = tuple(tuple(itm.values()) for itm in theta) theta_key = theta ##if theta is not a dictif i%nth ==0: print(f'=== ({i:,} / {numThetas:,}), theta={theta} ===')## >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> CcumIomega__lI =self.run_grid_sample_paths(theta, piName, record)## >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Cbarcum_tmp = np.array(CcumIomega__lI).mean() #(SDAM-eq2.9) Ctilcum_tmp = np.sum(np.square(np.array(CcumIomega__lI) - Cbarcum_tmp))/(L -1) Cbarcum[theta_key] = Cbarcum_tmp Ctilcum[theta_key] = np.sqrt(Ctilcum_tmp/L) expCbarcum_tmp = pd.Series(CcumIomega__lI).expanding().mean() expCbarcum[theta_key] = expCbarcum_tmp expCtilcum_tmp = pd.Series(CcumIomega__lI).expanding().std() expCtilcum[theta_key] = expCtilcum_tmp i +=1##endif best_theta =max(Cbarcum, key=Cbarcum.get) worst_theta =min(Cbarcum, key=Cbarcum.get) best_Cbarcum = Cbarcum[best_theta] best_Ctilcum = Ctilcum[best_theta] worst_Cbarcum = Cbarcum[worst_theta] worst_Ctilcum = Ctilcum[worst_theta] thetaStar_expCbarcum = expCbarcum[best_theta] thetaStar_expCtilcum = expCtilcum[best_theta] thetaStar_expCtilcum[0] =0##set NaN to 0## best_theta_w_names = tuple((# ({# a1NAMES[0]: subvec[0],# a1NAMES[1]: subvec[1]# })) for subvec in best_theta)## best_theta_n = self.build_theta({'thAdj': best_theta_w_names[0]})## best_theta_n = self.build_theta({'thAdj1': best_theta_w_names[0], 'thAdj3': best_theta_w_names[1]})## print(f'best_theta_n:\n{best_theta_n}\n{best_Cbarcum=:.2f}\n{best_Ctilcum=:.2f}')## worst_theta_w_names = tuple((# ({# a1NAMES[0]: subvec[0],# a1NAMES[1]: subvec[1]})) for subvec in worst_theta)## worst_theta_n = self.build_theta({'thAdj': worst_theta_w_names[0]})## worst_theta_n = self.build_theta({'thAdj1': worst_theta_w_names[0], 'thAdj3': worst_theta_w_names[1]})## print(f'worst_theta_n:\n{worst_theta_n}\n{worst_Cbarcum=:.2f}\n{worst_Ctilcum=:.2f}')return\ thetaStar_expCbarcum, thetaStar_expCtilcum, \ Cbarcum, Ctilcum, \ best_theta, worst_theta, \ best_Cbarcum, worst_Cbarcum, \ best_Ctilcum, worst_Ctilcum, \ record## dispatch {prepend @}# def grid_search_theta_values(self, thetas0): #. using vectors reduces loops in perform_grid_search_sample_paths()# thetas = [(th0,) for th0 in thetas0]# return thetas## dispatch {prepend @}# def grid_search_theta_values(self, thetas0, thetas1): #. using vectors reduces loops in perform_grid_search_sample_paths()# thetas = [(th0, th1) for th0 in thetas0 for th1 in thetas1]# return thetas## dispatch {prepend @}# def grid_search_theta_values(self, thetas0, thetas1, thetas2): #. using vectors reduces loops in perform_grid_search_sample_paths()# thetas = [(th0, th1, th2) for th0 in thetas0 for th1 in thetas1 for th2 in thetas2]# return thetas## EXAMPLE:## thetasA: Buy## thetasA_name: 'thBuy'## names: ELA## 1_1: 1 theta sub-vectors, each having 1 theta## thetas = grid_search_thetas_1_2(thetasBuy 'thBuy', CAR_TYPES)def grid_search_thetas_1_1(self, thetasA, thetasA_name, names): thetas = [self.build_theta({thetasA_name: {names[0]: thA0}})for thA0 in thetasA[names[0]] ]return thetas## EXAMPLE:## thetasA: Buy## thetasA_name: 'thBuy'## names: ELA, SON## 1_2: 1 theta sub-vectors, each having 2 thetas## thetas = grid_search_thetas_1_2(thetasBuy 'thBuy', CAR_TYPES)def grid_search_thetas_1_2(self, thetasA, thetasA_name, names): thetas = [self.build_theta({thetasA_name: {names[0]: thA0, names[1]: thA1}})for thA0 in thetasA[names[0]]for thA1 in thetasA[names[1]] ]return thetas## EXAMPLE:## thetasA: Adj## thetasA_name: 'thAdj'## names: ELA, SON## 1_4: 1 theta sub-vectors, each having 4 thetas## thetas = grid_search_thetas_1_4(thetasBuy 'thAdj', bNAMES)def grid_search_thetas_1_4(self, thetasA, thetasA_name, names): thetas = [self.build_theta({thetasA_name: {names[0]: thA0, names[1]: thA1, names[2]: thA2, names[3]: thA3}})for thA0 in thetasA[names[0]]for thA1 in thetasA[names[1]]for thA2 in thetasA[names[2]]for thA3 in thetasA[names[3]] ]return thetas## EXAMPLE:## thetasA: Buy## thetasB: Max## thetasA_name: 'thBuy'## thetasB_name: 'thMax'## names: ELA## 2_1: 2 theta sub-vectors, each having 1 theta## thetas = grid_search_thetas_2_1(thetasBuy, thetasMax, 'thBuy', 'thMax', CAR_TYPES)def grid_search_thetas_2_1(self, thetasA, thetasB, thetasA_name, thetasB_name, names): thetas = [self.build_theta({thetasA_name: {names[0]: thA0}, thetasB_name: {names[0]: thB0}})for thA0 in thetasA[names[0]]for thB0 in thetasB[names[0]] ]return thetas## EXAMPLE:## thetasA: Buy## thetasB: Max## thetasA_name: 'thBuy'## thetasB_name: 'thMax'## names: ELA, SON## 2_2: 2 theta sub-vectors, each having 2 thetas## thetas = grid_search_thetas_4(thetasBuy, thetasMax, 'thBuy', 'thMax', CAR_TYPES)def grid_search_thetas_2_2(self, thetasA, thetasB, thetasA_name, thetasB_name, names): thetas = [self.build_theta({thetasA_name: {names[0]: thA0, names[1]: thA1}, thetasB_name: {names[0]: thB0, names[1]: thB1}})for thA0 in thetasA[names[0]]for thA1 in thetasA[names[1]]for thB0 in thetasB[names[0]]for thB1 in thetasB[names[1]] ]return thetas############################################################################### PLOTTING############################################################################def round_theta(self, complex_theta): thetas_rounded = []for theta in complex_theta: evalues_rounded = []for _, evalue in theta.items(): evalues_rounded.append(float(f"{evalue:f}")) thetas_rounded.append(tuple(evalues_rounded))returnstr(tuple(thetas_rounded))def plot_Fhat_map_2(self, FhatI_theta_I, thetasX, thetasY, labelX, labelY, title): Fhat_values = [ FhatI_theta_I[ (thetaX,thetaY)## ((thetaX,),(thetaY,)) ]for thetaY in thetasY for thetaX in thetasX ] Fhats = np.array(Fhat_values) increment_count =len(thetasX) Fhats = np.reshape(Fhats, (-1, increment_count))#. fig, ax = plt.subplots() im = ax.imshow(Fhats, cmap='hot', origin='lower', aspect='auto')## create colorbar cbar = ax.figure.colorbar(im, ax=ax)## cbar.ax.set_ylabel(cbarlabel, rotation=-90, va="bottom") ax.set_xticks(np.arange(0, len(thetasX), 5))#.## ax.set_xticks(np.arange(len(thetasX))) ax.set_yticks(np.arange(0, len(thetasY), 5))#.## ax.set_yticks(np.arange(len(thetasY)))## NOTE: round tick labels, else very messy## function round() does not work, have to do this way thetasX_form = [f'{th:.0f}'for th in thetasX] thetasY_form = [f'{th:.0f}'for th in thetasY] ax.set_xticklabels(thetasX[::5])## ax.set_xticklabels(thetasX); ax.set_xticklabels(thetasX_form) ax.set_yticklabels(thetasY[::5])## ax.set_yticklabels(thetasY); ax.set_yticklabels(thetasY_form)## rotate the tick labels and set their alignment.## plt.setp(ax.get_xticklabels(), rotation=45, ha="right",rotation_mode="anchor") ax.set_title(title) ax.set_xlabel(labelX) ax.set_ylabel(labelY)## fig.tight_layout() plt.show()returnTruedef plot_Fhat_map_4(self, FhatI_theta_I, thetasX, thetasY, labelX, labelY, title, thetaFixed1, thetaFixed2):## Fhat_values = [FhatI_theta_I[(thetaX,thetaY)] for thetaY in thetasY for thetaX in thetasX] Fhat_values = [ FhatI_theta_I[((thetaX,thetaY), (thetaFixed1,thetaFixed2))]for thetaY in thetasYfor thetaX in thetasX] Fhats = np.array(Fhat_values) increment_count =len(thetasX) Fhats = np.reshape(Fhats, (-1, increment_count))#. fig, ax = plt.subplots() im = ax.imshow(Fhats, cmap='hot', origin='lower', aspect='auto')## create colorbar cbar = ax.figure.colorbar(im, ax=ax)## cbar.ax.set_ylabel(cbarlabel, rotation=-90, va="bottom") ax.set_xticks(np.arange(0, len(thetasX), 5))#.## ax.set_xticks(np.arange(len(thetasX))) ax.set_yticks(np.arange(0, len(thetasY), 5))#.## ax.set_yticks(np.arange(len(thetasY)))## NOTE: round tick labels, else very messy## function round() does not work, have to do this way## thetasX_form = [f'{th:.1f}' for th in thetasX]## thetasY_form = [f'{th:.1f}' for th in thetasY] ax.set_xticklabels(thetasX[::5])#.## ax.set_xticklabels(thetasX)## ax.set_xticklabels(thetasX_form) ax.set_yticklabels(thetasY[::5])#.## ax.set_yticklabels(thetasY)## ax.set_yticklabels(thetasY_form)## rotate the tick labels and set their alignment.## plt.setp(ax.get_xticklabels(), rotation=45, ha="right",rotation_mode="anchor") ax.set_title(title) ax.set_xlabel(labelX) ax.set_ylabel(labelY)## fig.tight_layout() plt.show()returnTrue## color_style examples: 'r-', 'b:', 'g--'def plot_Fhat_chart(self, FhatI_theta_I, thetasX, labelX, labelY, title, color_style, thetaStar): mpl.rcParams['lines.linewidth'] =1.2 xylabelsize =16## plt.figure(figsize=(13, 9)) plt.figure(figsize=(13, 4)) plt.title(title, fontsize=20) Fhats = FhatI_theta_I.values() plt.plot(thetasX, Fhats, color_style) plt.axvline(x=thetaStar, color='k', linestyle=':') plt.xlabel(labelX, rotation=0, labelpad=10, ha='right', va='center', fontweight='bold', size=xylabelsize) plt.ylabel(labelY, rotation=0, labelpad=1, ha='right', va='center', fontweight='normal', size=xylabelsize) plt.show()## expanding Fhat chartdef plot_expFhat_chart(self, df, labelX, labelY, title, color_style): mpl.rcParams['lines.linewidth'] =1.2 xylabelsize =16 plt.figure(figsize=(13, 4)) plt.title(title, fontsize=20) plt.plot(df, color_style) plt.xlabel(labelX, rotation=0, labelpad=10, ha='right', va='center', fontweight='bold', size=xylabelsize) plt.ylabel(labelY, rotation=0, labelpad=1, ha='right', va='center', fontweight='normal', size=xylabelsize) plt.show()## expanding Fhat chartsdef plot_expFhat_charts(self, means, stdvs, labelX, labelY, suptitle, pars=defaultdict(str)): n_charts =2 xlabelsize =14 ylabelsize =14 mpl.rcParams['lines.linewidth'] =1.2 default_colors = plt.rcParams['axes.prop_cycle'].by_key()['color'] fig, axs = plt.subplots(n_charts, sharex=True) fig.set_figwidth(13); fig.set_figheight(9) fig.suptitle(suptitle, fontsize=18) xi =0 legendlabels = [] axs[xi].set_title(r"$exp\bar{C}^{cum}(\theta^*)$", loc='right', fontsize=16)for i,itm inenumerate(means.items()): axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) leg = axs[xi].plot(itm[1], color=pars['colors'][i]) legendlabels.append(itm[0]) axs[xi].set_ylabel(labelY, rotation=0, ha='right', va='center', fontweight='normal', size=ylabelsize) xi =1 axs[xi].set_title(r"$exp\tilde{C}^{cum}(\theta^*)$", loc='right', fontsize=16)for i,itm inenumerate(stdvs.items()): axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False)## leg = axs[xi].plot(itm[1], default_colors[i], linestyle='--') leg = axs[xi].plot(itm[1], pars['colors'][i], linestyle='--') axs[xi].set_ylabel(labelY, rotation=0, ha='right', va='center', fontweight='normal', size=ylabelsize) fig.legend(## [leg], labels=legendlabels, title="Policies", loc='upper right', fancybox=True, shadow=True, ncol=1) plt.xlabel(labelX, rotation=0, labelpad=10, ha='right', va='center', fontweight='normal', size=xlabelsize) plt.show()def plot_records(self, df, df_non, pars=defaultdict(str)): n_a =len(aNAMES) n_b =len(bNAMES) n_x =1 n_charts = n_x + n_b + n_b +2+ n_a +1 ylabelsize =14 mpl.rcParams['lines.linewidth'] =1.2 mycolors = ['g', 'b'] fig, axs = plt.subplots(n_charts, sharex=True)## fig.set_figwidth(13); fig.set_figheight(9) fig.set_figwidth(13); fig.set_figheight(20) fig.suptitle(pars['suptitle'], fontsize=14) xi =0 i =0 axs[xi+i].set_ylim(auto=True); axs[xi+i].spines['top'].set_visible(False); axs[xi+i].spines['right'].set_visible(True); axs[xi+i].spines['bottom'].set_visible(False) axs[xi+i].step(df[f'x_t'], 'm-', where='post')ifnot df_non isNone: axs[xi+i].step(df_non[f'x_t'], 'c-.', where='post') axs[xi+i].axhline(y=0, color='k', linestyle=':') y1ab ='$x_{t}$' axs[xi+i].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df.shape[0]//T): axs[xi+i].axvline(x=(j+1)*T, color='grey', ls=':') xi = n_xfor i,rt inenumerate(RESOURCE_TYPES): y1ab ='$D_{t,'+f'{rt}'+'}$' axs[xi+i].set_ylim(auto=True); axs[xi+i].spines['top'].set_visible(False); axs[xi+i].spines['right'].set_visible(True); axs[xi+i].spines['bottom'].set_visible(False) axs[xi+i].step(df[f'D_t_{rt}'], mycolors[xi%len(mycolors)], where='post')ifnot df_non isNone: axs[xi+i].step(df_non[f'D_t_{rt}'], 'c-.', where='post') axs[xi+i].axhline(y=SIM.muD[rt], color='k', linestyle=':') axs[xi+i].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df.shape[0]//T): axs[xi+i].axvline(x=(j+1)*T, color='grey', ls=':') xi = n_x + n_bfor i,b inenumerate(bNAMES): y1ab ='$D^{cum}_{t,'+f'{b}'+'}$' axs[xi+i].set_ylim(auto=True); axs[xi+i].spines['top'].set_visible(False); axs[xi+i].spines['right'].set_visible(True); axs[xi+i].spines['bottom'].set_visible(False) axs[xi+i].step(df[f'Dcum_t_{b}'], mycolors[xi%len(mycolors)], where='post')ifnot df_non isNone: axs[xi+i].step(df_non[f'Dcum_t_{b}'], 'c-.', where='post') axs[xi+i].axhline(y=0, color='k', linestyle=':') axs[xi+i].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df.shape[0]//T): axs[xi+i].axvline(x=(j+1)*T, color='grey', ls=':') xi = n_x + n_b + n_b y1ab ='$L^{Short}_{t}$' axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df[f'LShort_t'], 'r-', where='post')ifnot df_non isNone: axs[xi].step(df_non[f'LShort_t'], 'c-.', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') axs[xi].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') xi = n_x + n_b + n_b +1 y1ab ='$L^{Long}_{t}$' axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df[f'LLong_t'], 'r-', where='post')ifnot df_non isNone: axs[xi].step(df_non[f'LLong_t'], 'c-.', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') axs[xi].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') xi = n_x + n_b + n_b +2for i,a inenumerate(aNAMES): axs[xi+i].set_ylim(auto=True); axs[xi+i].spines['top'].set_visible(False); axs[xi+i].spines['right'].set_visible(True); axs[xi+i].spines['bottom'].set_visible(False) axs[xi+i].step(df[f'RInvsOut_t_{a}'], 'm-', where='post') axs[xi+i].step(df[f'RDuration_t_{a}'], 'k:', where='post')ifnot df_non isNone: axs[xi+i].step(df_non[f'RInvsOut_t_{a}'], 'c-.', where='post')ifnot df_non isNone: axs[xi+i].step(df_non[f'RDuration_t_{a}'], 'c-.', where='post') axs[xi+i].axhline(y=0, color='k', linestyle=':') al = a.split('_'); al = al[0]+'\_'+al[1]; y1ab ='$R^{InvsOut}_{t,'+f'{al}'+'}$' axs[xi+i].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df.shape[0]//T): axs[xi+i].axvline(x=(j+1)*T, color='grey', ls=':') xi = n_x + n_b + n_b +2+ n_a axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df['Ccum'], 'm-', where='post')ifnot df_non isNone: axs[xi].step(df_non['Ccum'], 'c-.', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') axs[xi].set_ylabel('$C^{cum}$'+'\n'+'$\mathrm{(Profit)}$'+'\n'+''+'$\mathrm{[\$]}$', rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize);for j inrange(df.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') axs[xi].set_xlabel('$t\ \mathrm{[decision\ windows]}$', rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize);if(pars['legendLabels']): fig.legend(labels=pars['legendLabels'], loc='lower left', fontsize=16)def plot_evalu_comparison(self, df1, df2, df3, pars=defaultdict(str)): legendlabels = ['X__BuyBelow', 'X__Bellman'] n_charts =5 ylabelsize =14 mpl.rcParams['lines.linewidth'] =1.2 fig, axs = plt.subplots(n_charts, sharex=True) fig.set_figwidth(13); fig.set_figheight(9) thetaStarStr = []forcmpin pars["thetaStar"]: thetaStarStr.append(f'{cmp:.1f}') thetaStarStr ='('+', '.join(thetaStarStr) +')' fig.suptitle(pars['suptitle'], fontsize=14) xi =0 axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df1[f'x_t'], 'r-', where='post') axs[xi].step(df2[f'x_t'], 'g-.', where='post') axs[xi].step(df3[f'x_t'], 'b:', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') y1ab ='$x_{t}$' axs[xi].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df1.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') xi =1 axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df1[f'R_t'], 'r-', where='post') axs[xi].step(df2[f'R_t'], 'g-.', where='post') axs[xi].step(df3[f'R_t'], 'b:', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') y1ab ='$R_{t}$' axs[xi].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df1.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') xi =2 axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df1[f'p_t'], 'r-', where='post') axs[xi].step(df2[f'p_t'], 'g-.', where='post') axs[xi].step(df3[f'p_t'], 'b:', where='post') axs[xi].axhline(y=0, color='k', linestyle=':')if(pars['lower_non']): axs[xi].text(-4, pars['lower_non'], r'$\theta^{lower}$'+f"={pars['lower_non']:.1f}", size=10, color='c')if(pars['lower_non']): axs[xi].axhline(y=pars['lower_non'], color='c', linestyle=':')if(pars['upper_non']): axs[xi].text(-4, pars['upper_non'], r'$\theta^{upper}$'+f"={pars['upper_non']:.1f}", size=10, color='c')if(pars['upper_non']): axs[xi].axhline(y=pars['upper_non'], color='c', linestyle=':')if(pars['lower']): axs[xi].text(-4, pars['lower'], r'$\theta^{lower}$'+f"={pars['lower']:.1f}", size=10, color='m')if(pars['lower']): axs[xi].axhline(y=pars['lower'], color='m', linestyle=':')if(pars['upper']): axs[xi].text(-4, pars['upper'], r'$\theta^{upper}$'+f"={pars['upper']:.1f}", size=10, color='m')if(pars['upper']): axs[xi].axhline(y=pars['upper'], color='m', linestyle=':')if(pars['alpha_non']): axs[xi].text(-4, pars['alpha_non'], r'$\theta^{alpha}$'+f"={pars['alpha_non']:.1f}", size=10, color='c')if(pars['alpha_non']): axs[xi].axhline(y=pars['alpha_non'], color='c', linestyle=':')if(pars['trackSignal_non']): axs[xi].text(-4, pars['trackSignal_non'], r'$\theta^{trackSignal}$'+f"={pars['trackSignal_non']:.1f}", size=10, color='c')if(pars['trackSignal_non']): axs[xi].axhline(y=pars['trackSignal_non'], color='c', linestyle=':')if(pars['alpha']): axs[xi].text(-4, pars['alpha'], r'$\theta^{alpha}$'+f"={pars['alpha']:.1f}", size=10, color='m')if(pars['alpha']): axs[xi].axhline(y=pars['alpha'], color='m', linestyle=':')if(pars['trackSignal']): axs[xi].text(-4, pars['trackSignal'], r'$\theta^{trackSignal}$'+f"={pars['trackSignal']:.1f}", size=10, color='m')if(pars['trackSignal']): axs[xi].axhline(y=pars['trackSignal'], color='m', linestyle=':') y1ab ='$p_{t}$' axs[xi].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df1.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') xi =3 axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df1['b_t_val'], 'r-', where='post') axs[xi].step(df2['b_t_val'], 'g-.', where='post') axs[xi].step(df3['b_t_val'], 'b:', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') y1ab ='$b_{t,val}$' axs[xi].set_ylabel(y1ab, rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize)for j inrange(df1.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') xi =4 axs[xi].set_ylim(auto=True); axs[xi].spines['top'].set_visible(False); axs[xi].spines['right'].set_visible(True); axs[xi].spines['bottom'].set_visible(False) axs[xi].step(df1['Ccum'], 'r-', where='post') axs[xi].step(df2['Ccum'], 'g-.', where='post') axs[xi].step(df3['Ccum'], 'b:', where='post') axs[xi].axhline(y=0, color='k', linestyle=':') axs[xi].set_ylabel('$\mathrm{cumC}$'+'\n'+'$\mathrm{(Profit)}$'+'\n'+''+'$\mathrm{[\$]}$', rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize); axs[xi].set_xlabel('$t\ \mathrm{[decision\ windows]}$', rotation=0, ha='right', va='center', fontweight='bold', size=ylabelsize);for j inrange(df1.shape[0]//T): axs[xi].axvline(x=(j+1)*T, color='grey', ls=':') fig.legend(## [leg], labels=legendlabels, title="Policies", loc='upper right', fontsize=16, fancybox=True, shadow=True, ncol=1)
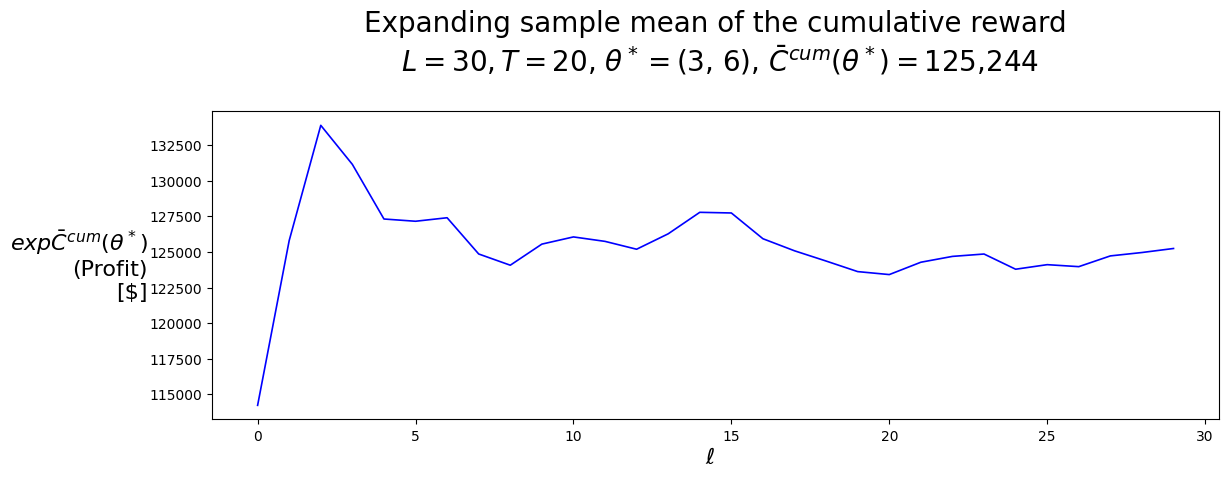
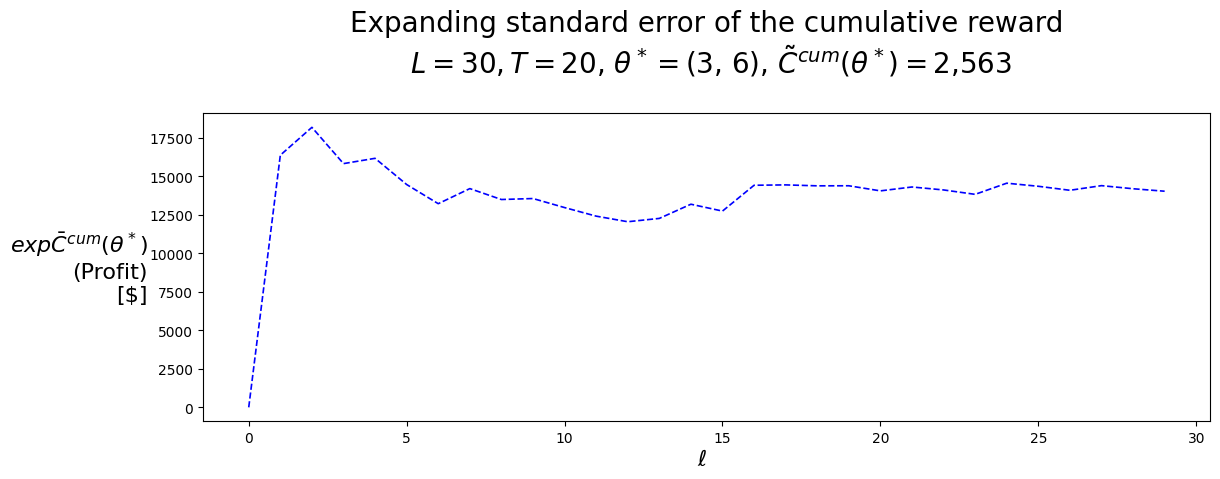
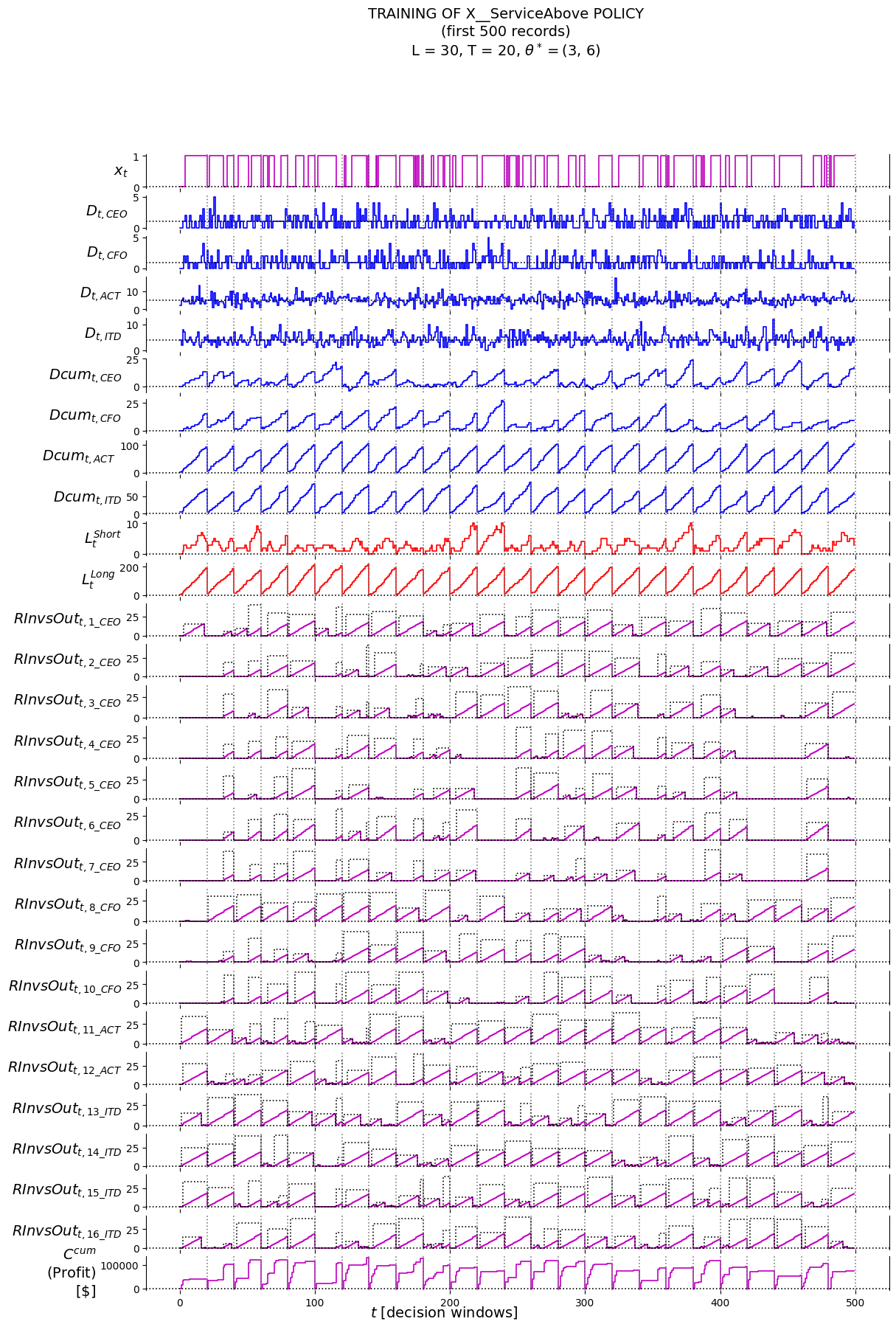
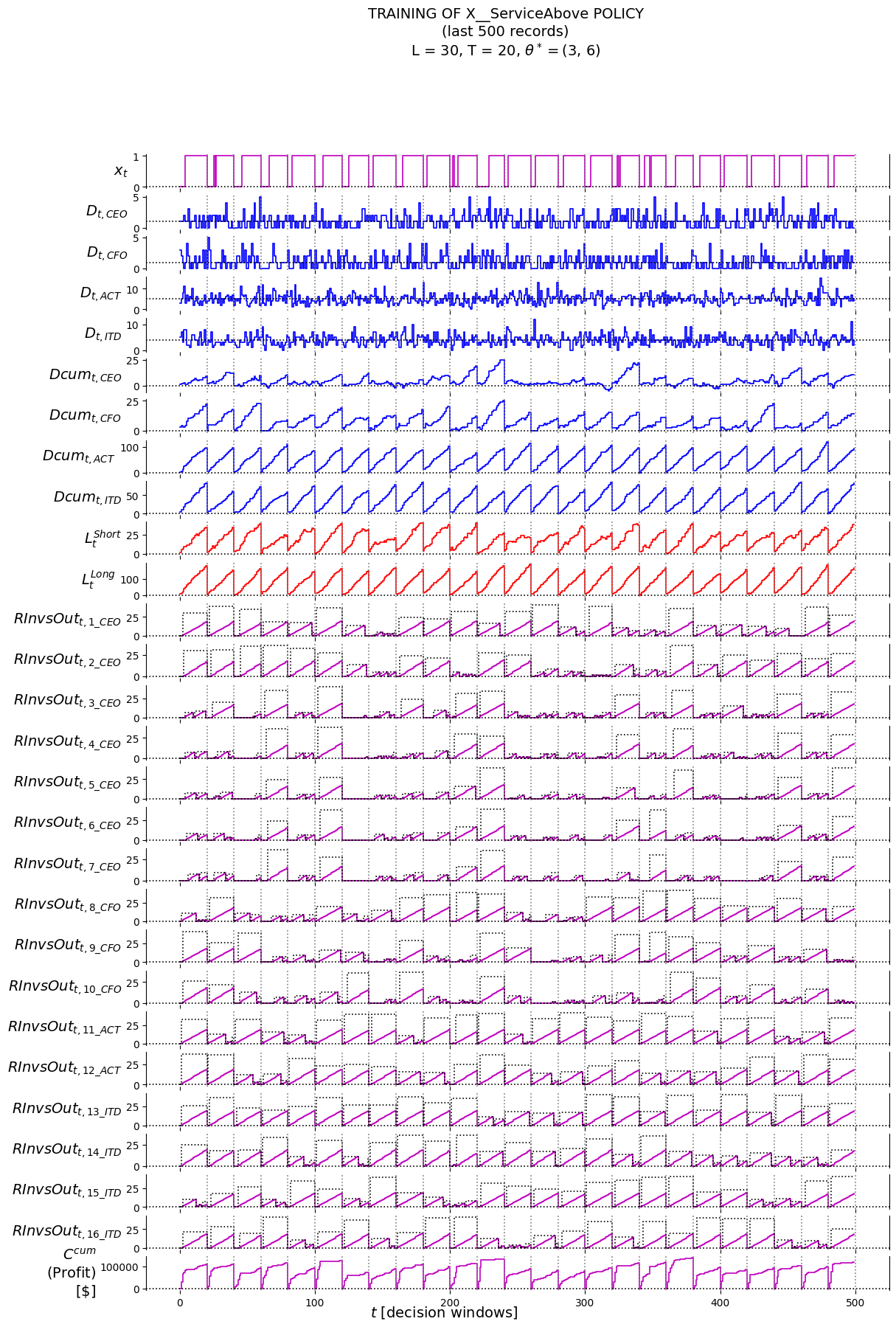
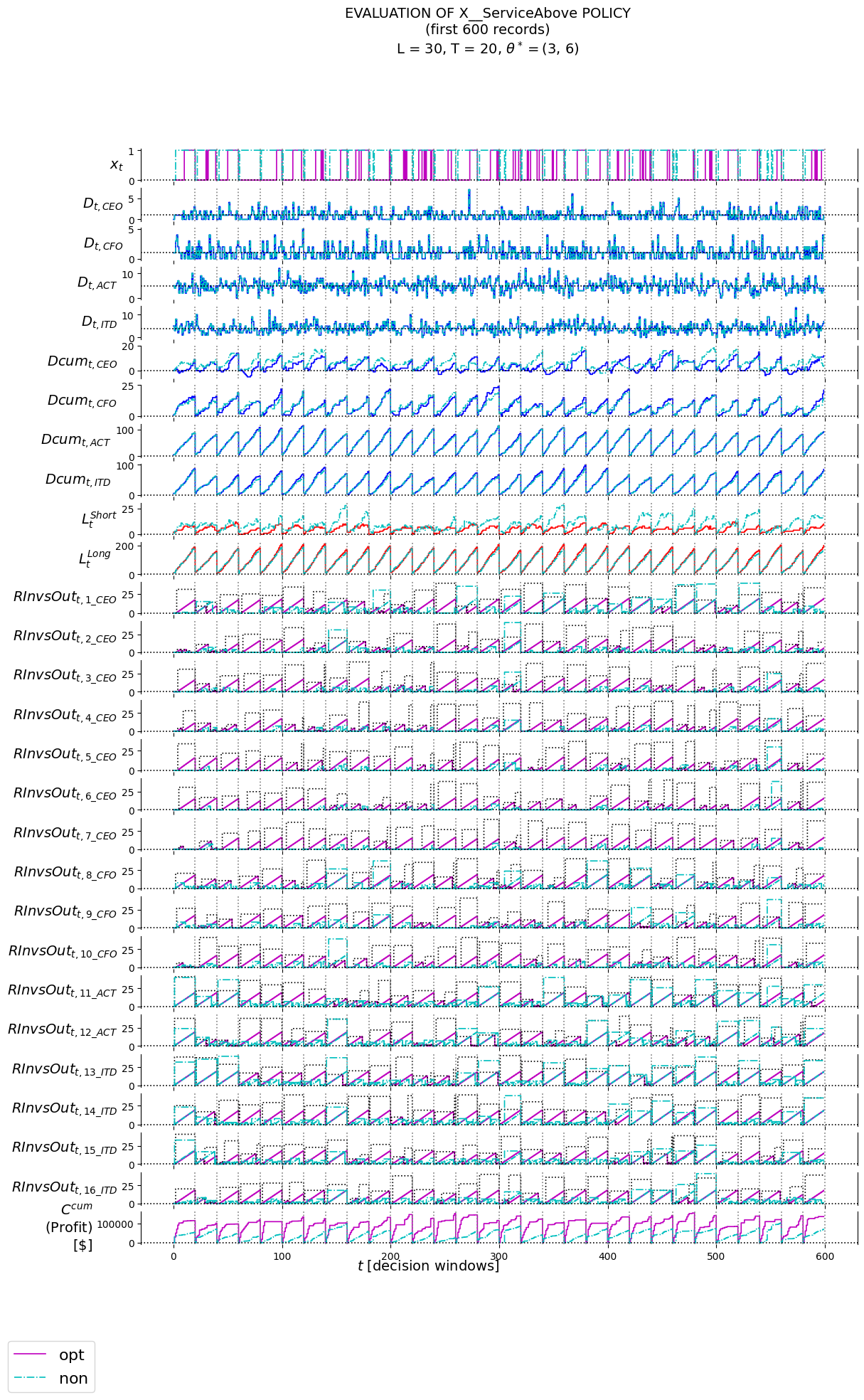
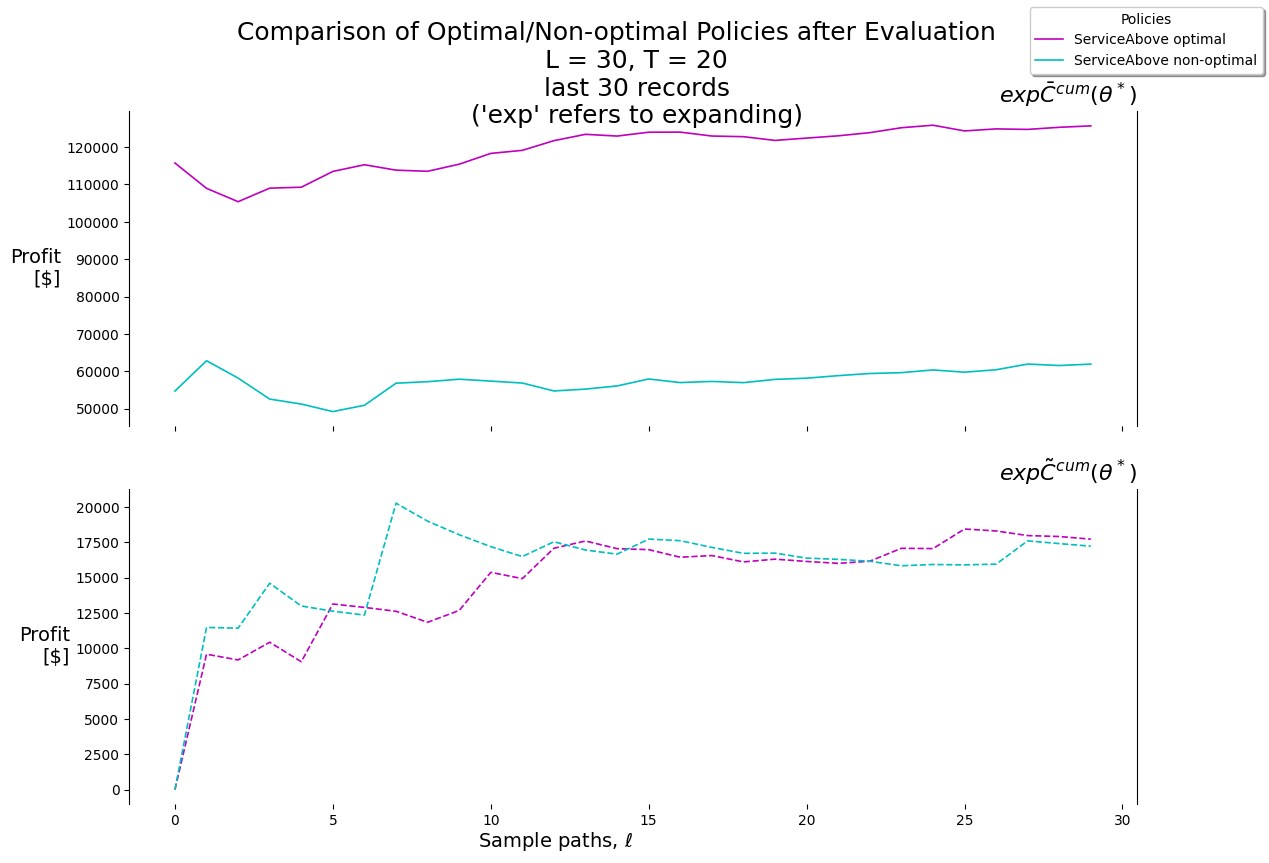
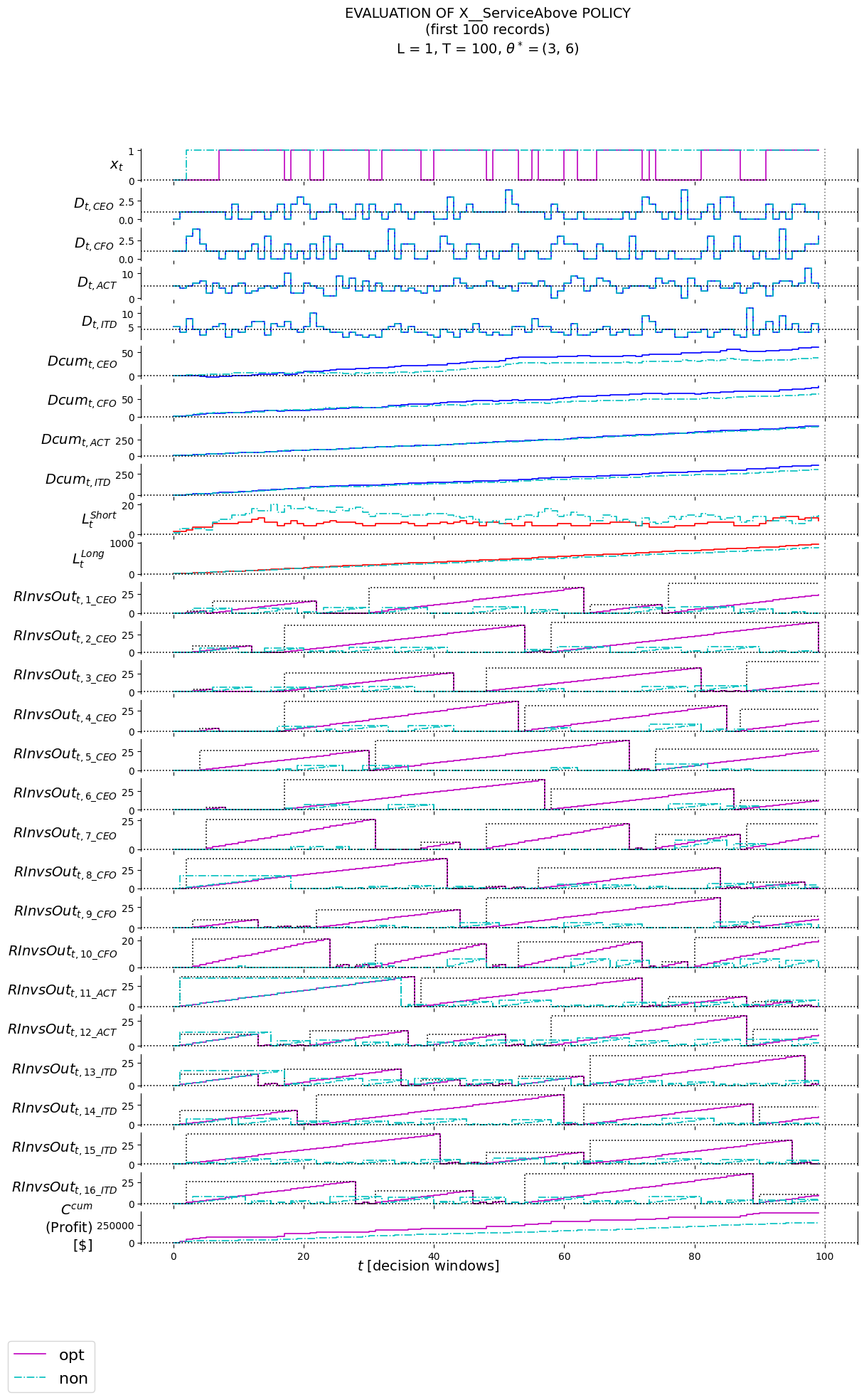
4.6 Policy Evaluation
4.6.1 Training/Tuning
## setup labels to plot infoRInvsOut_t_labels = ['RInvsOut_t_'+an for an in aNAMES]RDuration_t_labels = ['RDuration_t_'+an for an in aNAMES]D_t_labels = ['D_t_'+rt for rt in RESOURCE_TYPES]Dcum_t_labels = ['Dcum_t_'+rt for rt in RESOURCE_TYPES]LShort_t_labels = ['LShort_t']LLong_t_labels = ['LLong_t']x_t_labels = ['x_t']labels = ['piName', 'theta', 'l'] +\ ['t'] +\ RInvsOut_t_labels + RDuration_t_labels +\ D_t_labels + Dcum_t_labels +\ LShort_t_labels +\ LLong_t_labels +\ ['Ccum'] +\ x_t_labels