from pathlib import Path
import pandas as pd
import glob
import re
import plotly.express as px
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import statsmodels.api as sm
import numpy as npPurpose
Machine translation is used increasingly to lighten the load of human translators. The critical component here is the translation engine which is a model that takes a sequence of source words and outputs another sequence of translated words. To train such a model many thousands of sentence pairs need to be aligned for training examples.
This project is about constructing a translation engine, from English to Luganda, for a client in Uganda.
Dataset and Variables
A data-point in the dataset comes in the form of a sequence of “scalars” of type (nominal) categorical. The value assumed by each categorical is one of the words in the vocabulary for each language. Put in simple terms, each data-point is a English/Luganda sentence pair.
Currently, there are only 31,172 sentence pairs. This is not sufficient for a good enough translation engine. However, this can serve as a base to build upon and to derive an initial BLEU score for the engine.
In summary, the features of the dataset are:
- English sentence
- Luganda sentence
There is a relationship between the number of words (and the number of characters) in the source language and the target language. These relationships can be used to help identify miss-alignments in the training data. We make use of visualizations as well as the technique of identifying outliers beyond 3 sample standard deviations. So-called studentized outliers are used after fitting an Ordinary Least Squares (OLS) model.
Data preparation process
Training data is forwarded as newly translated documents are completed. The current training data is extracted from about 24 translated documents.
After a new translation is supplied, a human aligner aligns the Luganda text against an English file, separeted into sentences. This part of the process is error-prone. Consequently, the file with the alignments is dropped into a folder called WORK_PATH and then subjected to a Java-based suite of data preparation utilities:
- validator.jar
- selector.jar
- inspector.jar
- separator.jar
Setup the Environment
!python --versionPython 3.7.1Part 1(a): Prepare Data for a Single Document
#
# set the language
LANG = 'LUG'; print(LANG)LUGValidator
#
# set the prefix for files
# PREFIX = '19'; print(PREFIX)
PREFIX = 'CA'; print(PREFIX)CA#
# set the suffix for original English file
# ORIG_SUFFIX = 't'
ORIG_SUFFIX = 'B123'
# ORIG_SUFFIX = 'B123E1R'
print(ORIG_SUFFIX)B123#
# set English and Other language filenames
ENG = !ls {WORK_PATH}/{PREFIX}*_*_ENG_*-P*.txt
ENG = ENG[0].split('/')[-1].split('.')[0]
OTH = !ls {WORK_PATH}/{PREFIX}*_*_{LANG}_*-P*.txt
OTH = OTH[0].split('/')[-1].split('.')[0]#
# set Original English filename
ENG_ORIG = !ls {WORK_PATH}/{PREFIX}*_*_ENG_*-{ORIG_SUFFIX}.txt
ENG_ORIG = ENG_ORIG[0].split('/')[-1].split('.')[0]#
#find number of lines (including blank lines) to calc utilization
ENG_N_LINES = !wc -l {WORK_PATH}/"{ENG}".txt
ENG_N_LINES = int(ENG_N_LINES[0].split('/')[0])#
#find number of lines (including blank lines) to calc utilization
ENG_ORIG_N_LINES = !wc -l {WORK_PATH}/"{ENG_ORIG}".txt
ENG_ORIG_N_LINES = int(ENG_ORIG_N_LINES[0].split('/')[0])
print('SENTENCE UTILIZATION:', ENG_N_LINES/ENG_ORIG_N_LINES)SENTENCE UTILIZATION: 0.9747736093143596#
# validator.jar tries to align English with Other language sentences
# !java -jar {UTIL_PATH}/validator.jar {WORK_PATH}/{ENG}.txt {WORK_PATH}/{OTH}.txt#
#missed marks that human aligner might have entered to indicate problems
# !cat {WORK_PATH}/19*_*_{LANG}_*.txt | grep XX
!cat {WORK_PATH}/{PREFIX}*_*_{LANG}_*.txt | grep XX#
#missed marks that human aligner might have entered to indicate problems
# !cat {WORK_PATH}/19*_*_{LANG}_*.txt | grep xx
!cat {WORK_PATH}/{PREFIX}*_*_{LANG}_*.txt | grep xx#
#missed marks that human aligner might have entered to indicate problems
# !cat {WORK_PATH}/19*_*_{LANG}_*.txt | grep !!
!cat {WORK_PATH}/{PREFIX}*_*_{LANG}_*.txt | grep !!#
#write -v file
!java -jar {UTIL_PATH}/validator.jar {WORK_PATH}/"{ENG}".txt {WORK_PATH}/"{OTH}".txt > {WORK_PATH}/0_"{ENG}"___"{OTH}"-v.txtSelector
def print_pairs(pairs_list):
for i,p in enumerate(pairs_list):
print(p)
if i%2==1:
if pairs_list[i-1].split(' ',1)[0] != pairs_list[i].split(' ',1)[0]:
print('================ NOT A PAIR:', pairs_list[i-1].split(' ',1)[0], pairs_list[i].split(' ',1)[0])
break
else:
print('\n')#
#write -m file (contains all sentence matches)
!java -jar {UTIL_PATH}/selector.jar {WORK_PATH}/0_*-v.txt > {WORK_PATH}/0_"{ENG}"___"{OTH}"-m.txt#
#remove header
!tail -n +7 {WORK_PATH}/0_"{ENG}"___"{OTH}"-m.txt > {WORK_PATH}/new-m.txt
!mv {WORK_PATH}/new-m.txt {WORK_PATH}/0_"{ENG}"___"{OTH}"-m.txtInspector
#
#works better in a maxed command line window with small font
# !java -jar {UTIL_PATH}/inspector.jar {WORK_PATH}/0_*-m.txt 40Visualize this document’s data
This visualization will help to identify outliers in terms of character length as well as word length.
#
# function to convert a -m file to a dataframe
def dash_m_to_dataframe(all_files):
dfs = []
for i,filepath in enumerate(all_files):
#print(filepath)
filename = filepath.split('/')[-1]; print(filename)
f = open(filepath, 'r', encoding='utf-8')
f.readline() #remove title line
rows = []
parts = filename.split('_')
descriptor = parts[1]; #print('descriptor=', descriptor)
lan_E = 'ENG'
version_E = parts[4]
lan_O = parts[9]
version_O = parts[10].split('-m.')[0]
eng_line = f.readline(); #print('eng_line =', eng_line)
while eng_line != "":
try:
signature_E,content_E = eng_line.split(" ", 1)
except:
print('------- EXCEPTION: ', filepath)
print('eng_line =', eng_line)
chars_E = len(content_E)
words_E = len(re.findall(r'\w+', content_E))
if not re.search("^[0-9]+\.[0-9]+\.[ncspqhijk]$", signature_E):
print(f"------- INVALID ENG SIGNATURE: {signature_E}")
oth_line = f.readline(); #print('oth_line =', oth_line)
try:
signature_O,content_O = oth_line.split(" ", 1)
except:
print('------- EXCEPTION: ', filepath)
print('oth_line =', oth_line)
chars_O = len(content_O)
words_O = len(re.findall(r'\w+', content_O))
if not re.search("^[0-9]+\.[0-9]+\.[ncspqhijk]$", signature_O):
print(f"------- INVALID OTH SIGNATURE: {signature_O}")
blank_line = f.readline()
row = [descriptor, signature_E, lan_E, version_E, content_E, chars_E, words_E, lan_O, version_O, content_O, chars_O, words_O]; #print('row', row)
rows.append(row)
eng_line = f.readline(); #print('eng_line =', eng_line)
#if i==200: break
df = pd.DataFrame(rows)
dfs.append(df)
df_A = pd.concat(dfs, axis=0, ignore_index=True)
df_A.columns = ['descriptor','sign','lan_E','version_E','content_E','chars_E','words_E','lan_O','version_O','content_O','chars_O','words_O']
# pd.set_option('display.max_colwidth',20)
print(df_A.shape)
return df_A#
#inspect the ranges of some key features
df_file.loc[:, ['chars_E','chars_O','words_E','words_O']].describe()| chars_E | chars_O | words_E | words_O | |
|---|---|---|---|---|
| count | 1383.000000 | 1383.000000 | 1383.000000 | 1383.000000 |
| mean | 79.023138 | 83.774403 | 15.114244 | 12.201735 |
| std | 58.934272 | 62.557676 | 11.042870 | 9.438456 |
| min | 4.000000 | 8.000000 | 1.000000 | 1.000000 |
| 25% | 35.000000 | 36.000000 | 7.000000 | 5.000000 |
| 50% | 62.000000 | 68.000000 | 12.000000 | 10.000000 |
| 75% | 107.000000 | 114.000000 | 20.500000 | 17.000000 |
| max | 408.000000 | 393.000000 | 75.000000 | 60.000000 |
Fit linear models to remove outliers
#
#chars
x = df_file.loc[:, ['chars_E']].values
y = df_file.loc[:, ['chars_O']].values
mod_c = sm.OLS(y, sm.add_constant(x)).fit() #add_constant() equiv of fit_intercept=True
influence = mod_c.get_influence()
leverage = influence.hat_matrix_diag #hat values
# cooks_d = influence.cooks_distance #Cook's D values (and p-values) as tuple of arrays
# sres_c = influence.resid_studentized_internal #standardized residuals
tres_c = influence.resid_studentized_external #studentized residuals
print('R-squared: \n', mod_c.rsquared)
# mod_c.summary()
mse_c = mod_c.mse_resid
# mod_c.mse_total
yh_c = mod_c.predict(sm.add_constant(x))R-squared:
0.9413148090749979#
#words
x = df_file.loc[:, ['words_E']].values
y = df_file.loc[:, ['words_O']].values
mod_w = sm.OLS(y, sm.add_constant(x)).fit() #add_constant() equiv of fit_intercept=True
influence = mod_w.get_influence()
leverage = influence.hat_matrix_diag #hat values
# cooks_d = influence.cooks_distance #Cook's D values (and p-values) as tuple of arrays
# sres_w = influence.resid_studentized_internal #standardized residuals
tres_w = influence.resid_studentized_external #studentized residuals
print('R-squared: \n', mod_w.rsquared)
# mod_w.summary()
mse_w = mod_w.mse_resid
# mod_w.mse_total
yh_w = mod_w.predict(sm.add_constant(x))R-squared:
0.9111426681625021#
#add yhat columns
df = df_file.copy()
df['yh_c'] = yh_c
df['yh_w'] = yh_w
# df.head()#
#add columns to indicate the presence of outliers
df['out_tres_c'] = False #char outlier
df['out_tres_w'] = False #word outlier
df['out_both'] = False #both outlier
df['outlier'] = 'not' #outlier type, n means not an outlier
# df['res'] = df['chars_O'] - df['prd_c']
# df['lev'] = leverage
# df['calc_sres'] = df['res']/(np.sqrt(mse*(1-df['lev'])))
df['tres_c'] = tres_c
df['tres_w'] = tres_w
df.loc[ np.abs(df['tres_c']) > 3, ['out_tres_c'] ] = True
df.loc[ np.abs(df['tres_c']) > 3, ['outlier'] ] = 'char' #char outlier
df.loc[ np.abs(df['tres_w']) > 3, ['out_tres_w'] ] = True
df.loc[ np.abs(df['tres_w']) > 3, ['outlier'] ] = 'word' #word outlier
df.loc[ (np.abs(df['tres_c']) > 3)&(np.abs(df['tres_w']) > 3), ['out_both'] ] = True
df.loc[ (np.abs(df['tres_c']) > 3)&(np.abs(df['tres_w']) > 3), ['outlier'] ] = 'both' #both outlier
print('total data-points:',len(df))
print('useful char data-points:',len(df[df['out_tres_c']==False]))
print('useful word data-points:',len(df[df['out_tres_w']==False]))
print('useful char & word data-points:',len(df[(df['out_tres_c']==False)&(df['out_tres_w']==False)]))
print('outlier char data-points:',len(df[df['out_tres_c']==True]))
print('outlier word data-points:',len(df[df['out_tres_w']==True]))
print('outlier char & word data-points:',len(df[df['out_both']==True]))
# df.head()total data-points: 1383
useful char data-points: 1358
useful word data-points: 1363
useful char & word data-points: 1350
outlier char data-points: 25
outlier word data-points: 20
outlier char & word data-points: 12sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='chars_E', y='chars_O',
#hue='out_tres_c',
hue='outlier',
#style='out_both',
data=df, alpha=.8, palette=palette)
ax.set_title("Translation Chars vs English Chars (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['chars_E'], df['yh_c'], color='grey', linestyle='-.', linewidth=.2);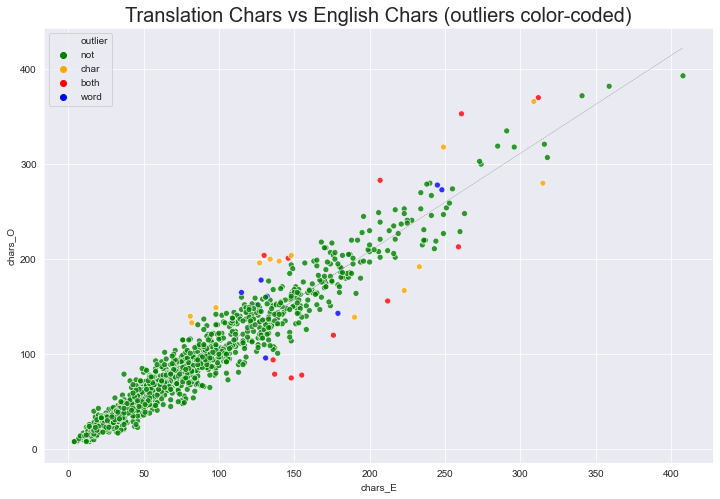
sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='words_E', y='words_O',
#hue='out_tres_w',
hue='outlier',
data=df, alpha=.8, palette=palette)
ax.set_title("Translation Words vs English Words (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['words_E'], df['yh_w'], color='grey', linestyle='-.', linewidth=.2);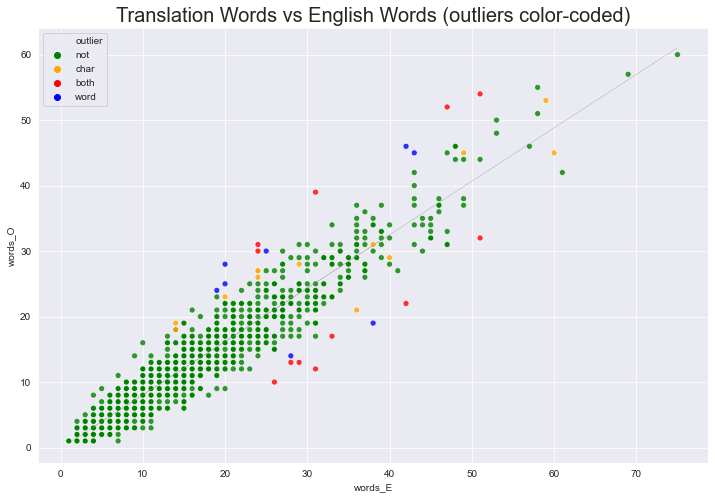
Separator (run in terminal) OR Generate separated files without outliers
Next, we remove all the outliers of type ‘both’. These are the ones visualized in red above.
Option 1: Run in terminal
Option 2: Generate separated files without outliers
#
#previous summary again
print('total data-points:',len(df))
print('useful char data-points:',len(df[df['out_tres_c']==False]))
print('useful word data-points:',len(df[df['out_tres_w']==False]))
print('useful char & word data-points:',len(df[(df['out_tres_c']==False)&(df['out_tres_w']==False)]))
print('outlier char data-points:',len(df[df['out_tres_c']==True]))
print('outlier word data-points:' ,len(df[df['out_tres_w']==True]))
print('outlier char & word data-points:',len(df[df['out_both']==True]))total data-points: 1383
useful char data-points: 1358
useful word data-points: 1363
useful char & word data-points: 1350
outlier char data-points: 25
outlier word data-points: 20
outlier char & word data-points: 12Option 1: Doing -PO files (ENG and OTH)
#
# DON'T USE THIS OPTION: We may want to change the definition of an outlier in the future,
# e.g. only values beyond 4 sample standard deviations. This option throws away outliers permanently.
# if doing -PO files:
# manually delete the outliers in the previous cell (from both -P files and change names to -PO)
# and run again from the top, UNTIL no more combined outliers
# df_O = df.copy()Option 2: Doing -P files (ENG and OTH)
#
# if doing -P files:
# find outliers on BOTH counts (char model AND word model), drop them
# ixs = df[(df['out_tres_c']==True)&(df['out_tres_w']==True)].index; print(ixs)
out_ixs = df[df['out_both']==True].index; print(out_ixs)Int64Index([22, 26, 142, 202, 340, 347, 520, 708, 955, 1078, 1157, 1271], dtype='int64')#
# if doing -P files: drop outliers
df_O = df.drop(out_ixs)print('total data-points:',len(df))
print('useful data-points:',len(df_O))
print('outlier char & word data-points:',len(df)-len(df_O))total data-points: 1383
useful data-points: 1371
outlier char & word data-points: 12assert( len(df) == len(df_O) + len(out_ixs) )sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='chars_E', y='chars_O',
#hue='out_tres_c',
hue='outlier',
#style='out_both',
data=df_O, alpha=.8, palette=palette)
ax.set_title("Translation Chars vs English Chars (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['chars_E'], df['yh_c'], color='grey', linestyle='-.', linewidth=.2);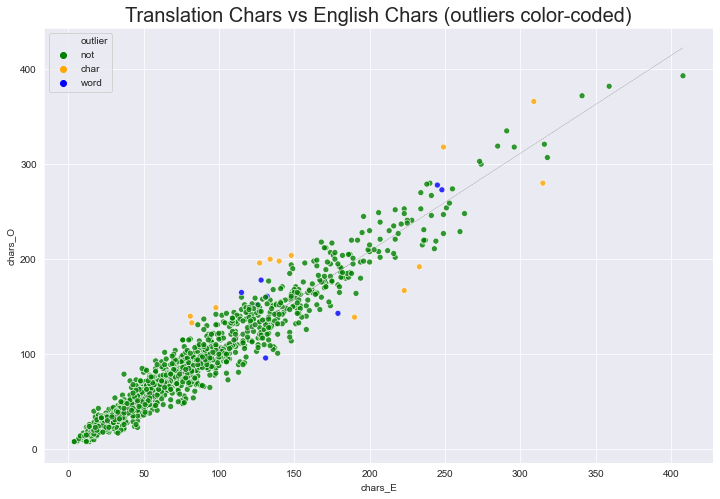
sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='words_E', y='words_O',
#hue='out_tres_w',
hue='outlier',
data=df_O, alpha=.8, palette=palette)
ax.set_title("Translation Words vs English Words (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['words_E'], df['yh_w'], color='grey', linestyle='-.', linewidth=.2);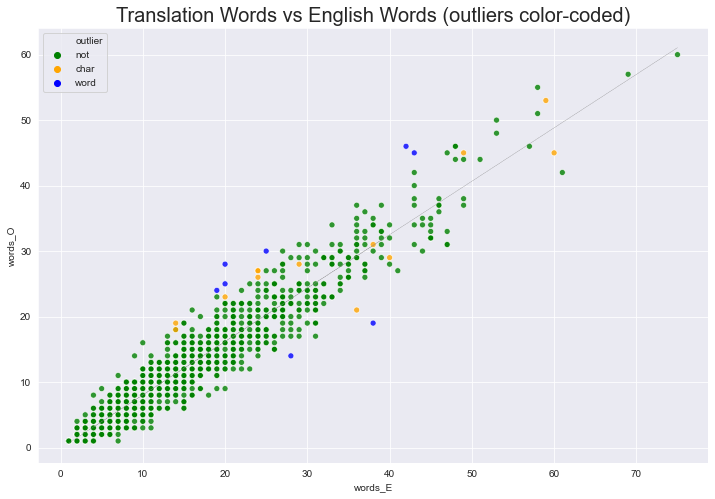
Write separated files
#
#find number of lines (including blank lines) to calc updated utilization
ENG_N_LINES = !wc -l {WORK_PATH}/"{ENG}".txt
ENG_N_LINES = int(ENG_N_LINES[0].split('/')[0])
print('ENG_N_LINES - len(out_ixs):', ENG_N_LINES - len(out_ixs))ENG_N_LINES - len(out_ixs): 1495#
#find number of lines (including blank lines) to calc updated utilization
ENG_ORIG_N_LINES = !wc -l {WORK_PATH}/"{ENG_ORIG}".txt
ENG_ORIG_N_LINES = int(ENG_ORIG_N_LINES[0].split('/')[0])
print('ENG_ORIG_N_LINES:', ENG_ORIG_N_LINES)
print('SENTENCE UTILIZATION (AFTER OUTLIER REMOVAL):', (ENG_N_LINES - len(out_ixs))/ENG_ORIG_N_LINES)ENG_ORIG_N_LINES: 1546
SENTENCE UTILIZATION (AFTER OUTLIER REMOVAL): 0.9670116429495472#
# NOTE: ALWAYS USE -PO TO END THE FILE NAME!
#write separated files
with(open(f'{WORK_PATH}/f_{ENG}___{OTH}.eng-PO.txt', mode='w', encoding='UTF-8')) as f:
for s in df_O['content_E']:
f.write(s)
with(open(f'{WORK_PATH}/e_{ENG}___{OTH}.{lang}-PO.txt', mode='w', encoding='UTF-8')) as f:
for s in df_O['content_O']:
f.write(s) Cleanup and move to MMDB
#
#remove -v and -i files
!rm ./0_"{ENG}"___"{OTH}"-v.txt
!rm ./0_"{ENG}"___"{OTH}"-m.txt
!rm {WORK_PATH}/0_"{ENG}"___"{OTH}"-v.txt
# !rm {WORK_PATH}/0_"{ENG}"___"{OTH}"-i.txt#
#move aligned source files to database folder
!mv {WORK_PATH}/"{ENG}".txt "{MMDB_OTH_PATH}"
!mv {WORK_PATH}/"{OTH}".txt "{MMDB_OTH_PATH}"#
#move -m file to database folder
!mv {WORK_PATH}/0_"{ENG}"___"{OTH}"-m.txt "{MMDB_OTH_PATH}"#
#move separated files to database folder
!mv {WORK_PATH}/e_"{ENG}"___"{OTH}".{lang}*.txt "{MMDB_OTH_PATH}"
!mv {WORK_PATH}/f_"{ENG}"___"{OTH}".eng*.txt "{MMDB_OTH_PATH}"#
#move original ENG file to database folder
!mv {WORK_PATH}/"{ENG_ORIG}".txt "{MMDB_ENG_PATH}"Part 1(b): Prepare Data for All Documents
Visualize data for all documents
#1h 15 mins for 116 files
#chars
x = df_all_files.loc[:, ['chars_E']].values
y = df_all_files.loc[:, ['chars_O']].values
mod_c = sm.OLS(y, sm.add_constant(x)).fit() #add_constant() equiv of fit_intercept=True
influence = mod_c.get_influence()
leverage = influence.hat_matrix_diag #hat values
# cooks_d = influence.cooks_distance #Cook's D values (and p-values) as tuple of arrays
# sres_c = influence.resid_studentized_internal #standardized residuals
tres_c = influence.resid_studentized_external #studentized residuals
print('R-squared: \n', mod_c.rsquared)
# mod_c.summary()
mse_c = mod_c.mse_resid
# mod_c.mse_total
yh_c = mod_c.predict(sm.add_constant(x))R-squared:
0.9457444061474136#1h 15 mins for 116 files
#words
x = df_all_files.loc[:, ['words_E']].values
y = df_all_files.loc[:, ['words_O']].values
mod_w = sm.OLS(y, sm.add_constant(x)).fit() #add_constant() equiv of fit_intercept=True
influence = mod_w.get_influence()
leverage = influence.hat_matrix_diag #hat values
# cooks_d = influence.cooks_distance #Cook's D values (and p-values) as tuple of arrays
# sres_w = influence.resid_studentized_internal #standardized residuals
tres_w = influence.resid_studentized_external #studentized residuals
print('R-squared: \n', mod_w.rsquared)
# mod_w.summary()
mse_w = mod_w.mse_resid
# mod_w.mse_total
yh_w = mod_w.predict(sm.add_constant(x))R-squared:
0.9146194429311921#
#add yhat columns
df = df_all_files.copy()
df['yh_c'] = yh_c
df['yh_w'] = yh_w
pd.set_option('display.max_colwidth',20)
# df.head()#
#add columns to indicate the presence of outliers
df['out_tres_c'] = False #char outlier
df['out_tres_w'] = False #word outlier
df['out_both'] = False #both outlier
df['outlier'] = 'not' #outlier type, n means not an outlier
df['tres_c'] = tres_c
df['tres_w'] = tres_w
df.loc[ np.abs(df['tres_c']) > 3, ['out_tres_c'] ] = True
df.loc[ np.abs(df['tres_c']) > 3, ['outlier'] ] = 'char' #char outlier
df.loc[ np.abs(df['tres_w']) > 3, ['out_tres_w'] ] = True
df.loc[ np.abs(df['tres_w']) > 3, ['outlier'] ] = 'word' #word outlier
df.loc[ (np.abs(df['tres_c']) > 3)&(np.abs(df['tres_w']) > 3), ['out_both'] ] = True
df.loc[ (np.abs(df['tres_c']) > 3)&(np.abs(df['tres_w']) > 3), ['outlier'] ] = 'both' #both outlier
print('total data-points:',len(df))
print('useful char data-points:',len(df[df['out_tres_c']==False]))
print('useful word data-points:',len(df[df['out_tres_w']==False]))
print('useful char & word data-points:',len(df[(df['out_tres_c']==False)&(df['out_tres_w']==False)]))
print('outlier char data-points:',len(df[df['out_tres_c']==True]))
print('outlier word data-points:',len(df[df['out_tres_w']==True]))
print('outlier char & word data-points:',len(df[df['out_both']==True]))
# df.head()total data-points: 31183
useful char data-points: 30659
useful word data-points: 30694
useful char & word data-points: 30429
outlier char data-points: 524
outlier word data-points: 489
outlier char & word data-points: 259sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='chars_E', y='chars_O',
#hue='out_tres_c',
hue='outlier',
#style='out_both',
data=df, alpha=.8, palette=palette)
ax.set_title("Translation Chars vs English Chars (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['chars_E'], df['yh_c'], color='grey', linestyle='-.', linewidth=.2);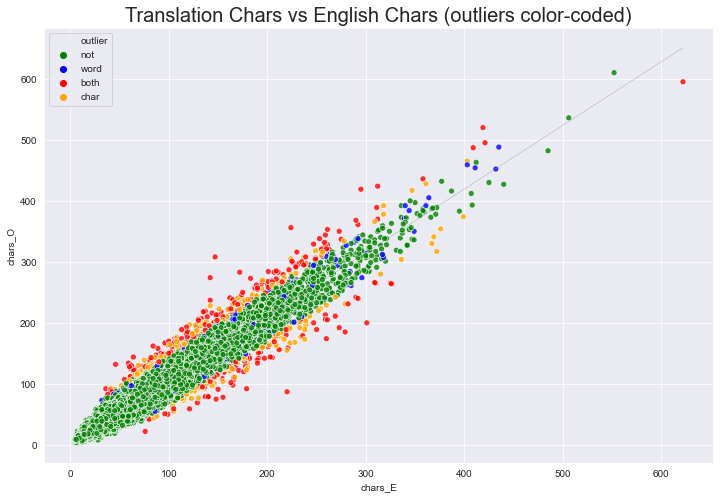
sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='words_E', y='words_O',
#hue='out_tres_w',
hue='outlier',
data=df, alpha=.8, palette=palette)
ax.set_title("Translation Words vs English Words (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['words_E'], df['yh_w'], color='grey', linestyle='-.', linewidth=.2);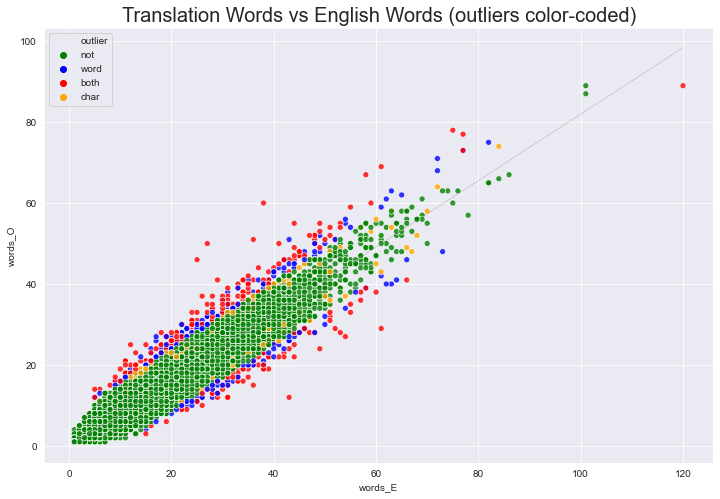
#
# find outliers on BOTH counts (char model AND word model), drop them
# ixs = df[(df['out_tres_c']==True)&(df['out_tres_w']==True)].index; print(ixs)
out_ixs = df[df['out_both']==True].index; print(out_ixs)Int64Index([ 31, 387, 390, 425, 431, 664, 989, 1155, 1180,
1362,
...
29306, 29518, 30253, 30456, 30487, 30489, 30532, 30604, 31059,
31080],
dtype='int64', length=259)#
# drop outliers
df_O = df.drop(out_ixs)print('total data-points:',len(df))
print('useful data-points:',len(df_O))
print('outlier char & word data-points:',len(df)-len(df_O))total data-points: 31183
useful data-points: 30924
outlier char & word data-points: 259assert( len(df) == len(df_O) + len(out_ixs) )sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='chars_E', y='chars_O',
#hue='out_tres_c',
hue='outlier',
#style='out_both',
data=df_O, alpha=.8, palette=palette)
ax.set_title("Translation Chars vs English Chars (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['chars_E'], df['yh_c'], color='grey', linestyle='-.', linewidth=.2);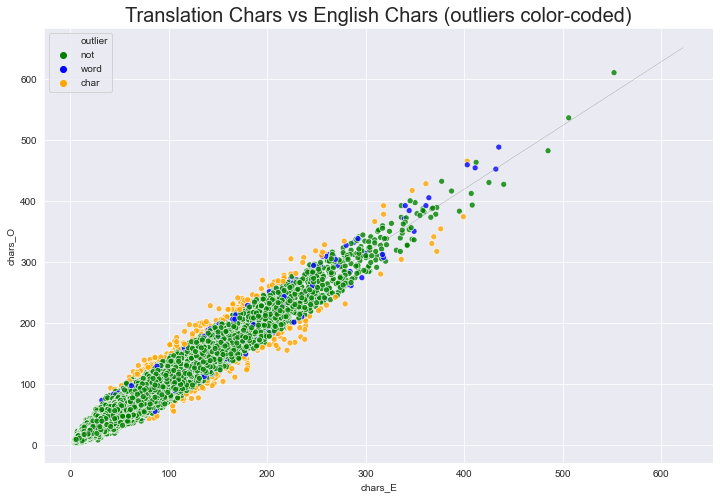
sns.set_style('darkgrid')
plt.figure(figsize=(12,8))
# palette = {False: 'green', True: 'red'}
palette = {'not': 'green', 'char': 'orange', 'word': 'blue', 'both': 'red'}
ax = sns.scatterplot(x='words_E', y='words_O',
#hue='out_tres_w',
hue='outlier',
data=df_O, alpha=.8, palette=palette)
ax.set_title("Translation Words vs English Words (outliers color-coded)", fontdict={'fontsize': 20})
plt.plot(df['words_E'], df['yh_w'], color='grey', linestyle='-.', linewidth=.2);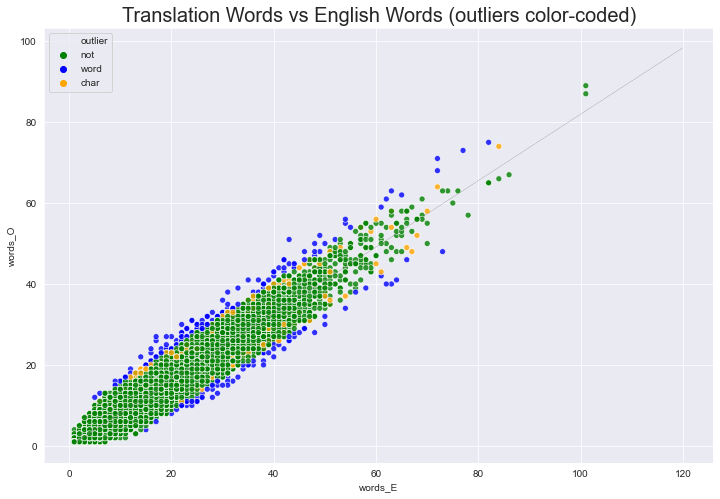
Save dash-m-dataframe
df.columnsIndex(['descriptor', 'sign', 'lan_E', 'version_E', 'content_E', 'chars_E',
'words_E', 'lan_O', 'version_O', 'content_O', 'chars_O', 'words_O',
'yh_c', 'yh_w', 'out_tres_c', 'out_tres_w', 'out_both', 'outlier',
'tres_c', 'tres_w'],
dtype='object')df.to_csv(f'{PATH}/dash-m-dataframe-{LANG}-O.csv', sep='~', index = False, header=True)Part 2: Position Train Data on Azure
The purpose of this part is to position the train data for the translation engine, on an Azure virtual machine (VM). On this VM a copy of opennmt was installed previously. Opennmt is built on the popular PyTorch deep learning framework.
- if not correct name endings (example):
- select all e_ files
- rename .en-af.af to .bem.txt
- select all f_ files
- rename .en-af.en to .eng.txt
- select all e_ files
For TrainSet: (only do when TrainSet has changed)
!cp "{MMDB_OTH_PATH}"/e_* {WORK_PATH}!cp "{MMDB_OTH_PATH}"/f_* {WORK_PATH}!ls -l {WORK_PATH}/e_* | wc -l 116!ls -l {WORK_PATH}/f_* | wc -l 116#
# - get names of train set, in a maxed mac terminal
# cd ~/work_train
# ls e_*
# - highlight all entries and copy
# - paste temporarily into textedit, then copy from here
# - open OpenNMTExperiment_OTH.xlsx, TrainSets tab
# - enter new TrainSet and paste in at the 'Titles' row
# - set the bottom of the sheet to 'Count'
# - select the paste and fill in the number of Messages!cat `ls {WORK_PATH}/f_*` > {WORK_PATH}/train.eng.txt!rm -f {WORK_PATH}/f_*!cat `ls {WORK_PATH}/e_*` > {WORK_PATH}/train.{lang}.txt!rm -f {WORK_PATH}/e_*#
# - open to validate, with vim
# = maximize a terminal on mac
# = vim .
# = select oth file
# = cmd+ until zoom level is OK
# = :vsp .
# = select eng file
# = :set number in both windows, use ctrl-w left/right to move between windows
# = :$ to go to end and see how many sentences, :1 to go to top again
# = take an evenly spread sample and verify alignment
# % use round numbers like 20000, 40000, 60000, etc //easier to recognize
# % locate with :20000, :40000, etc //puts target in center, easier to find
# % switch left-right with Ctrl-W, h/j
# = close vimEnd For TrainSet
For TestSet: (only do when TestSet has changed)
!cp "{MMDB_PATH}"/TestSet/e_* {WORK_PATH}!cp "{MMDB_PATH}"/TestSet/f_* {WORK_PATH}!ls -l {WORK_PATH}/e_* | wc -l!ls -l {WORK_PATH}/f_* | wc -l#
# - get names of train set, in a maxed mac terminal
# cd ~/work_train
# ls e_*
# - highlight all entries and copy
# - paste temporarily into textedit, then copy from here
# - open OpenNMTExperiment_OTH.xlsx, TestSets tab
# - enter new id and paste in at the correct position
# - set the bottom of the sheet to 'Count'
# - select the paste and fill in the # messages
# - ensure the id of the TestSet is updated manually in the
# next statements (matching above id):!cat `ls {WORK_PATH}/f_*` > {WORK_PATH}/valid1.eng.txt!rm -f {WORK_PATH}/f_*!cat `ls {WORK_PATH}/e_*` > {WORK_PATH}/valid1.{lang}.txt!rm -f {WORK_PATH}/e_*#
# - open to validate, with vim
# = maximize a terminal on mac
# = vim .
# = select oth file
# = cmd+ until zoom level is OK
# = :vsp .
# = select eng file
# = :set number in both windows, use ctrl-w left/right to move between windows
# = :$ to go to end and see how many sentences, :1 to go to top again
# = take an evenly spread sample and verify alignment
# % use round numbers like 20000, 40000, 60000, etc //easier to recognize
# % locate with :20000, :40000, etc //puts target in center, easier to find
# % switch left-right with Ctrl-W, h/j
# = close vimEnd For TestSet
Part 3: Train engine using opennmt
The purpose of this part is to train a translation engine, making use of training and validation data. Training happens on a VM in Azure, pre-installed with the PyTorch-based opennmt library.