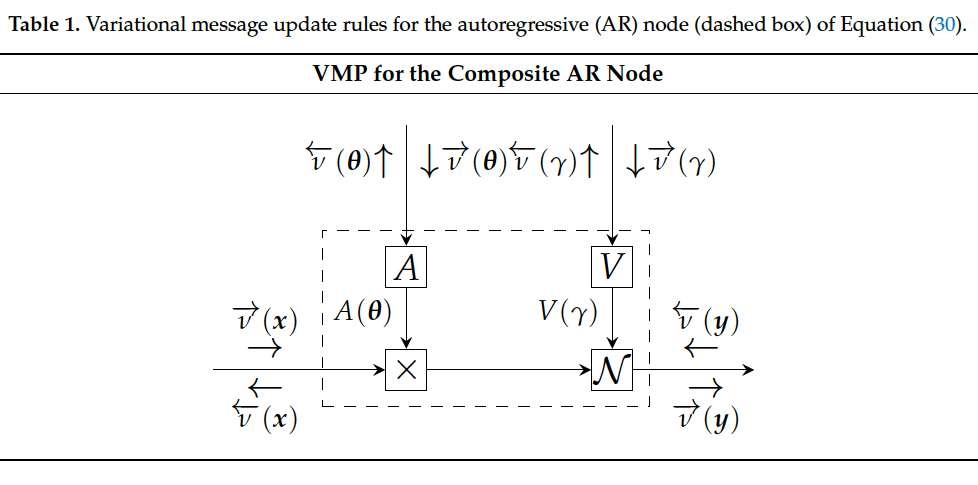
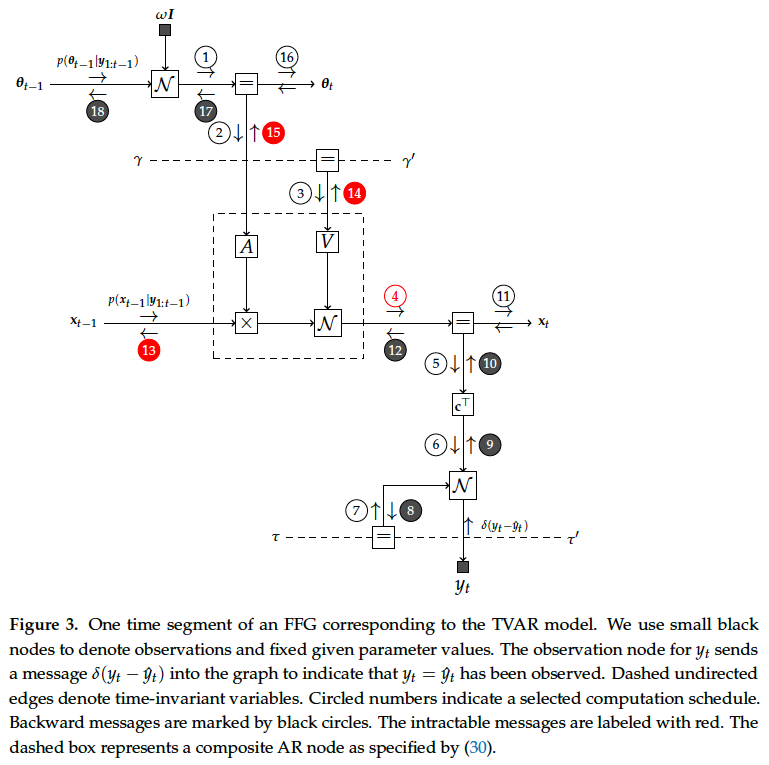
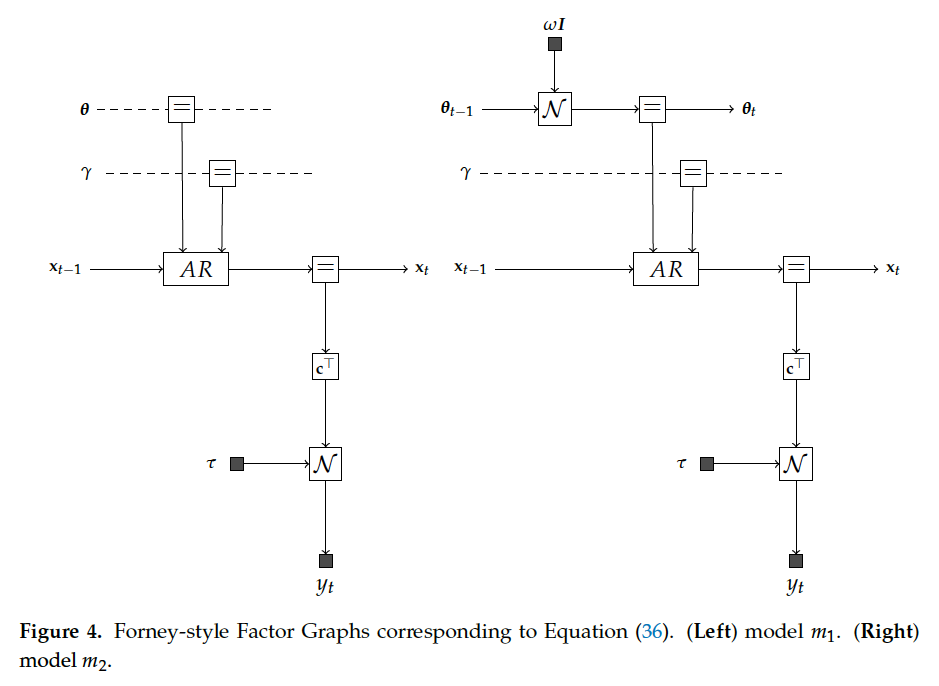
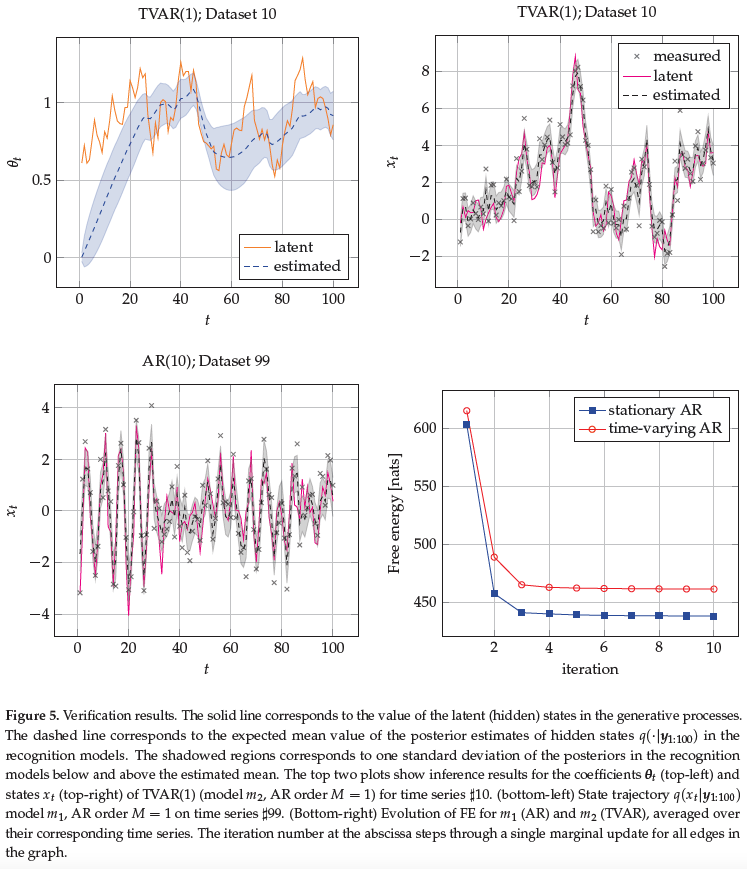
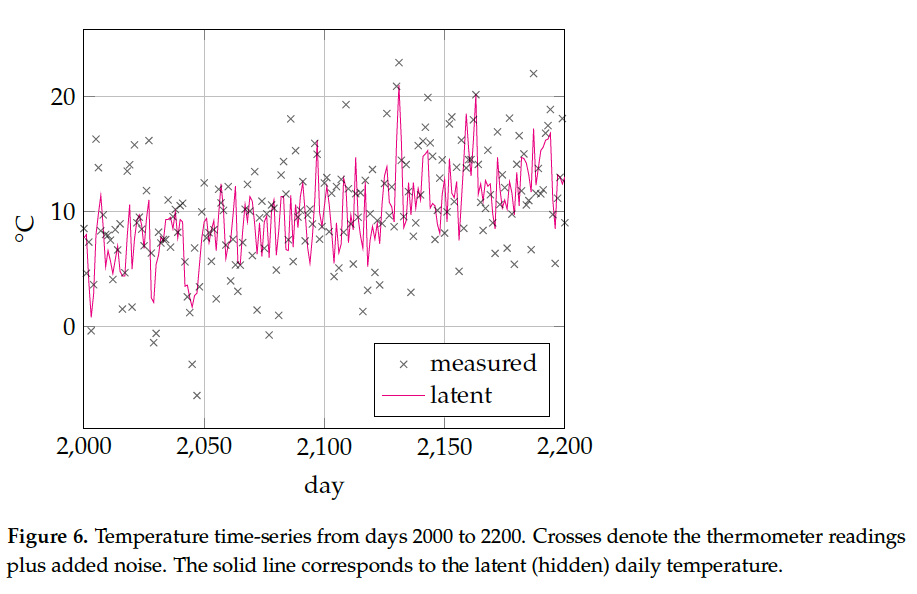
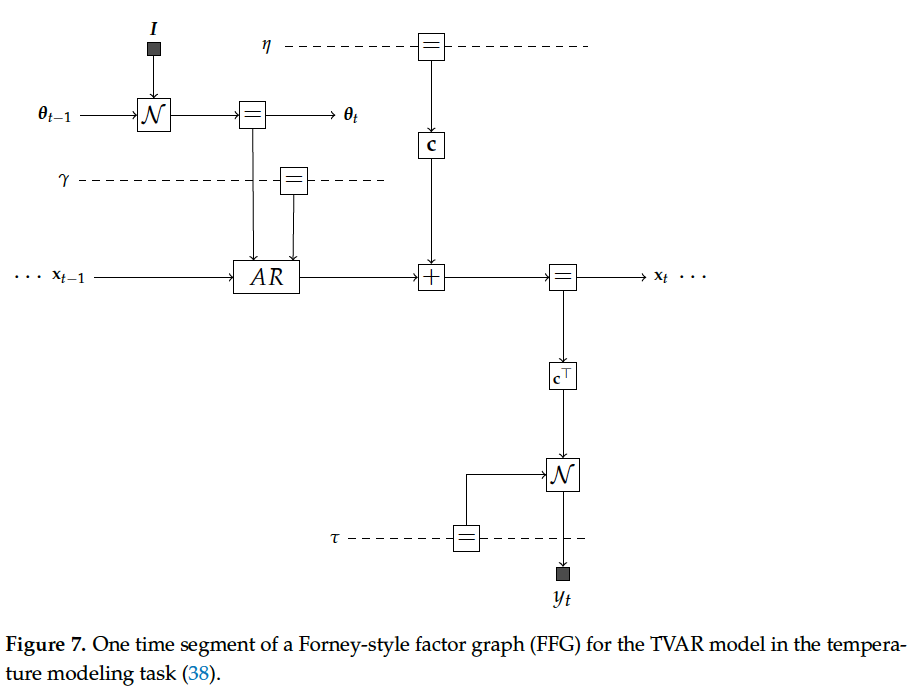
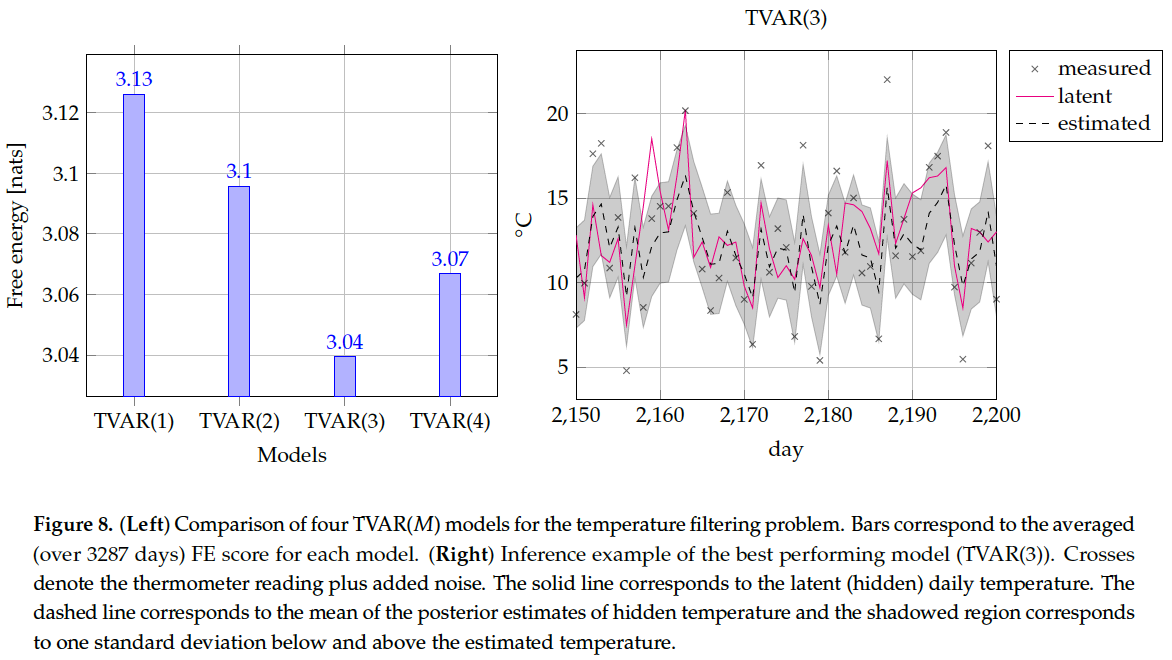
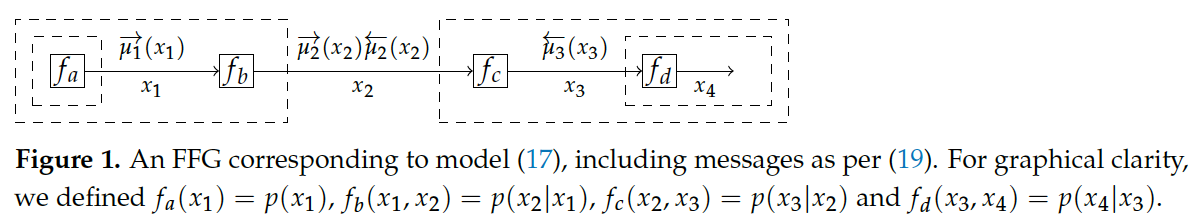In this section, we first discuss some of the - merits of using Bayesian evidence as a model performance criterion. This is followed by an exposition of - how to compute Bayesian evidence and the desired posteriors in the TVAR model.
3.2. Inference as a Prediction-Correction Process
To illustrate the type of calculations that are needed for computing Bayesian model evidence and the posteriors for states and parameters, we now proceed to write out the needed calculations for the TVAR model in a filtering context.
Assume that at the beginning of time step \(t\), we are given the state posteriors \(q(\mathbf{s}_{t-1}\mid x_{1:t-1})\), \(q(\boldsymbol{\theta}_{t-1}\mid x_{1:t-1})\). We will denote the inferred probabilities by \(q(\cdot)\), in contrast to factors from the generative model that are written as \(p(\cdot)\). We start the procedure by setting the state priors for the generative model at step \(t\) to the posteriors of the previous time step
\[
p\left(\mathbf{s}_{t-1} \mid x_{1:t-1}\right):=q\left(\mathbf{s}_{t-1} \mid x_{1:t-1}\right) \tag{6}
\] \[
p\left(\boldsymbol{\theta}_{t-1} \mid x_{1:t-1}\right):=q\left(\boldsymbol{\theta}_{t-1} \mid x_{1:t-1}\right) \tag{7}
\]
Given a new observation \(x_t\), we are now interested in inferring the evidence \(q(x_t \mid x_{t-1})\), and in inferring posteriors \(q(\mathbf{s}_t \mid x_{1:t})\) and \(q(\boldsymbol{\theta}_t \mid x_{1:t})\).
This involves a prediction (forward) pass {{‘generence’}} through the system that leads to the evidence update, followed by a correction (backward) pass {{inference}} that updates the states. We work this out in detail below. For clarity of exposition, in this section we call \(\mathbf{s}_t\) states and \(\boldsymbol\theta_t\) parameters. Starting with the forward pass (from latent variables toward observation) {{‘generence’}}, we first compute a parameter prior predictive:
\[
\underbrace{q\left(\boldsymbol{\theta}_t \mid x_{1:t-1}\right)}_{\substack{\text{parameter} \\ \text{prior predictive}}}
=\int \underbrace{p\left(\boldsymbol{\theta}_t \mid \boldsymbol{\theta}_{t-1}\right)}_{\substack{\text{parameter}\\\text{transition}}} \underbrace{p\left(\boldsymbol{\theta}_{t-1} \mid x_{1:t-1}\right)}_{\substack{\text { parameter } \\
\text { prior }}}
\mathrm{d} \boldsymbol{\theta}_{t-1}. \tag{8}
\]
Then the prior predictive for the state transition becomes:
\[
\underbrace{q\left(\mathbf{s}_t \mid \mathbf{s}_{t-1,} x_{1:t-1}\right)}_{\substack{\text{state transition}\\\text { prior predictive }}}
=\int \underbrace{p\left(\mathbf{s}_t \mid x_{t-1}, \boldsymbol{\theta}_t\right)}_{\text {state transition }} \underbrace{q\left(\boldsymbol{\theta}_t \mid x_{1:t-1}\right)}_{\substack{\text { parameter } \\\text { prior predictive }}}
\mathrm{d} \boldsymbol{\theta}_t. \tag{9}
\]
Note that the state transition prior predictive, due to its dependency on time-varying \(\boldsymbol\theta_t\), is a function of the observed data sequence. The state transition prior predictive can be used together with the state prior to inferring the state prior predictive:
\[
\underbrace{q\left(\mathbf{s}_t \mid x_{1:t-1}\right)}_{\substack{\text { state } \\\text { prior predictive }}}
=\int \underbrace{q\left(\mathbf{s}_t \mid \mathbf{s}_{t-1}, x_{1:t-1}\right)}_{\substack{
\text { state transition } \\
\text { prior predictive }}}
\underbrace{p\left(\mathbf{s}_{t-1} \mid x_{1:t-1}\right)}_{\text {state prior }} \mathrm{d} \mathbf{s}_{t-1}. \tag{10}
\]
The evidence for model \(m\) that is provided by observation \(x_t\) is then given by
\[
\underbrace{q\left(x_t \mid x_{1:t-1}\right)}_{\text {evidence }}=\int \underbrace{p\left(x_t \mid \mathbf{s}_t\right)}_{\substack{\text { state } \\\text { likelihood }}}
\underbrace{q\left(\mathbf{s}_t \mid x_{1:t-1}\right)}_{\substack{\text { state prior } \\\text { predictive }}}
\mathrm{d} \mathbf{s}_t. \tag{11}
\]
When \(x_t\) has not yet been observed, \(q(x_t \mid x_{1:t-1})\) is a prediction for \(x_t\). After plugging in the observed value for \(x_t\), the evidence is a scalar that scores how well the model performed in predicting \(x_t\). As discussed in (5), the results \(q(x_t \mid x_{1:t-1})\) for \(t = 1, 2, ..., T\) in (11) can be used to score the model performance for a given time series \(x = (x_1, x_2, ..., x_T)\). Note that to update the evidence, we need to integrate over all latent variables \(\boldsymbol{\theta}_{t-1},\boldsymbol{\theta}_{t},\mathbf{s}_{t-1}\) and \(\mathbf{s}_t\) (by (8)–(11)). In principle, this scheme needs to be extended with integration over the parameters \(\omega\), \(\gamma\) and \(\tau\).
Once we have inferred the evidence, we proceed by a backward corrective pass through the model to update the posterior over the latent variables given the new observation \(x_t\). The state posterior can be updated by Bayes rule:
\[
\underbrace{
q\left(\mathbf{s}_t \mid x_{1:t}\right)}_{\text {state posterior }}
=\frac
{
\overbrace{p\left(x_t \mid \mathbf{s}_t\right)}^
{\substack{\text{state}\\ \text{likelihood}}}
\overbrace{q\left(\mathbf{s}_t \mid x_{1:t-1}\right)}^
{\substack{\text{state prior}\\ \text{predictive}}}
}
{
\underbrace{q\left(x_t \mid x_{1:t-1}\right)}_{\text{evidence}}
} \tag{12}
\]
Next, we need to compute a likelihood function for the parameters. Fortunately, we can re-use some intermediate results from the forward pass. The likelihood for the parameters is given by
\[
\underbrace{
q\left(x_t \mid \boldsymbol{\theta}_t, x_{1:t-1}\right)}_{
\substack{\text{parameter}\\\text{likelihood}}}
=\int
\underbrace{p\left(x_t \mid \mathbf{s}_t\right)}_{
\substack{\text { state } \\\text { likelihood }}}
\underbrace{
q\left(\mathbf{s}_t \mid \boldsymbol{\theta}_t, x_{1:t-1}\right)}_{
\substack{\text { state prior } \\ \text { predictive }}}
\mathrm{d} \mathbf{s}_t \tag{13}
\]
The parameter posterior then follows from Bayes rule:
\[
\underbrace{
q\left(\boldsymbol{\theta}_t \mid x_{1:t}\right)}_{\text {parameter posterior }}
=
\frac
{\overbrace{
q\left(x_t \mid \boldsymbol{\theta}_t, x_{1:t-1}\right)}^{\substack{\text{parameter}\\\text{likelihood}}} \overbrace{
q\left(\boldsymbol{\theta}_t \mid x_{1:t-1}\right)}^{\substack{\text{parameter}\\\text{prior predictive}}}
}
{\underbrace{
q\left(x_t \mid x_{1:t-1}\right)}_{\text{evidence}}
} \tag{14}
\]
Equations (11), (12) and (14) contain the solutions to our inference task. Note that the evidence \(q(x_t)|x_{1:t-1}\) is needed to normalize the latent variable posteriors in (12) and (14). Moreover, while we integrate over the states by (11) to compute the evidence, (14) reveals that the evidence can alternatively be computed by integrating over the parameters through
\[
\underbrace{
q\left(x_t \mid x_{1:t-1}\right)}_{
\text {evidence }}
=\int
\underbrace{
q\left(x_t \mid \boldsymbol{\theta}_t, x_{1:t-1}\right)}_{
\substack{\text { parameter } \\\text { likelihood }}}
\underbrace{
q\left(\boldsymbol{\theta}_t \mid x_{1:t-1}\right)}_{\substack{\text { parameter } \\\text { prior predictive }}}
\mathrm{d} \boldsymbol{\theta}_t. \tag{15}
\]
This latter method of evidence computation may be useful if re-using (11) in (14) leads to numerical rounding issues.
Unfortunately, many of Equations (8) through (14) are not analytically tractable for the TVAR model. This happens due to (1) integration over large state spaces, (2) non-conjugate prior-posterior pairing, and (3) the absence of a closed-form solution for the evidence factor.
To overcome this challenge, we will perform inference by a hybrid message passing scheme in a factor graph. In the next section, we give a short review of Forney-Style Factor Graphs (FFG) and Message-Passing (MP) based inference techniques.