The overall structure of this project and report follows the traditional CRISP-DM format. However, instead of the CRISP-DM’S “4 Modeling” section, we inserted the “6 step modeling process” of Dr. Warren Powell in section 4 of this document. Dr Powell’s universal framework shows great promise for unifying the formalisms of at least a dozen different fields. Using his framework enables easier access to thinking patterns in these other fields that might be beneficial and informative to the sequential decision problem at hand. Traditionally, this kind of problem would be approached from the reinforcement learning perspective. However, using Dr. Powell’s wider and more comprehensive perspective almost certainly provides additional value.
In order to make a strong mapping between the code in this notebook and the mathematics in the Powell Universal Framework (PUF), we follow the following convention for naming Python identifier names:
How to read/say
var name & flavor first
at t/n
for entity OR of/with attribute
\(\hat{R}^{fail}_{t+1,a}\) has code Rhat__fail_tt1_a which is read: “Rhatfail at t+1 of/with (attribute) a”
Superscripts
variable names have a double underscore to indicate a superscript
\(X^{\pi}\): has code X__pi, is read X pi
when there is a ‘natural’ distinction between the variable symbol and the superscript (e.g. a change in case), the double underscore is sometimes omitted: Xpi instead of X__pi, or MSpend_t instead of M__Spend_t
Subscripts
variable names have a single underscore to indicate a subscript
\(S_t\): has code S_t, is read ‘S at t’
\(M^{Spend}_t\) has code M__Spend_t which is read: “MSpend at t”
\(\hat{R}^{fail}_{t+1,a}\) has code Rhat__fail_tt1_a which is read: “Rhatfail at t+1 of/with (attribute) a” [RLSO-p436]
Arguments
collection variable names may have argument information added
\(X^{\pi}(S_t)\): has code X__piIS_tI, is read ‘X pi in S at t’
the surrounding I’s are used to imitate the parentheses around the argument
Next time/iteration
variable names that indicate one step in the future are quite common
\(R_{t+1}\): has code R_tt1, is read ‘R at t+1’
\(R^{n+1}\): has code R__nt1, is read ‘R at n+1’
Rewards
State-independent terminal reward and cumulative reward
\(F\): has code F for terminal reward
\(\sum_{n}F\): has code cumF for cumulative reward
State-dependent terminal reward and cumulative reward
\(C\): has code C for terminal reward
\(\sum_{t}C\): has code cumC for cumulative reward
Vectors where components use different names
\(S_t(R_t, p_t)\): has code S_t.R_t and S_t.p_t, is read ‘S at t in R at t, and, S at t in p at t’
the code implementation is by means of a named tuple
self.State = namedtuple('State', SVarNames) for the ‘class’ of the vector
self.S_t for the ‘instance’ of the vector
Vectors where components reuse names
\(x_t(x_{t,GB}, x_{t,BL})\): has code x_t.x_t_GB and x_t.x_t_BL, is read ‘x at t in x at t for GB, and, x at t in x at t for BL’
the code implementation is by means of a named tuple
self.Decision = namedtuple('Decision', xVarNames) for the ‘class’ of the vector
self.x_t for the ‘instance’ of the vector
Use of mixed-case variable names
to reduce confusion, sometimes the use of mixed-case variable names are preferred (even though it is not a best practice in the Python community), reserving the use of underscores and double underscores for math-related variables
1 BUSINESS UNDERSTANDING
The problem in this project was chosen as a starting example for a client need relating to making optimal investment decisions regarding a given portfolio. Although the present example only deals with the decision to either hold or to sell an asset, it is developed to provide the basis for expansion towards this need. It comes from the free book by Dr. Powell, Sequential Decision Analytics and Modeling. However, the code has been modified quite substantially.
The original code for this example can be found here.
2 DATA UNDERSTANDING
# import pdb# pdb.set_trace()from collections import namedtuple, defaultdictimport pandas as pdimport numpy as npimport randomimport matplotlib.pyplot as pltfrom matplotlib.ticker import FormatStrFormatterimport matplotlib as mplfrom copy import copyimport mathpd.options.display.float_format ='{:,.4f}'.formatpd.set_option('display.max_columns', None)pd.set_option('display.max_rows', None)pd.set_option('display.max_colwidth', None)! python --version
Python 3.10.12
The parameters of the system-under-steer (SUS) are:
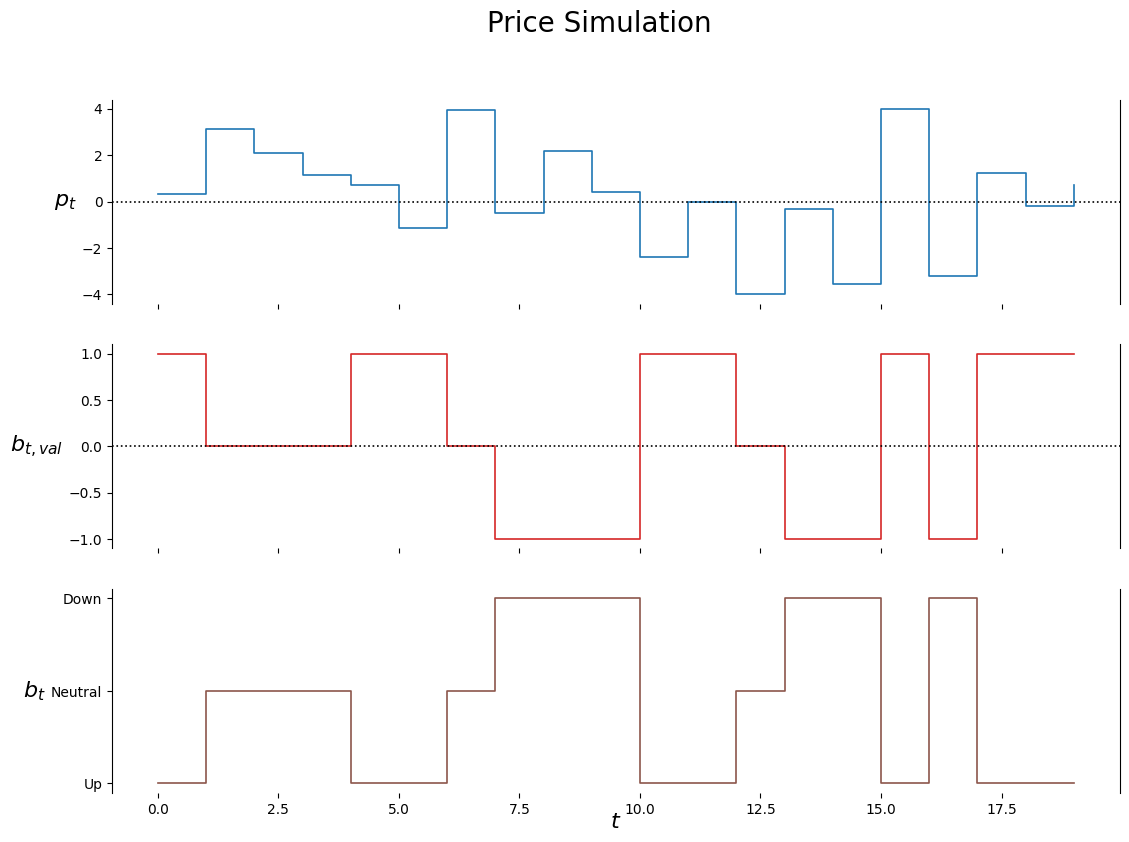
# EXAMPLE OF CUSTOMIZED SIMULATOR# x = ['Up', 'Neutral', 'Down']# biasCdfs = pd.DataFrame(# [[.9, 1., 1.], #'Up' cdf# [.2, .8, 1.], #'Neutral' cdf# [0., .1, 1.]], #'Down' cdf# index=x,# columns=x,# )# price_sim = PriceSimulator(# # T__sim=T__sim,# biasCdfs=biasCdfs,# upStep=1,# downStep=-1,# variance=W_Variance# )price_sim = PriceSimulator(seed=SEED_TRAIN) # use pars from spreadsheetT__sim =20PriceData = []for i inrange(T__sim): entry =list(price_sim.simulate().values()) PriceData.append(entry)labels = ['p_t', 'b_t', 'b_t_val']df = pd.DataFrame.from_records(data=PriceData, columns=labels); df[:10]
p_t
b_t
b_t_val
0
0.3365
Up
1
1
3.1084
Neutral
0
2
2.0958
Neutral
0
3
1.1369
Neutral
0
4
0.7226
Up
1
5
-1.1433
Up
1
6
3.9397
Neutral
0
7
-0.4858
Down
-1
8
2.1811
Down
-1
9
0.4218
Down
-1
price_sim.plot_output(df)
del price_sim
3 DATA PREPARATION
We will use the data provided by the simulator directly. There is no need to perform additional data preparation.
4 MODELING
4.1 Narrative
We are holding an asset and we are looking for the best time to sell it. For simplicity of thought we will consider this asset to be a single share in a company. In later POCs we will allow for multiple shares in multiple companies with the ability to buy/hold/sell a decided number of shares at each step. We assume that our decisions in the current project do not affect the price of the share. The price varies according to a stochastic process (as coded in the above price simulator).
4.2 Core Elements
This section attempts to answer three important questions: - What metrics are we going to track? - What decisions do we intend to make? - What are the sources of uncertainty?
For this problem, the only metric we are interested in is the amount of profit we make after each decision window. A single type of decision needs to be made at the start of each window - whether we want to hold on to the asset, or to sell it at the current price. The only source of uncertainty is the price of the asset (share).
4.3 Mathematical Model | SUS Design
A Python class is used to implement the model for the SUS (System-Under-Steer):
class Model():
def __init__(self, S_0_info):
...
...
4.3.1 State variables
The state variables represent what we need to know.
\(R_t\)
the number of shares at time \(t\)
will be either 0 or 1 in this project
measured in units
\(p_t\)
price of the share at time \(t\)
\(\bar{p}_{t}\)
smoothed estimate of the price of the share at time \(t\)
smoothing happens according to \[\bar{p}_t = (1 - \alpha) \bar{p}_{t-1} + \alpha p_t\]
The state is:
\(S_t = (R_t, p_t, \bar{p}_{t})\)
The state variables are represented by the following variables in the AssetSellingModel class:
The exogenous information variables represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(x_t\).
When we assume that the price in each time period is revealed, without any model to predict the price based on past prices, we have, using approach 1:
\[
p_{t+1} = W_{t+1}
\]
Alternatively, when we assume that we observe the change in price \(\hat{p}_{t+1}=p_{t+1}-p_{t}\), we have, using approach 2:
The transition function describes how the state variables evolve over time. Because we currently have three state variables in the state, \(S_t=(R_t,p_t,\bar{p}_t)\), we have the equations:
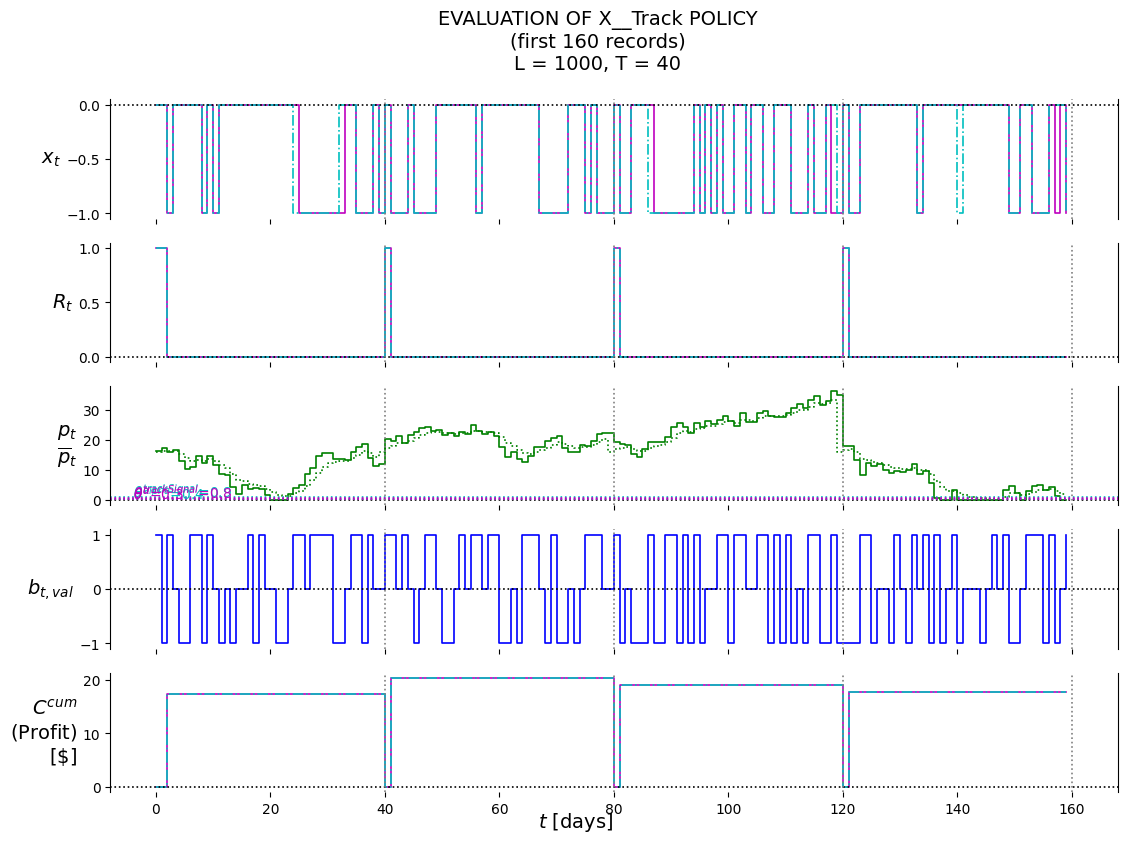
class AssetSellingModel():def__init__(self, S_0_info):self.S_0_info = S_0_infoself.State = namedtuple('State', SNAMES) #. 'class'self.S_t =self.build_state(S_0_info) #. 'instance'self.Decision = namedtuple('Decision', xNAMES) #. 'class'self.Ccum =0.0#. cumulative rewarddef build_state(self, info):returnself.State(*[info[sn] for sn in SNAMES])def build_decision(self, info):returnself.Decision(*[info[xn] for xn in xNAMES])# this function gives the exogenous information that is dependent on a# random process (in the case of the asset selling model, it is the# change in price)def W_fn(self): W_tt1 = SIM.simulate()return W_tt1def S__M_fn(self, S_t, x_t, W_tt1, theta, piName):# R_t R_tt1 =max(0, S_t.R_t + x_t.x_t)# p_t p_t = S_t.p_t p_tt1 =max(0, p_t + W_tt1['p_t']) #W_tt1['p_t'] has CHANGE in price# pbar_tif piName=='X__Track': theta__alpha = theta[0] pbar_t_1 = S_t.pbar_t pbar_t = (1- theta__alpha)*pbar_t_1 + theta__alpha*p_t #SDAM-eq2.15, RLSO-12.2.4else: pbar_t =0 S_tt1 =self.build_state({'R_t': R_tt1,'p_t': p_tt1,'pbar_t': pbar_t, })return S_tt1def C_fn(self, S_t, x_t, W_tt1): C_t =-S_t.p_t*x_t.x_t if S_t.R_t >0else0#x_t = -1 for sellreturn C_tdef step(self, x_t, theta, piName): W_tt1 =self.W_fn() C =self.C_fn(self.S_t, x_t, W_tt1)self.Ccum += Cself.S_t =self.S__M_fn(self.S_t, x_t, W_tt1, theta, piName)return (self.S_t, self.Ccum, x_t, W_tt1['b_t_val']) #. for plotting
4.4 Uncertainty Model
We will simulate the share price \(p_{t+1} = p_t + \hat{p}_{t+1} = p_t + W_{t+1}\) as described in section 2.
4.5 Policy Design
There are two main meta-classes of policy design. Each of these has two subclasses: - Policy Search - Policy Function Approximations (PFAs) - Cost Function Approximations (CFAs) - Lookahead - Value Function Approximations (VFAs) - Direct Lookaheads (DLAs)
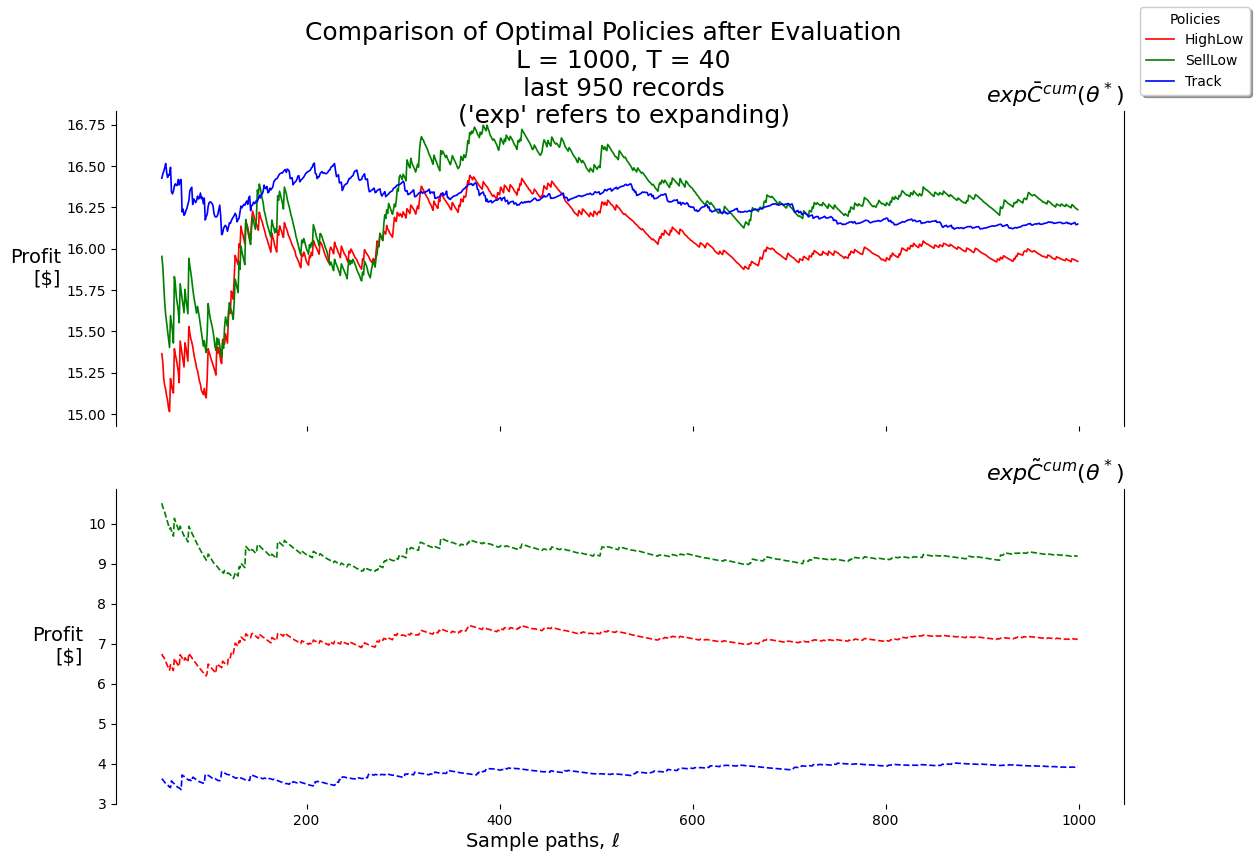
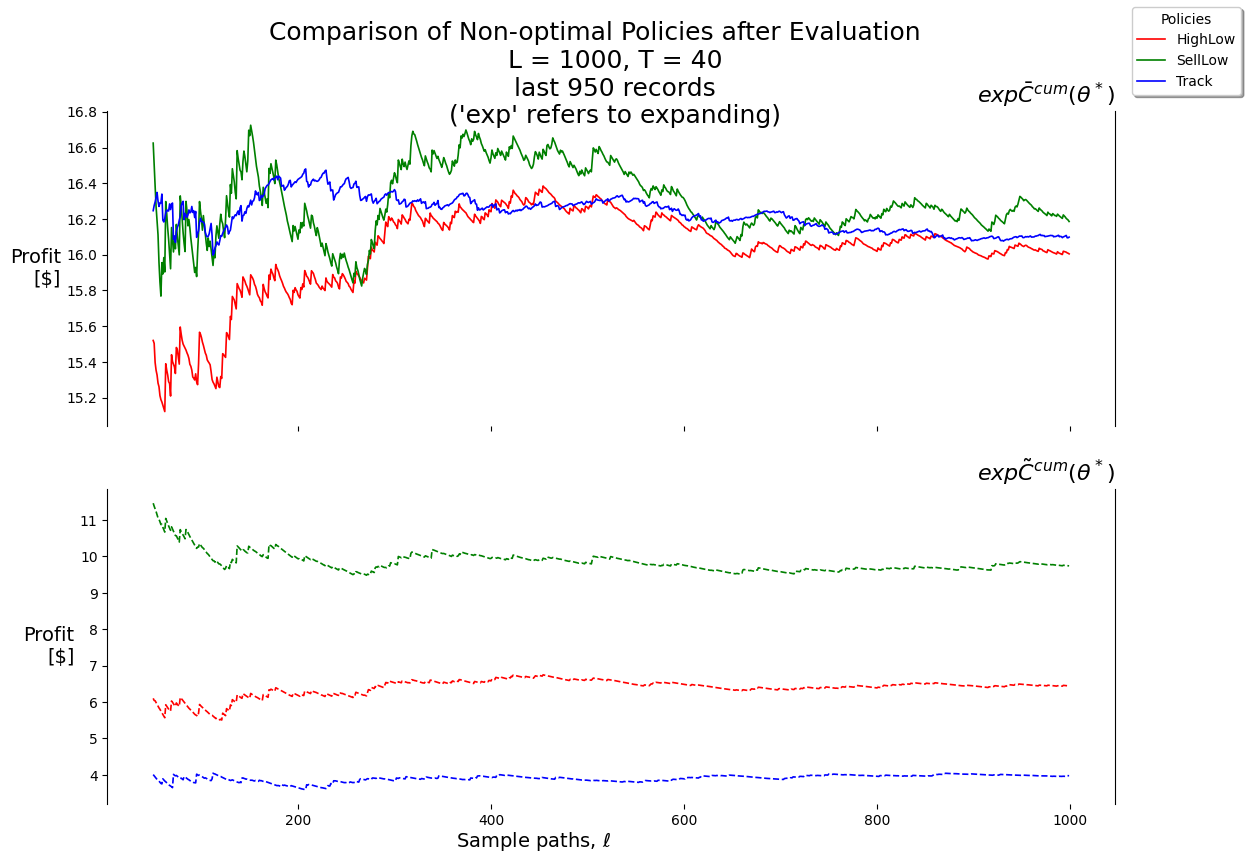
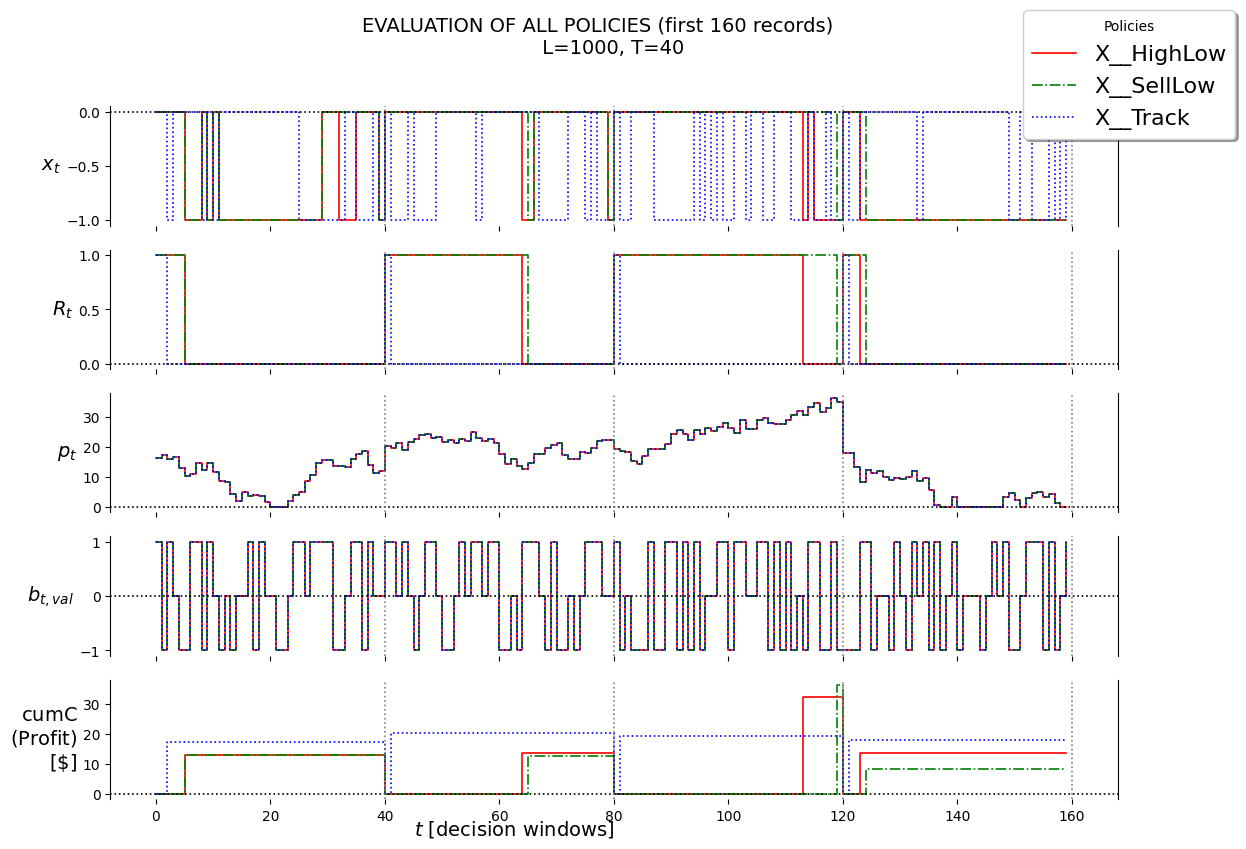
In this project we will make use of 3 policies, all from the PFA class:
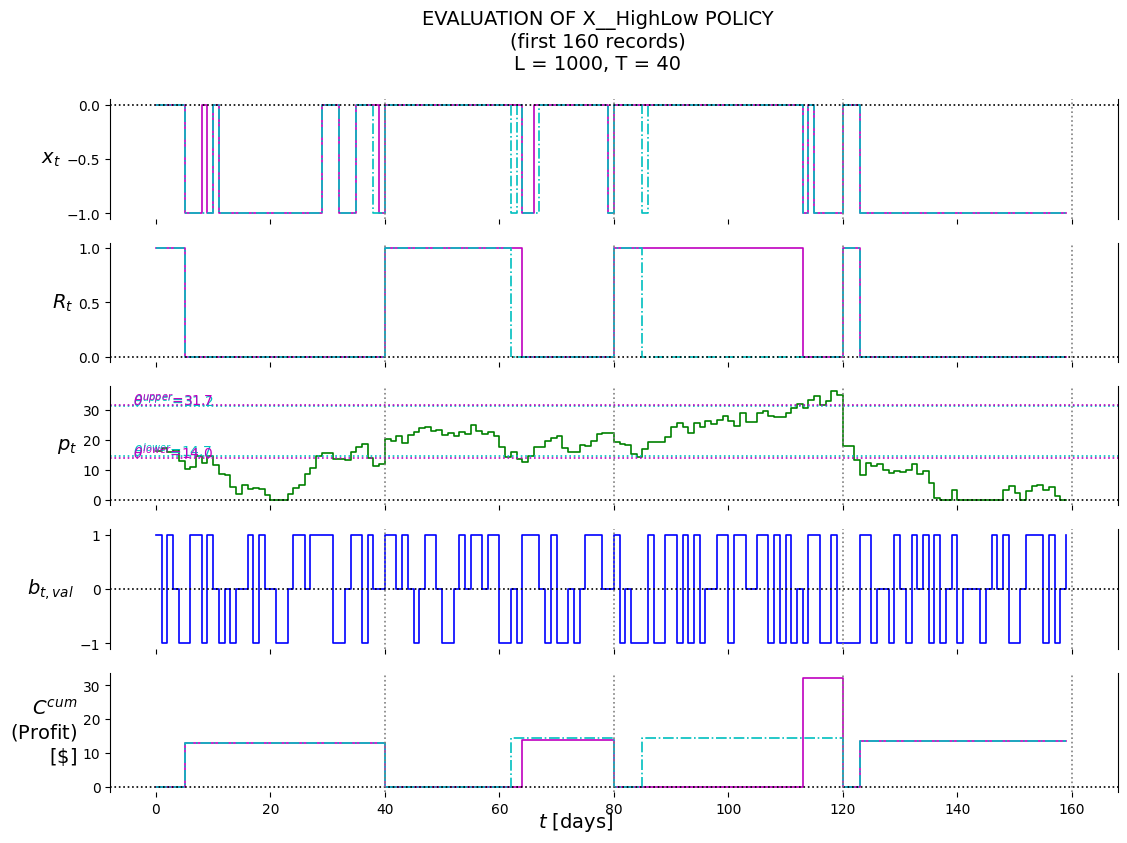
X__HighLow
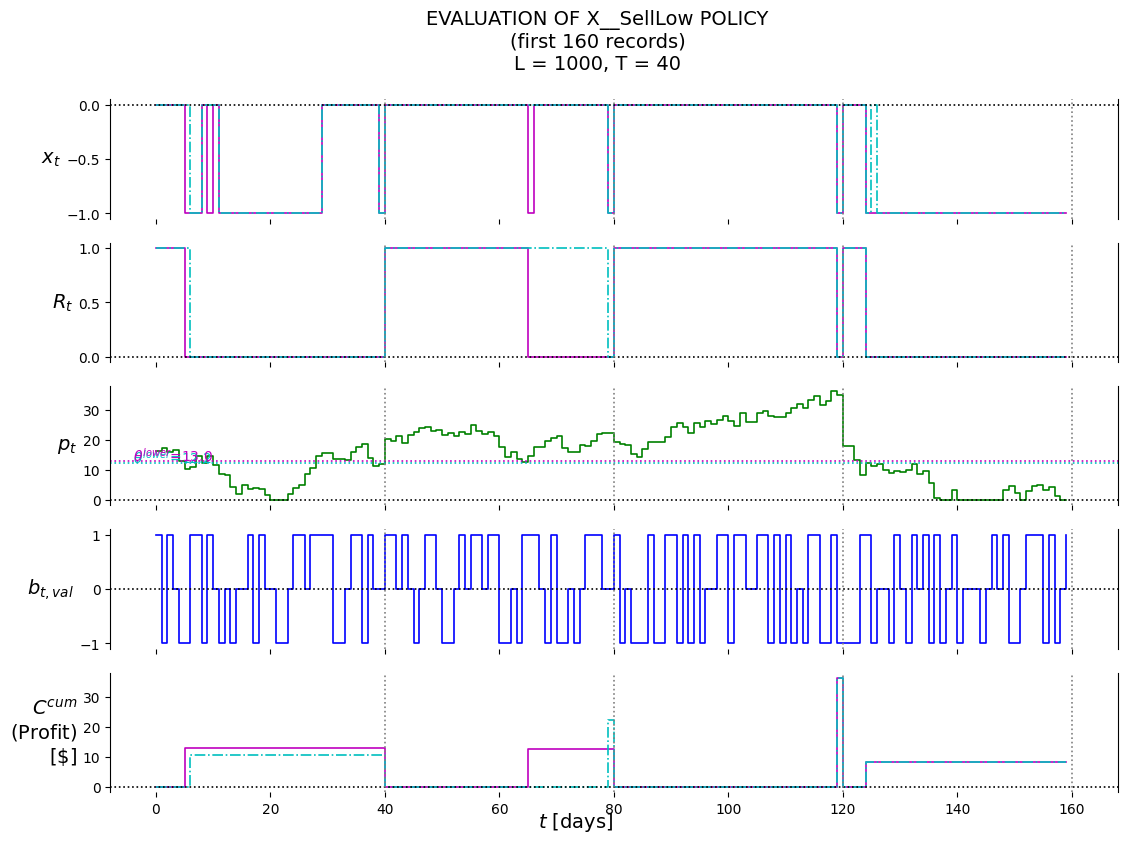
X__SellLow
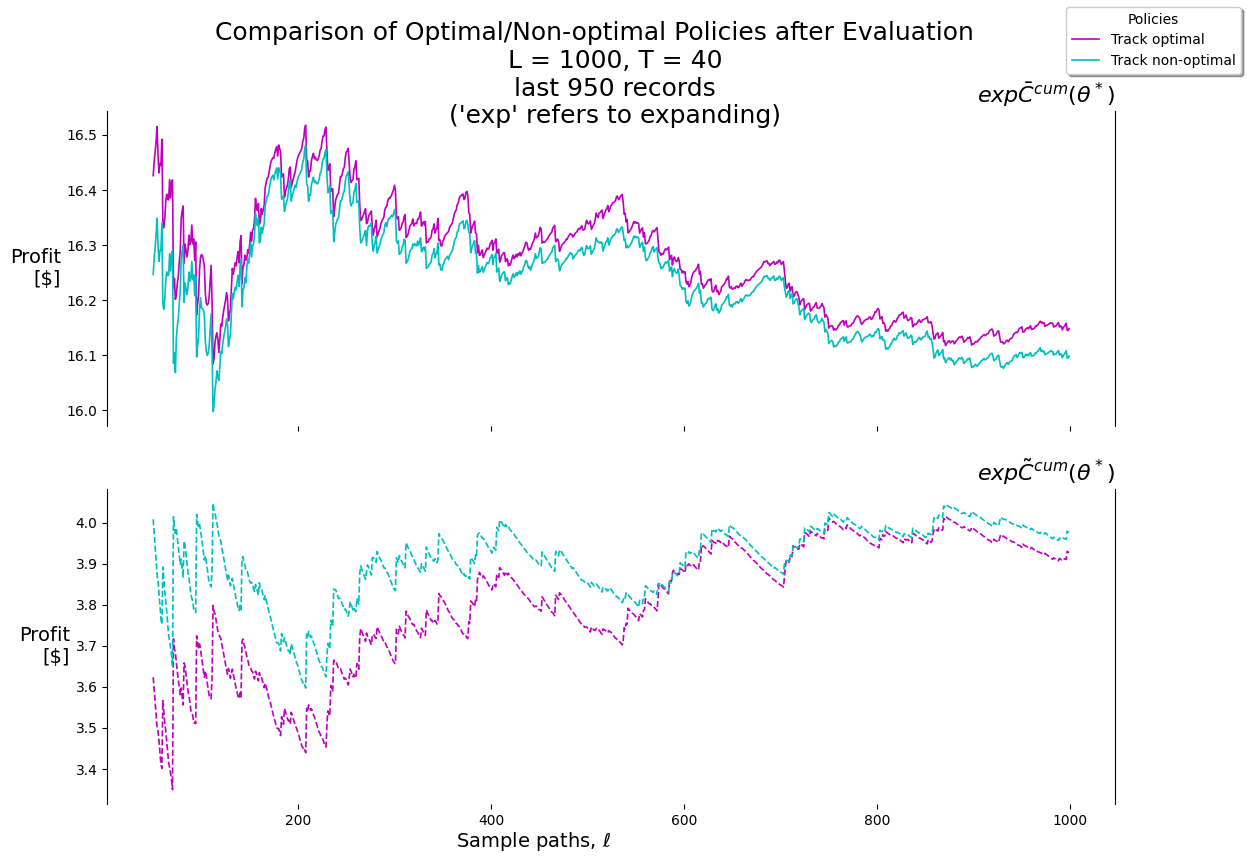
X__Track
where
\[
X^{HighLow}(S_t|\theta^{HighLow}) =
\begin{cases}
-1 & \text{if } p_t < \theta^{low} \text{ or } p_t > \theta^{high} \\
-1 & \text{if } t = T \text{ and } R_t = 1 \\
0 & \text{otherwise }
\end{cases}
\]
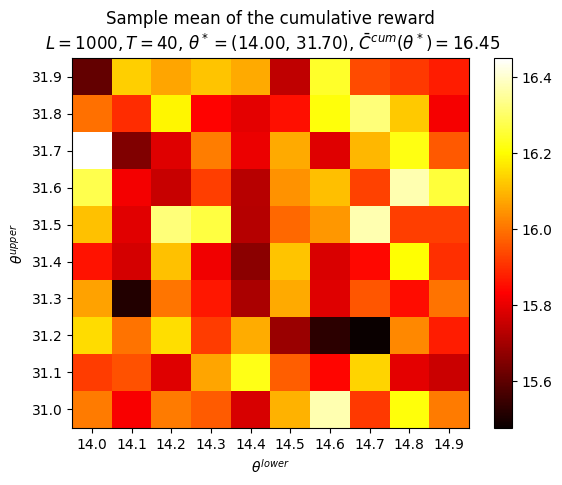
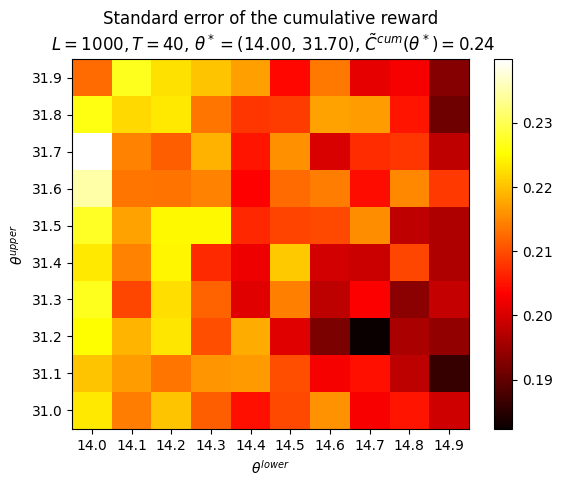
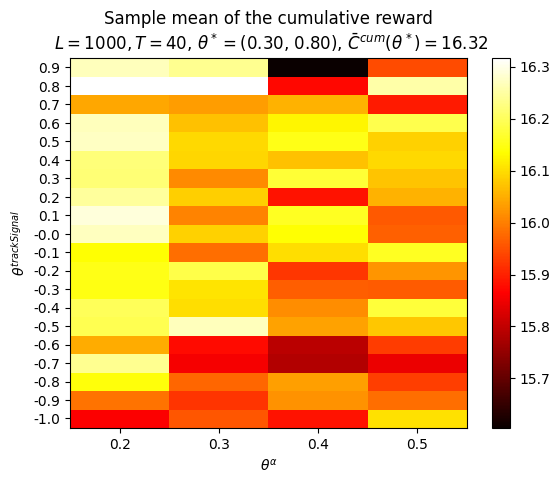
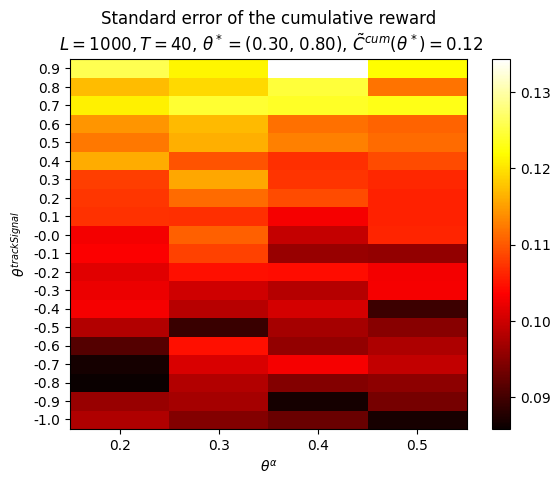
P.plot_Fhat_map( FhatI_theta_I=Cbarcum_HighLow, thetasX=thetasLo, thetasY=thetasHi, labelX=r'$\theta^{lower}$', labelY=r'$\theta^{upper}$', title="Sample mean of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_HighLow[0]:.2f}, {best_theta_HighLow[1]:.2f}), "+\r"$\bar{C}^{cum}(\theta^*) =$"+f"{best_Cbarcum_HighLow:.2f}",)print()P.plot_Fhat_map( FhatI_theta_I=Ctilcum_HighLow, thetasX=thetasLo, thetasY=thetasHi, labelX=r'$\theta^{lower}$', labelY=r'$\theta^{upper}$', title="Standard error of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_HighLow[0]:.2f}, {best_theta_HighLow[1]:.2f}), "+\r"$\tilde{C}^{cum}(\theta^*) =$"+f"{best_Ctilcum_HighLow:.2f}",);
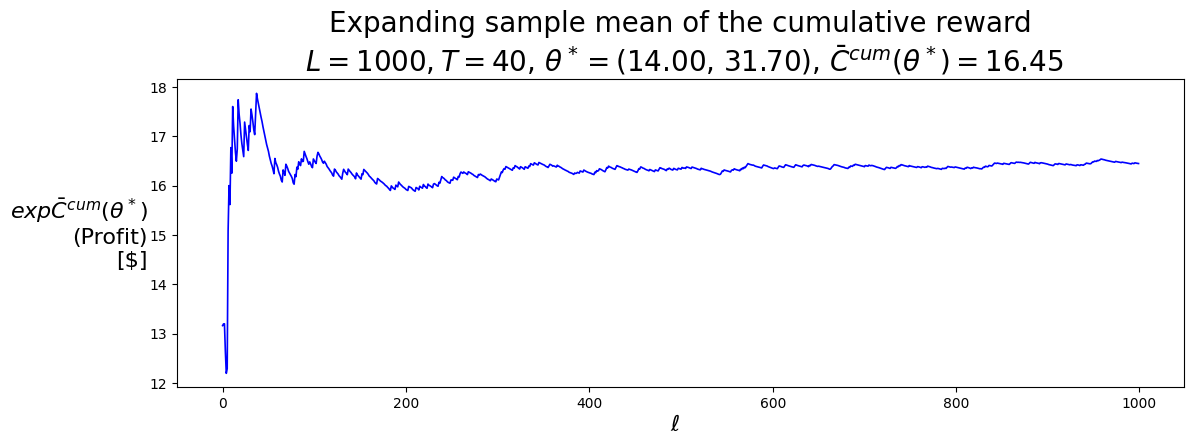
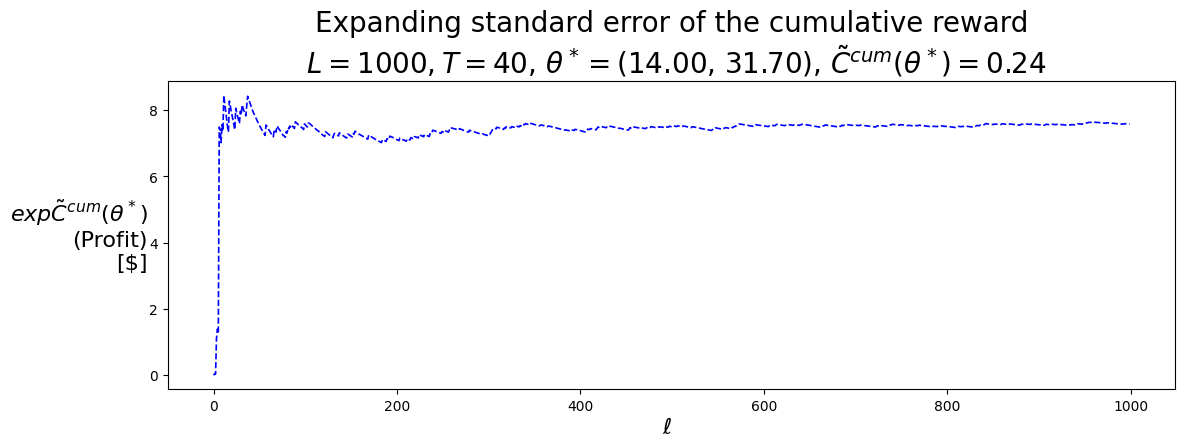
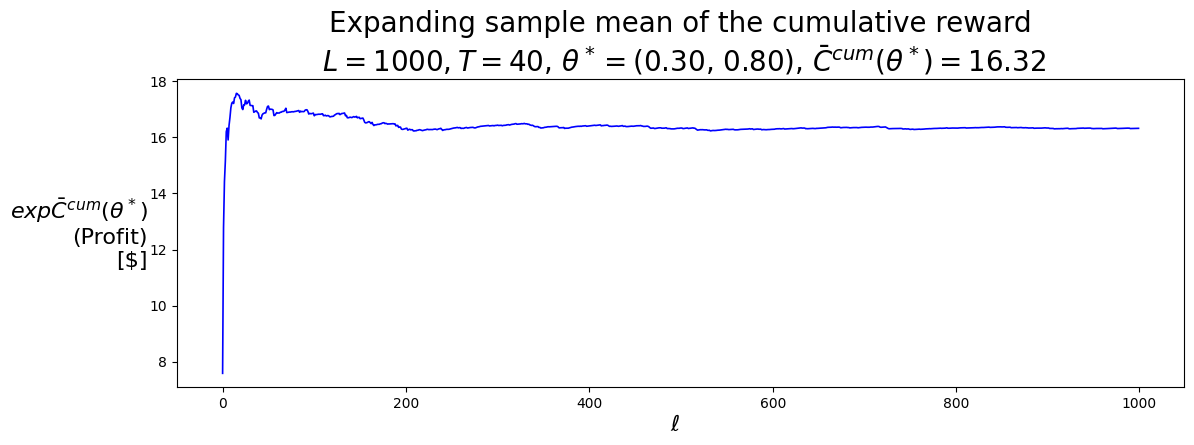
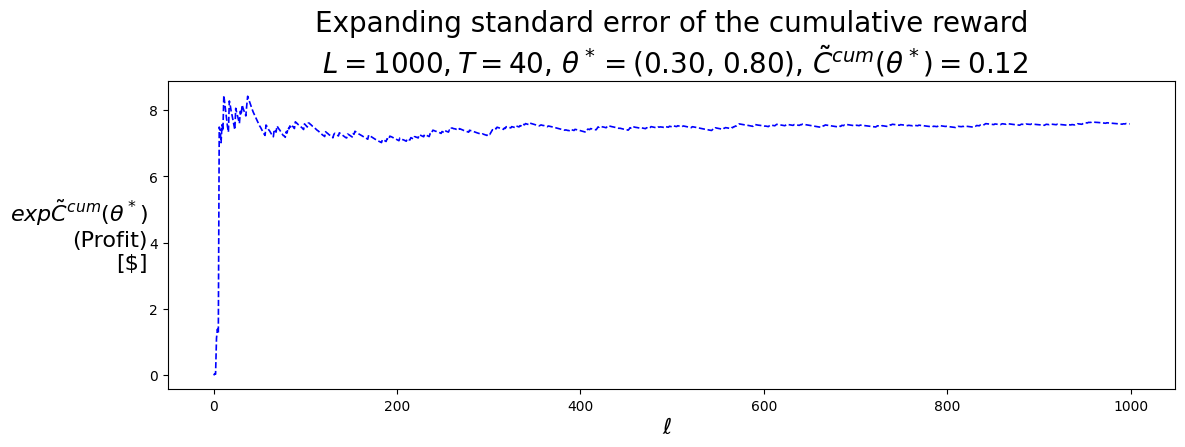
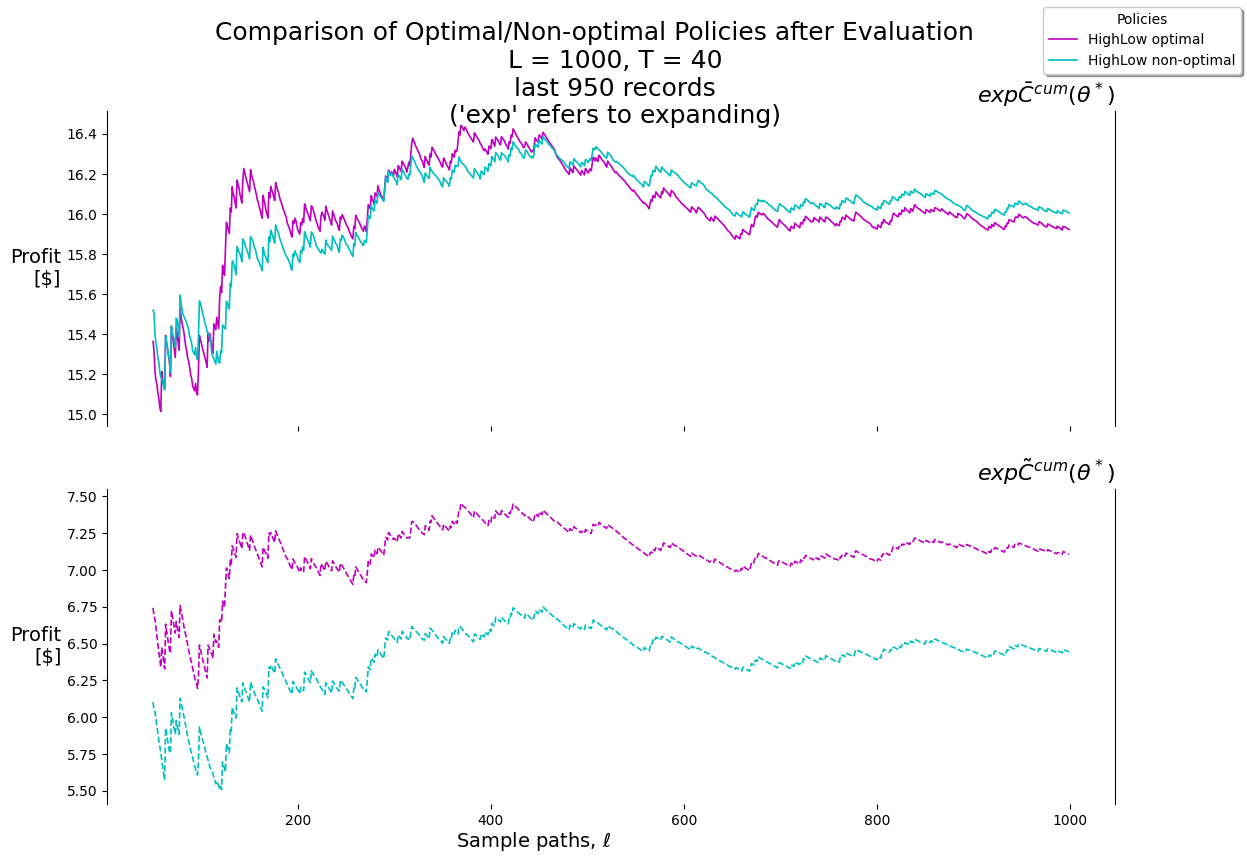
P.plot_expFhat_chart( thetaStar_expCbarcum_HighLow,r'$\ell$',r"$exp\bar{C}^{cum}(\theta^*)$"+"\n(Profit)\n[$]","Expanding sample mean of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_HighLow[0]:.2f}, {best_theta_HighLow[1]:.2f}), "+\r"$\bar{C}^{cum}(\theta^*) =$"+f"{best_Cbarcum_HighLow:.2f}",'b-')print()P.plot_expFhat_chart( thetaStar_expCtilcum_HighLow,r'$\ell$',r"$exp\tilde{C}^{cum}(\theta^*)$"+"\n(Profit)\n[$]","Expanding standard error of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_HighLow[0]:.2f}, {best_theta_HighLow[1]:.2f}), "+\r"$\tilde{C}^{cum}(\theta^*) =$"+f"{best_Ctilcum_HighLow:.2f}",'b--');
f'{len(record_HighLow):,}', L, T
('4,000,000', 1000, 40)
best_theta_HighLow
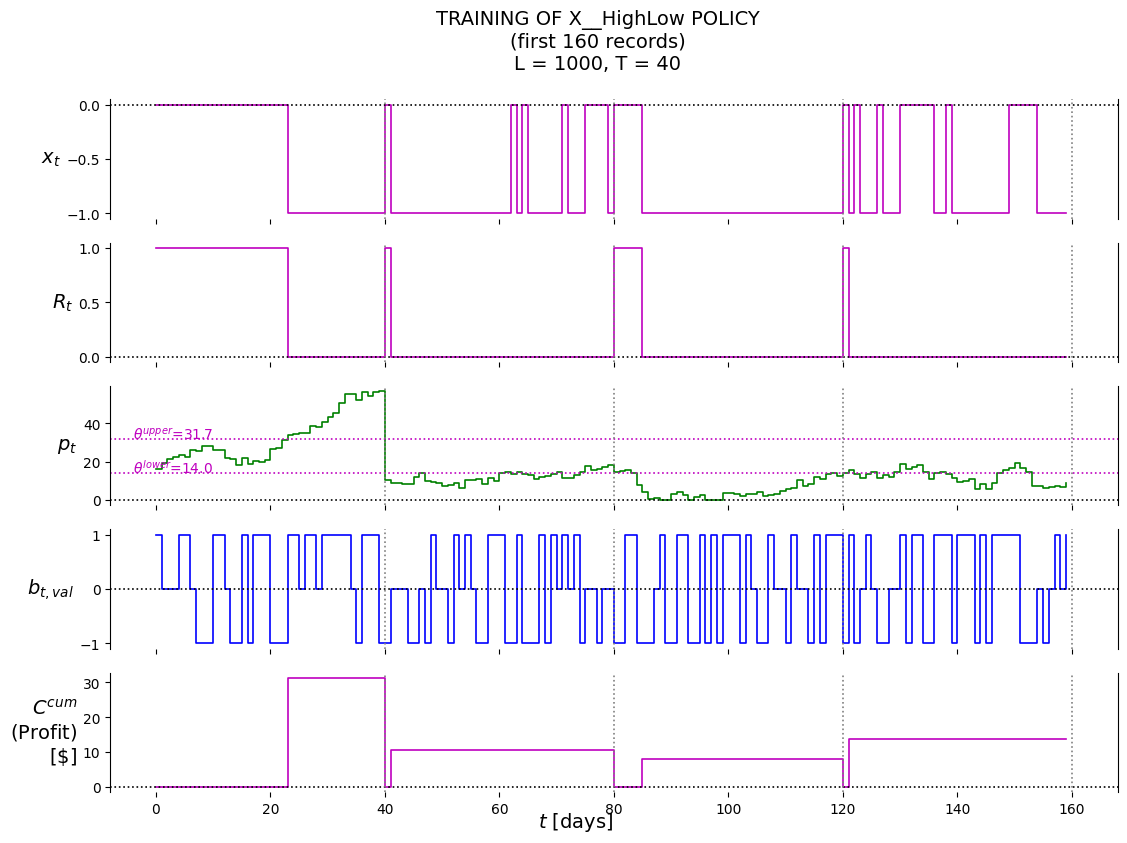
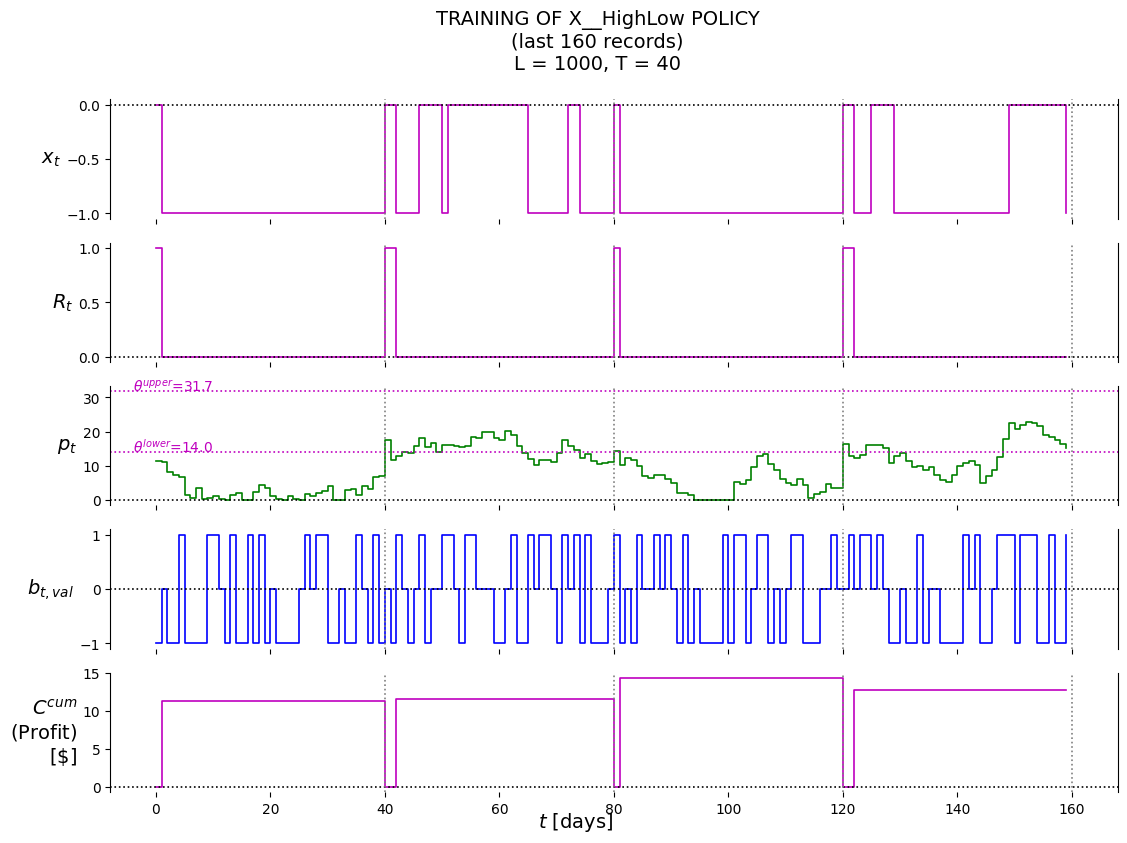
(14.0, 31.70000000000001)
P.plot_train( df=df_first_n, df_non=None, pars=defaultdict(str, {'policy': 'X__HighLow','lower': best_theta_HighLow[0],'upper': best_theta_HighLow[1],'suptitle': f'TRAINING OF X__HighLow POLICY'+'\n'+f'(first {first_n_t} records)'+'\n'+\f'L = {L}, T = {T}', }),)
P.plot_train( df=df_last_n, df_non=None, pars=defaultdict(str, {'policy': 'X__HighLow','lower': best_theta_HighLow[0],'upper': best_theta_HighLow[1],'suptitle': f'TRAINING OF X__HighLow POLICY'+'\n'+f'(last {last_n_t} records)'+'\n'+\f'L = {L}, T = {T}', }),)
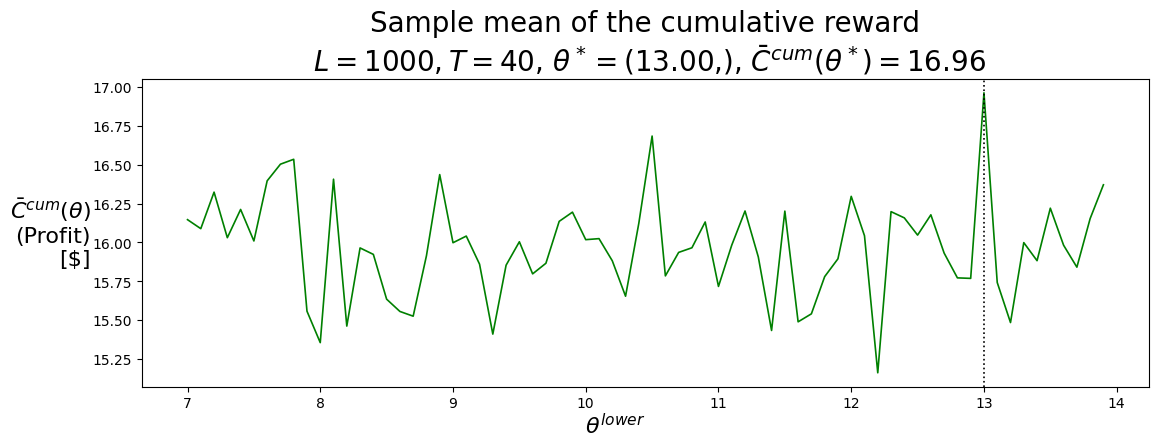
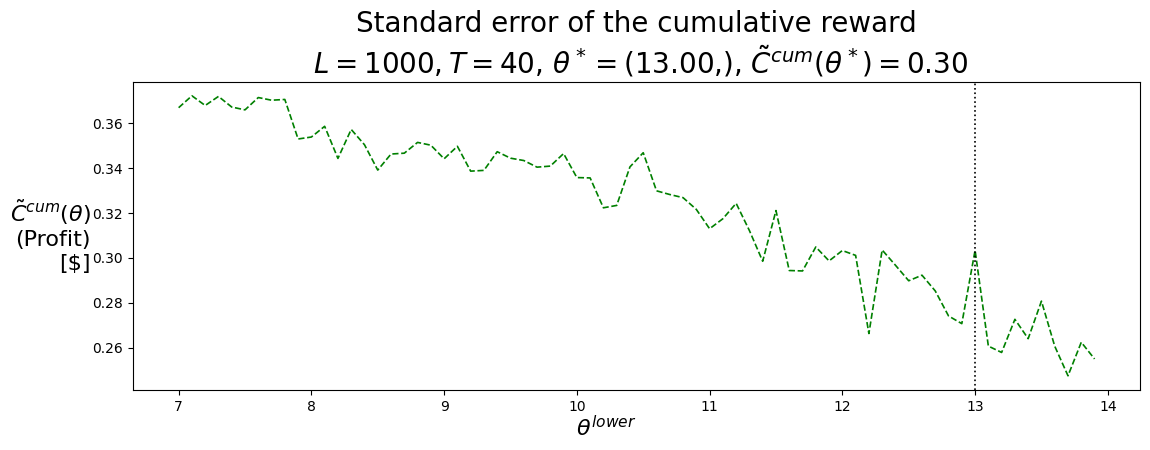
P.plot_Fhat_chart( Cbarcum_SellLow, thetasLo,r'$\theta^{lower}$',r"$\bar{C}^{cum}(\theta)$"+"\n(Profit)\n[$]","Sample mean of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_SellLow[0]:.2f},), "+\r"$\bar{C}^{cum}(\theta^*) =$"+f"{best_Cbarcum_SellLow:.2f}",'g-', best_theta_SellLow,)print()P.plot_Fhat_chart( Ctilcum_SellLow, thetasLo,r'$\theta^{lower}$',r"$\tilde{C}^{cum}(\theta)$"+"\n(Profit)\n[$]","Standard error of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_SellLow[0]:.2f},), "+\r"$\tilde{C}^{cum}(\theta^*) =$"+f"{best_Ctilcum_SellLow:.2f}",'g--', best_theta_SellLow,);
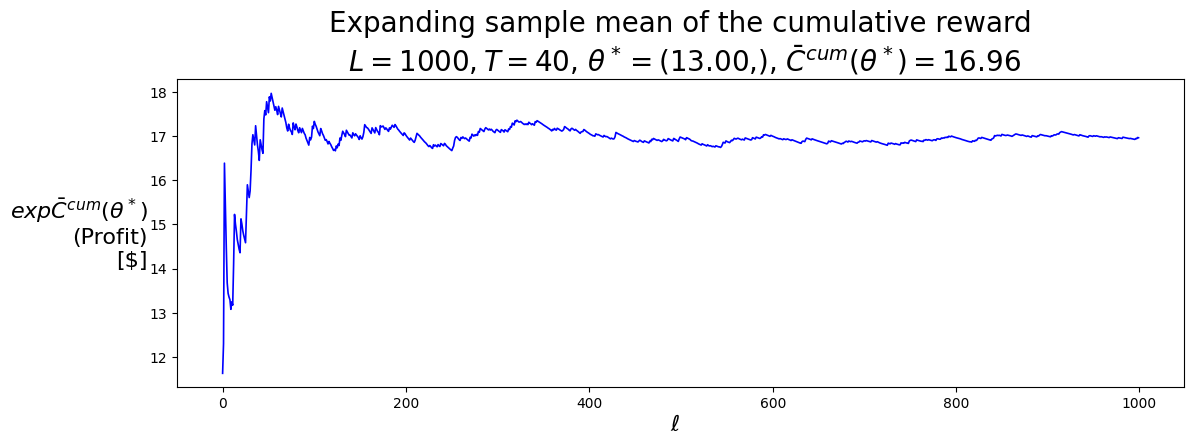
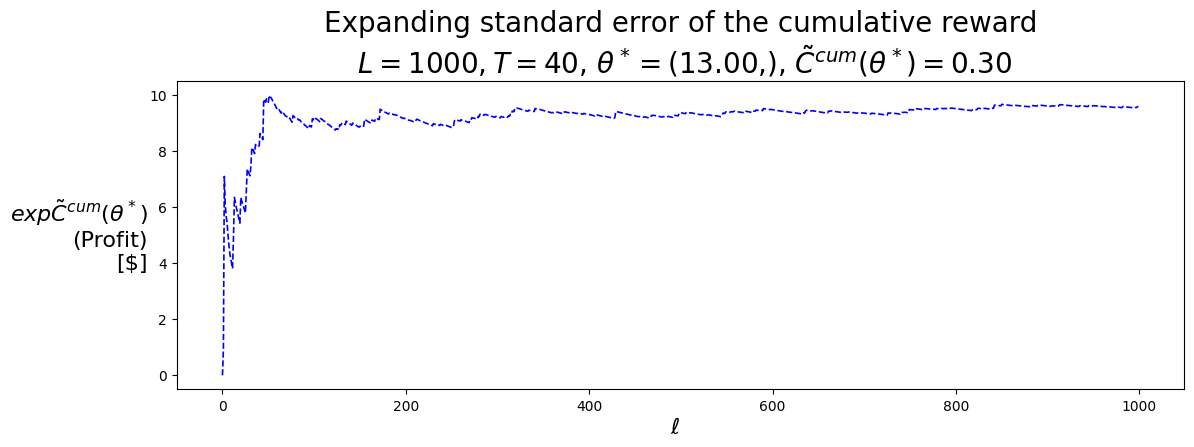
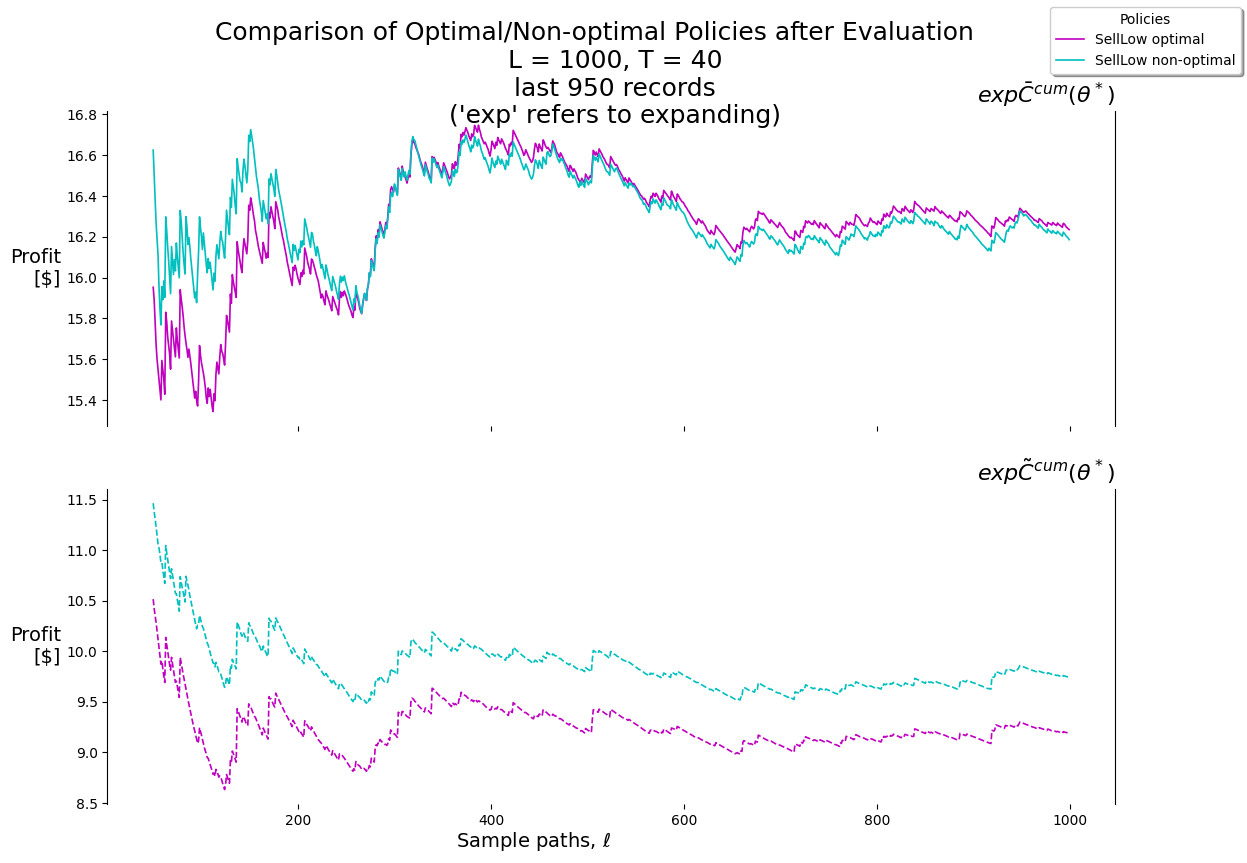
P.plot_expFhat_chart( thetaStar_expCbarcum_SellLow,r'$\ell$',r"$exp\bar{C}^{cum}(\theta^*)$"+"\n(Profit)\n[$]","Expanding sample mean of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_SellLow[0]:.2f},), "+\r"$\bar{C}^{cum}(\theta^*) =$"+f"{best_Cbarcum_SellLow:.2f}",'b-')print()P.plot_expFhat_chart( thetaStar_expCtilcum_SellLow,r'$\ell$',r"$exp\tilde{C}^{cum}(\theta^*)$"+"\n(Profit)\n[$]","Expanding standard error of the cumulative reward"+f"\n $L={L}, T={T}$, "+\r"$\theta^* =$"+f"({best_theta_SellLow[0]:.2f},), "+\r"$\tilde{C}^{cum}(\theta^*) =$"+f"{best_Ctilcum_SellLow:.2f}",'b--');
f'{len(record_SellLow):,}', L, T
('2,800,000', 1000, 40)
best_theta_SellLow
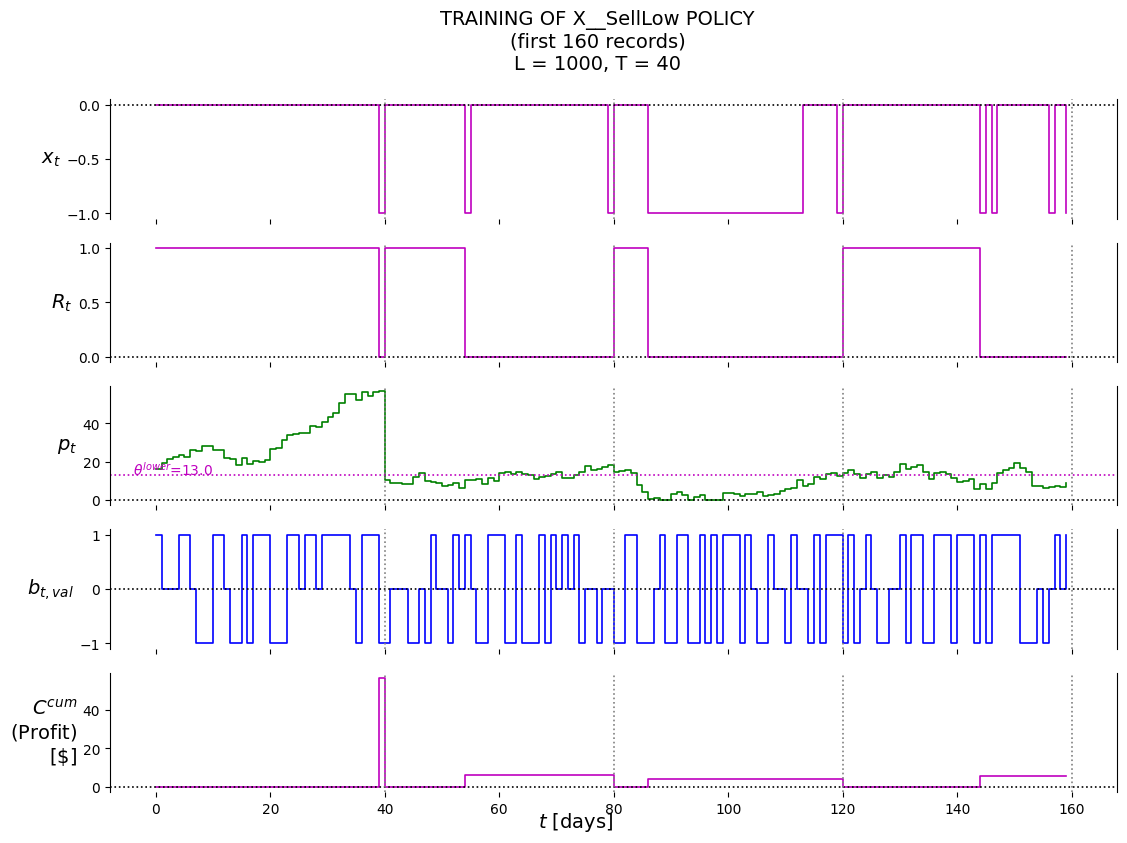
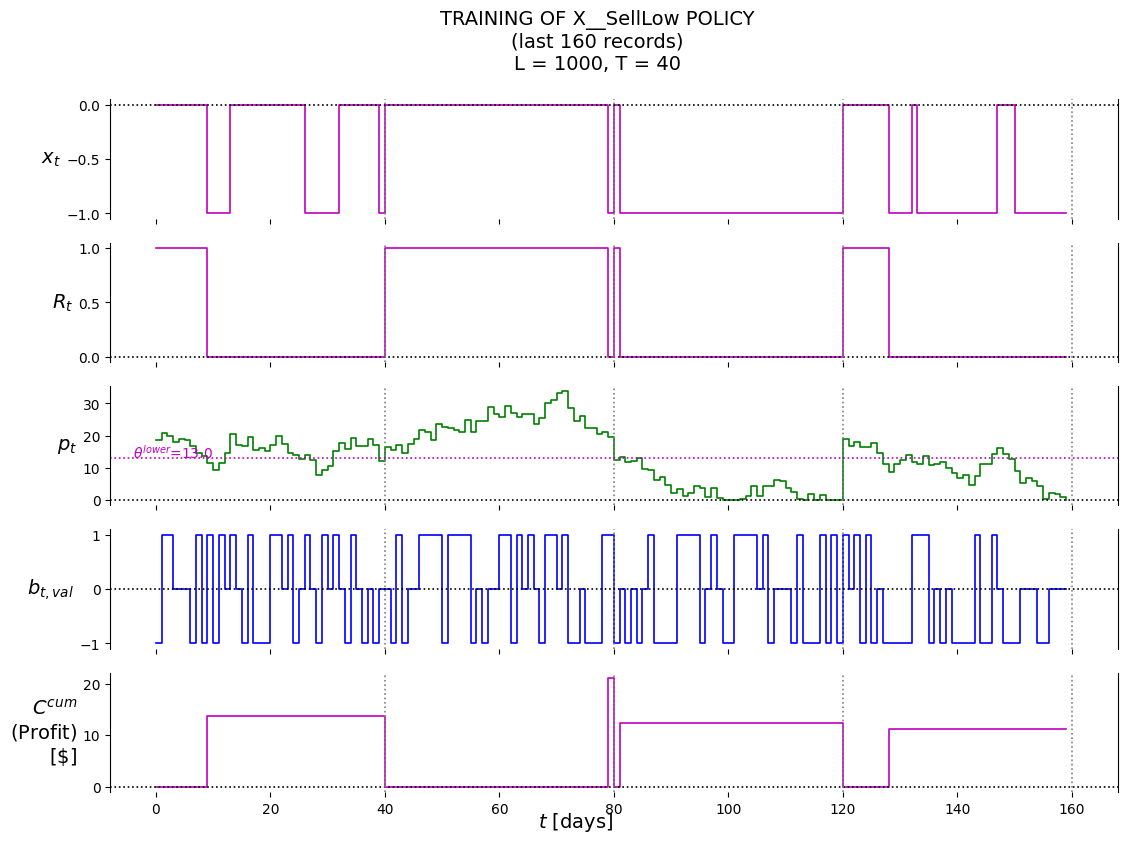
(12.999999999999979,)
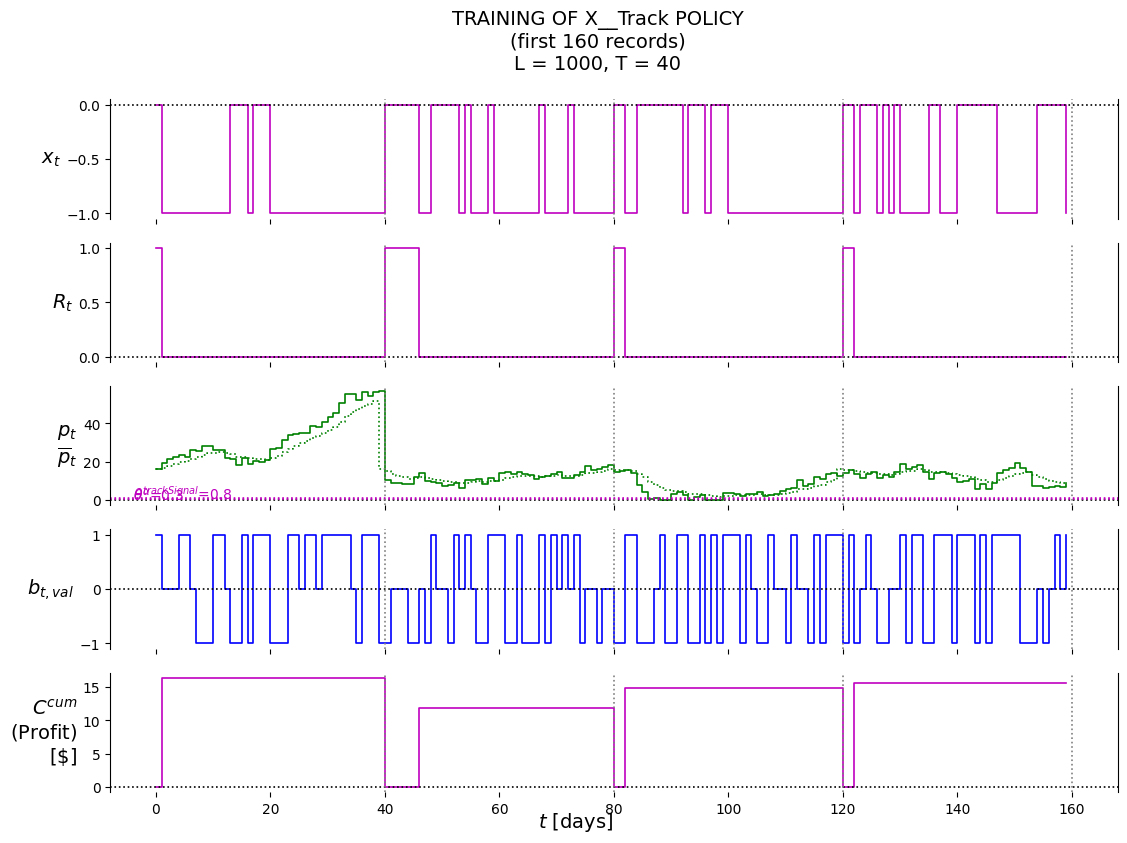
P.plot_train( df=df_first_n, df_non=None, pars=defaultdict(str, {'policy': 'X__SellLow','lower': best_theta_SellLow[0],'suptitle': f'TRAINING OF X__SellLow POLICY'+'\n'+f'(first {first_n_t} records)'+'\n'+\f'L = {L}, T = {T}' }),)
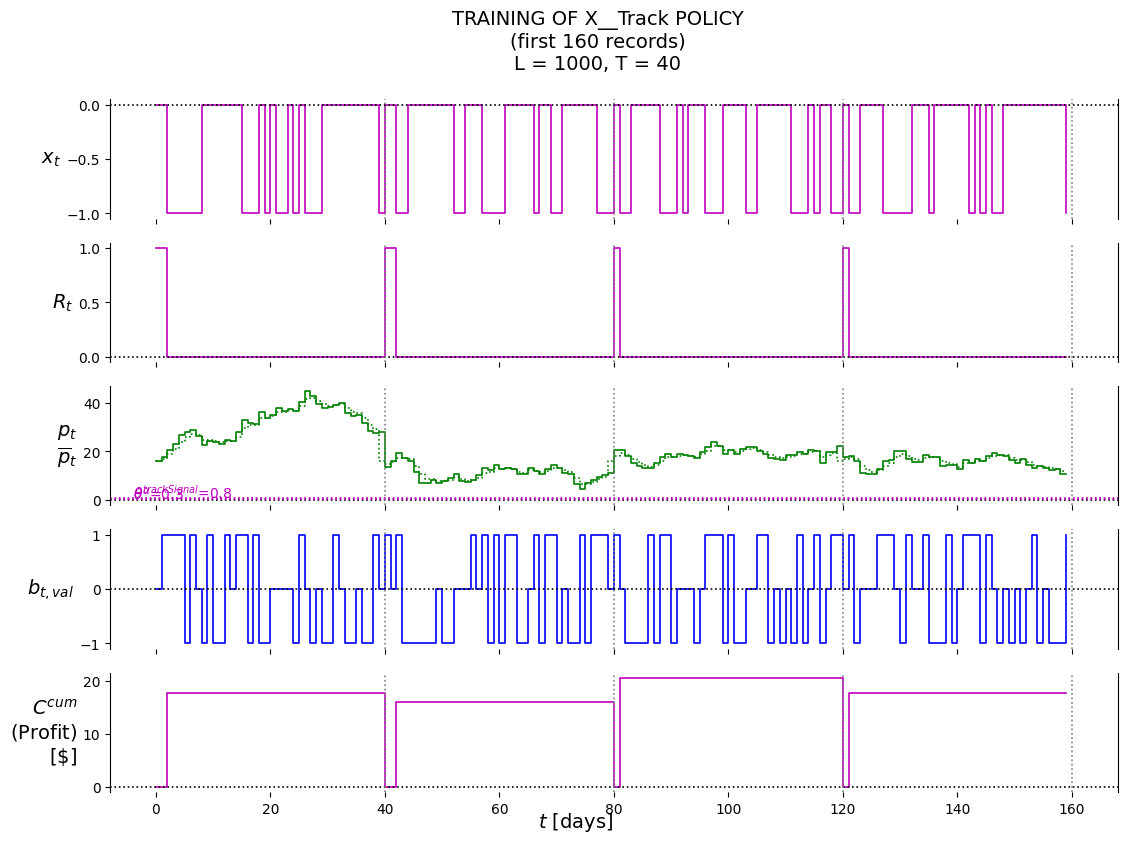
P.plot_train( df=df_last_n, df_non=None, pars=defaultdict(str, {'policy': 'X__SellLow','lower': best_theta_SellLow[0],'suptitle': f'TRAINING OF X__SellLow POLICY'+'\n'+f'(last {last_n_t} records)'+'\n'+\f'L = {L}, T = {T}' }),)