In this project the client had a need to investigate the use of the NBA (Next Best Action) technique to optimize marketing effort and to have a better handle on customer journeys.An example project (from Dr. Warren Powell) was used as a starting point to approach this need. Although this example is from the medical industry, the concepts are directly transferrable to the marketing industry.
The overall structure of this project and report follows the traditional CRISP-DM format. However, instead of the CRISP-DM’S “4 Modeling” section, we inserted the “6 step modeling process” of Dr. Warren Powell in section 4 of this document.
The example explored (but also modified in many ways) in this report comes from Dr. Warren Powell (formerly at Princeton). It was chosen as a template to create a POC for the client. It was important to understand this example thoroughly before embarking on creating the POC. Dr Powell’s unified framework shows great promise for unifying the formalisms of at least a dozen different fields. Using his framework enables easier access to thinking patterns in these other fields that might be beneficial and informative to the sequential decision problem at hand. Traditionally, this kind of problem would be approached from the reinforcement learning perspective. However, using Dr. Powell’s wider and more comprehensive perspective almost certainly provides additional value.
The original code for this example can be found here.
In order to make a strong mapping between the code in this notebook and the mathematics in the Powell Unified Framework (PUF), we follow the following convention for naming Python identifier names:
Superscripts
variable names have a double underscore to indicate a superscript
\(X^{\pi}\): has code X__pi, is read X pi
Subscripts
variable names have a single underscore to indicate a subscript
\(S_t\): has code S_t, is read ‘S at t’
\(M^{Spend}_t\) has code M__Spend_t which is read: “MSpend at t”
Arguments
collection variable names may have argument information added
\(X^{\pi}(S_t)\): has code X__piIS_tI, is read ‘X pi in S at t’
the surrounding I’s are used to imitate the parentheses around the argument
Next time/iteration
variable names that indicate one step in the future are quite common
\(R_{t+1}\): has code R_tt1, is read ‘R at t+1’
\(R^{n+1}\): has code R__nt1, is read ‘R at n+1’
Rewards
State-independent terminal reward and cumulative reward
\(F\): has code F for terminal reward
\(\sum_{n}F\): has code cumF for cumulative reward
State-dependent terminal reward and cumulative reward
\(C\): has code C for terminal reward
\(\sum_{t}C\): has code cumC for cumulative reward
Vectors where components use different names
\(S_t(R_t, p_t)\): has code S_t.R_t and S_t.p_t, is read ‘S at t in R at t, and, S at t in p at t’
the code implementation is by means of a named tuple
self.State = namedtuple('State', SVarNames) for the ‘class’ of the vector
self.S_t for the ‘instance’ of the vector
Vectors where components reuse names
\(x_t(x_{t,GB}, x_{t,BL})\): has code x_t.x_t_GB and x_t.x_t_BL, is read ‘x at t in x at t for GB, and, x at t in x at t for BL’
the code implementation is by means of a named tuple
self.Decision = namedtuple('Decision', xVarNames) for the ‘class’ of the vector
self.x_t for the ‘instance’ of the vector
Use of mixed-case variable names
to reduce confusion, sometimes the use of mixed-case variable names are preferred (even though it is not a best practice in the Python community), reserving the use of underscores and double underscores for math-related variables
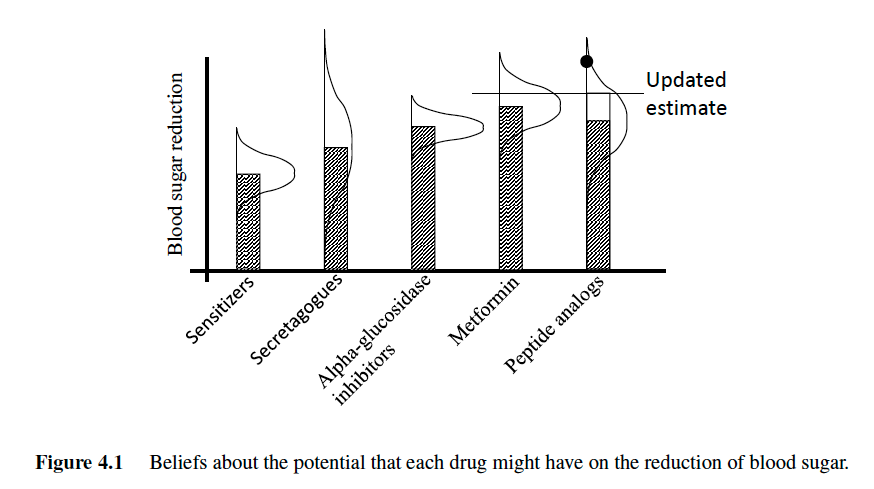
When people find they have high blood sugar, typically evaluated using a metric called the “A1C” level, there are several dozen drugs that fall into four major groups: - Sensitizers - These target liver, muscle, and fat cells to directly increase insulin sensitivity, but may cause fluid retention and therefore should not be used for patients with a history of kidney failure. - Secretagoges - These drugs increase insulin sensitivity by targeting the pancreas but often causes hypoglycemia and weight gain. - Alphaglucosidase inhibitors - These slow the rate of starch metabolism in the intestine, but can cause digestive problems. - Peptide analogs - These mimic natural hormones in the body that stimulate insulin production.
The most popular drug is a type of sensitizer called metformin, which is almost always the first medication that is prescribed for a new diabetic, but this does not always work. Prior to working with a particular patient, a physician may have a belief about the potential of metformin, and drugs from each of the four groups, to reduce blood sugar that is illustrated in figure 4.1.
Beliefs about reduction in blood sugar_Fig4-1
A physician will typically start with metformin, but this only works for about 70 percent of patients. Often, patients simply cannot tolerate a medication (it may cause severe digestive problems). When this is the case, physicians have to begin experimenting with different drugs. This is a slow process, since it takes several weeks before it is possible to assess the effect a drug is having on a patient. After testing a drug on a patient for a period of time, we observe the reduction in the A1C level, and then use this observation to update our estimate of how well the drug works on the patient.
2 DATA UNDERSTANDING
# import pdbfrom collections import namedtuple, Counter, defaultdictimport numpy as npimport pandas as pdimport mathfrom random import randintimport matplotlib.pyplot as pltfrom copy import copyimport timeimport matplotlib as mplfrom certifi.core import wherepd.options.display.float_format ='{:,.4f}'.formatpd.set_option('display.max_columns', None)pd.set_option('display.max_rows', None)pd.set_option('display.max_colwidth', None)! python --version
Python 3.10.11
3 DATA PREPARATION
def formatFloatList(L,p): sFormat ="{{:.{}f}} ".format(p) *len(L) outL = sFormat.format(*L)return outL.split()def normalizeCounter(counter): total =sum(counter.values(), 0.0)for key in counter: counter[key] /= totalreturn counter# This function returns the precision (beta), given the s.d. (sigma)def Beta(sigma):return1/sigma**2
mubar__0 sigbar__0 mu_truth sig_truth mu_fixed fixed_uniform_a \
M 0.3200 0.1200 0.2500 0 0.3000 -0.1500
Sens 0.2800 0.1900 0.3000 0 0.3000 -0.1500
Secr 0.3000 0.1700 0.2800 0 0.3000 -0.1500
AGI 0.2600 0.1500 0.3400 0 0.3000 -0.1500
PA 0.2100 0.2100 0.2400 0 0.3000 -0.1500
fixed_uniform_b prior_mult_a prior_mult_b Unnamed: 10 mu_prior_0 \
M 0.1500 -0.5000 0.5000 NaN 0.3200
Sens 0.1500 -0.5000 0.5000 NaN 0.2800
Secr 0.1500 -0.5000 0.5000 NaN 0.3000
AGI 0.1500 -0.5000 0.5000 NaN 0.2600
PA 0.1500 -0.5000 0.5000 NaN 0.2100
sigma_prior_0 \
M 0.1200
Sens 0.1900
Secr 0.1700
AGI 0.1500
PA 0.2100
Notes:
M Adjust columns mubar__0 and sigbar__0 to set up the initial parameters of the prior. Those columns are used for ALL types of "truth_type" that you might select in sheet "parameters2"
Sens Adjust columns mu_truth and sig_truth when the "truth_type" are "known" or "normal"
Secr Adjust columns mu_fixed, fixed_uniform_a and fixed_uniform_b when the "truth_type" is "fixed_uniform"
AGI Adjust columns prior_mult_a and prior_mult_b when the "truth_type" is "prior_uniform"
PA NaN
The interval that is going to be considered in the algorithm is [theta_start, theta_start + increment, …, theta_end)
theta_end
2.1000
NaN
NaN
increment
0.2000
NaN
NaN
truth_type
fixed_uniform
NaN
Possible values are "known", "fixed_uniform", "prior_uniform" or "normal". Pick one.
policy
IE
NaN
The possible policies are IE, UCB, PureExploitation, and PureExploration. You can select more than one by typing more than one policy name (separated by blank space)
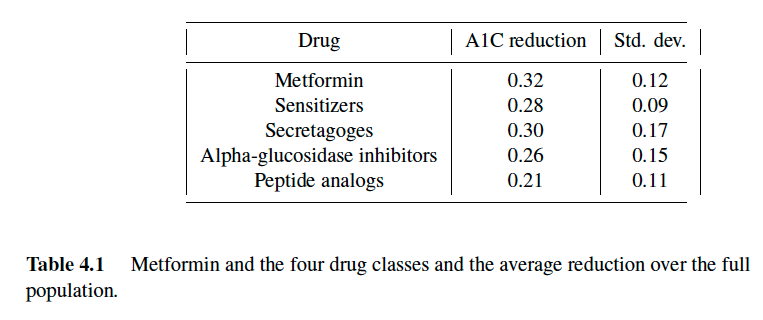
For our basic model, we are going to assume that we have five choices of medications: metformin, or a drug (other than metformin) drawn from one of the four major drug groups. Let \(\cal{X} = \{x_\mathrm{M}, x_\mathrm{Sens}, x_\mathrm{Secr}, x_\mathrm{AGI}, x_\mathrm{PA}\}\) be the five choices. From observing the performance of each drug over many (that is, millions) of patients, it is possible to construct a probability distribution of the reduction in A1C levels across all patients. The results of this analysis are shown in table 4.1 which reports the average reduction and the standard deviation across all patients. We assume that the distribution of reductions in A1C across the population is normally distributed, with means and standard deviations as given in the table:
Reduction over full population
4.2 Core Elements
This section attempts to answer three important questions: - What metrics are we going to track? - What decisions do we intend to make? - What are the sources of uncertainty?
For this problem, the only metric we are interested in is the amount of reduction in blood sugar at the end of N trials. A single type of decision needs to be made at the start of each trial - which medication should be prescribed next. The only source of uncertainty is the level of reduction for each medication.
4.3 Mathematical Model | SUM Design
To have a model, we want
\(\bar{\mu}^0_e\) = mean reduction in A1C for drug \(e\) across the population
\(\bar{\sigma}^0_e\) = stdv reduction in A1C for drug \(e\) across the population
Our interest is learning the best drug for a particular individual. Although we can describe the patient using a set of attributes, for now we are only going to assume that the characteristics of the patient do not change our belief about the performance of each drug for an individual patient.
We do not know the reduction we can expect from each drug, so we represent it as a random variable \(\mu_e\), where we assume that \(\mu_e\) is normally distributed, which we write as
We refer to the normal distribution \(N(\bar{\mu}^0_e, \bar{\sigma}^0_e)\) as the prior distribution of belief about \(\mu_e\).
We index each iteration of prescribing a medication by \(n\) which starts at 0. Assume that we always observe a patient for a fixed period of time (say, a month). If we try a drug \(e\) on a patient, we make a noisy observation of the truth value \(\mu_e\). Assume we make a choice of drug \(x^n\) using what we know after \(n\) trials, after which we observe the outcome of the \(n + 1\)st trial, which we denote \(W^{n+1}\) (this is the reduction in the A1C level). This can be written
\(W^{n+1} = \mu_e + \epsilon^{n+1}\).
Remember that we do not know \(\mu_e\); this is a random variable, where \(\bar{\mu}^n_e\) is our current estimate of the mean of \(\mu_e\).
4.3.1 State variables
The state variables represent what we need to know. We are using a Bayesian belief model wherein we treat the unknown value of a drug, \(\mu_e\), as a random variable with initial prior distribution given by \(S^0\). After \(n\) experiments with different drugs, we obtain the posterior distribution of belief \(S^n\).
The exogenous information variables represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(x^n\).
After we make the decision \(x^n\), we observe
\[
W^{n+1}_x = \text{the reduction in A1C level resulting from }x = x^n \text{ for the }n+1 \text{ st trial.}
\]
The latest exogenous information can be accessed by calling the following method from class MedicalDecisionDiabetesModel():
def W_fn(self, x__n):
# W^n+1 ~~tilde~~ N(mu_x, beta^W_x)
hot_e = [k for k,v in x__n.x__n.items() if v == 1][0]
W__nt1 = self.prng.normal(self.mu[hot_e], self.sigma__W)
beta__W = Beta(self.sigma__W)
return {"W": W__nt1, "mu": self.mu[hot_e], "beta__W": beta__W}
4.3.4 Transition function
The transition function describe how the state variables evolve over time. Because we currently have three state variables in the state, \(S_t=(\bar{\mu}^n,\beta^n,N^n)\), we have the equations:
Collectively, they represent the general transition function:
\[
S_{t+1} = S^M(S_t,X^{\pi}(S_t))
\] The transition function is implemented by the following method in class MedicalDecisionDiabetesModel():
def S__M_fn(self, x__n, exog_info):
hot_e = [k for k,v in x__n.x__n.items() if v == 1][0]
mub__n = getattr(self.S__n, 'mub__n')[hot_e]
bet__n = getattr(self.S__n, 'bet__n')[hot_e]
betaW = exog_info["betaW"]
W__nt1 = exog_info["W"]
N__n = getattr(self.S__n, 'N__n')[hot_e]
bet__nt1 = bet__n + betaW
mub__nt1 = (bet__n*mub__n + betaW*W__nt1)/bet__nt1
N__nt1 = N__n + 1
tmp = {
'mub__n': {hot_e: mub__nt1},
'bet__n': {hot_e: bet__nt1},
'N__n': {hot_e: N__nt1}
}
exog_info.update(tmp)
S__n_info = {s: getattr(self.S__n, s) for s in self.SNames}
for s in self.SNames:
S__n_info[s][hot_e] = exog_info[s][hot_e]
S__nt1 = self.build_state(S__n_info)
return S__nt1
4.3.5 Objective function
The objective function captures the performance metrics of the solution to the problem.
Each time a drug (entity) is prescribed by a decision \(x = x^n\), we observe a reduction in A1C, \(W^{n+1}_{x^n}\). We need to find a policy that prescribes a treatment \(x^n = X^{\pi}(S^n)\) that maximizes the expected total reduction in A1C. Our performance metric is therefor
The reward function is implemented by the following method in class MedicalDecisionDiabetesModel:
def F_fn(self, x__n, exog_info):
mu = exog_info["mu"]
# W__nt1 = exog_info["W"]
return mu
# return W__nt1
4.3.6 Implementation of SUM Model
Here is the complete implementation of the MedicalDecisionDiabetesModel class:
class MedicalDecisionDiabetesModel():def__init__(self, SNames, xNames, eNames, params, additional_params, W_fn=None, S__M_fn=None, F_fn=None, seed=20180529):self.initArgs = {seed: seed}self.prng = np.random.RandomState(seed)self.S__0 = {'mub__n': {e: params.loc[e]['mubar__0'] for e in eNames},'bet__n': {e: Beta(params.loc[e]['sigbar__0']) for e in eNames},'N__n': {e: 0for e in eNames}}self.SNames = SNamesself.xNames = xNamesself.eNames = eNamesself.State = namedtuple('State', SNames) # 'class'self.S__n =self.build_state(self.S__0) # 'instance'self.Decision = namedtuple('Decision', xNames)self.cumF =0.0self.sigmaW = additional_params.loc['sig__W', 0]self.truth_type = additional_params.loc['truth_type', 0]self.mu = {} #updated using W_sample_mu() at the beginning of each sample path #.truthself.t =0#time counter (in months)self.truth_params = {}ifself.truth_type =='fixed_uniform':self.truth_params = {e: [ params.loc[e, 'mu_fixed'], params.loc[e, 'fixed_uniform_a'], params.loc[e, 'fixed_uniform_b']] for e inself.eNames}elifself.truth_type =='prior_uniform':self.truth_params = {e: [ params.loc[e, 'mu_0'], params.loc[e, 'prior_mult_a'], params.loc[e, 'prior_mult_b']] for e inself.eNames}else:self.truth_params = {e: [ params.loc[e, 'mu_truth'], params.loc[e, 'sigma_truth'], 0] for e inself.eNames}def printState(self):print("Current state ")for sn inself.SNames:if sn=='mub__n': mubars =getattr(self.S__n, 'mub__n') mubars_f = {k: f'{v:.2f}'for k,v in mubars.items()}print(f'mub__n={mubars_f}')elif sn=='bet__n': betas =getattr(self.S__n, 'bet__n') betas_f = {k: f'{v:.2f}'for k,v in betas.items()}print(f'bet__n={betas_f}') sigmas = {k: 1/math.sqrt(v) for k,v in betas.items()} sigmas_f = {k: f'{v:.2f}'for k,v in sigmas.items()}print(f'sgb__n={sigmas_f}')else:print(f'{sn}={getattr(self.S__n, sn)}')print("\n\n")def printTruth(self):print("Model truth_type {}. Measurement noise sigmaW {} ".format(self.truth_type, self.sigmaW))for e inself.eNames:print("Treatment {}: par1 {:.2f}, par2 {:.2f} and par3 {}".format(e, self.truth_params[e][0], self.truth_params[e][1], self.truth_params[e][2]))print("\n\n")def build_state(self, info):returnself.State(*[info[sn] for sn inself.SNames])def build_decision(self, info):returnself.Decision(*[info[xn] for xn inself.xNames])def W_sample_mu(self):ifself.truth_type =="known":self.mu = {e: self.truth_params[e][0] for e inself.eNames} #.elifself.truth_type =="fixed_uniform": #. all mu btw (.30 - .15) and (.30 + .15), i.e. reductions always btw .15 and .45self.mu = {e: self.truth_params[e][0] +self.prng.uniform(self.truth_params[e][1], self.truth_params[e][2]) for e inself.eNames} #.elifself.truth_type =="prior_uniform":self.mu = {e: self.truth_params[e][0] +self.prng.uniform(self.truth_params[e][1]*self.truth_params[e][0], self.truth_params[e][2]*self.truth_params[e][0]) for e inself.eNames} #.else:self.mu = {e: self.prng.normal(self.truth_params[e][0], self.truth_params[e][1]) for e inself.eNames} #.# Gives the exogenous information that is dependent on a random process# In our case, exogeneous information: W^(n+1) = mu_x + eps^(n+1),# W^n+1 = mu_x + eps^n+1 #.# where:# eps^n+1 is normally distributed with mean 0 and known variance (here s.d. 0.05)# W^n+1_x is the reduction in A1C leveldef W_fn(self, x__n):# W^n+1 ~~tilde~~ N(mu_x, beta^W_x) hot_e = [k for k,v in x__n.x__n.items() if v ==1][0] W__nt1 =self.prng.normal(self.mu[hot_e], self.sigmaW) betaW = Beta(self.sigmaW)return {"W": W__nt1, "mu": self.mu[hot_e], "betaW": betaW}# Takes in the decision and exogenous information to return# the new mu_empirical and beta values corresponding to the decisiondef S__M_fn(self, x__n, exog_info): hot_e = [k for k,v in x__n.x__n.items() if v ==1][0] mub__n =getattr(self.S__n, 'mub__n')[hot_e] bet__n =getattr(self.S__n, 'bet__n')[hot_e] betaW = exog_info["betaW"] W__nt1 = exog_info["W"] N__n =getattr(self.S__n, 'N__n')[hot_e]#. beta^n+1_x = beta^n_x + beta^W (SDAM-4.2), (OL-2.7) bet__nt1 = bet__n + betaW#. (beta^n_x*mubar^n+1_x + beta^W_x * W^n+1_x) / beta^n+1_x (SDAM-4.1), (OL-2.6) mub__nt1 = (bet__n*mub__n + betaW*W__nt1)/bet__nt1 #. was mu_empirical N__nt1 = N__n +1#. count of no. times given, for drug x tmp = { 'mub__n': {hot_e: mub__nt1}, 'bet__n': {hot_e: bet__nt1}, 'N__n': {hot_e: N__nt1} } exog_info.update(tmp);#print(f'### {exog_info=}') S__n_info = {s: getattr(self.S__n, s) for s inself.SNames};#print(f'### {S__n_info=}')for s inself.SNames: S__n_info[s][hot_e] = exog_info[s][hot_e] S__nt1 =self.build_state(S__n_info);#print(f'### {S__n_info=}')return S__nt1# Calculates W (reduction in A1C level)def F_fn(self, x__n, exog_info): mu = exog_info["mu"]# W__nt1 = exog_info["W"]return mu #. ORIG# return W__nt1 #.# Steps the process forward by one time increment by updating the sum of # the contributions, the exogenous information and the state variabledef step(self, x__n):# compute new mu_empirical and beta for the decision exog_info =self.W_fn(x__n);#print(f'### {exog_info=}')self.S__n =self.S__M_fn(x__n, exog_info)# update reward (add new W to previous obj) F =self.F_fn(x__n, exog_info)self.cumF += Fself.t_update() return (self.S__n, self.cumF, x__n, exog_info)# Update method for time counterdef t_update(self):self.t +=1returnself.tdef mubs_by_eNames(self, withForNames=True): stats = {}for e inself.eNames: ss = []for s inself.SNames: ss.append(getattr(self.S__n, s)[e]) value = ss[0];#print(value) stats.update({e: value})# print(f'{stats=}')if withForNames: return statselse: return [stats[key] for key in stats]def bets_by_eNames(self, withForNames=True): stats = {}for e inself.eNames: ss = []for s inself.SNames: ss.append(getattr(self.S__n, s)[e]) value = ss[1];#print(value) stats.update({e: value})# print(f'{stats=}')if withForNames: return statselse: return [stats[key] for key in stats]def sgbs_by_eNames(self, withForNames=True): stats = {}for e inself.eNames: ss = []for s inself.SNames: ss.append(getattr(self.S__n, s)[e]) value =1/math.sqrt(ss[1]);#print(value) stats.update({e: value})# print(f'{stats=}')if withForNames: return statselse: return [stats[key] for key in stats]def Ns_by_eNames(self, withForNames=True): stats = {}for e inself.eNames: ss = []for s inself.SNames: ss.append(getattr(self.S__n, s)[e]) value = ss[2];#print(value) stats.update({e: value})# print(f'{stats=}')if withForNames: return statselse: return [stats[key] for key in stats]
4.4 Uncertainty Model
As stated in 4.3.3, we have
After we make the decision \(x^n\), we observe
\[
W^{n+1}_x = \text{the reduction in A1C level resulting from }x = x^n \text{ for the }n+1 \text{ st trial.}
\]
4.5 Policy Design
There are two main meta-classes of policy design. Each of these has two subclasses: - Policy Search - Policy Function Approximations (PFAs) - Cost Function Approximations (CFAs) - Lookahead - Value Function Approximations (VFAs) - Direct Lookaheads (DLAs)
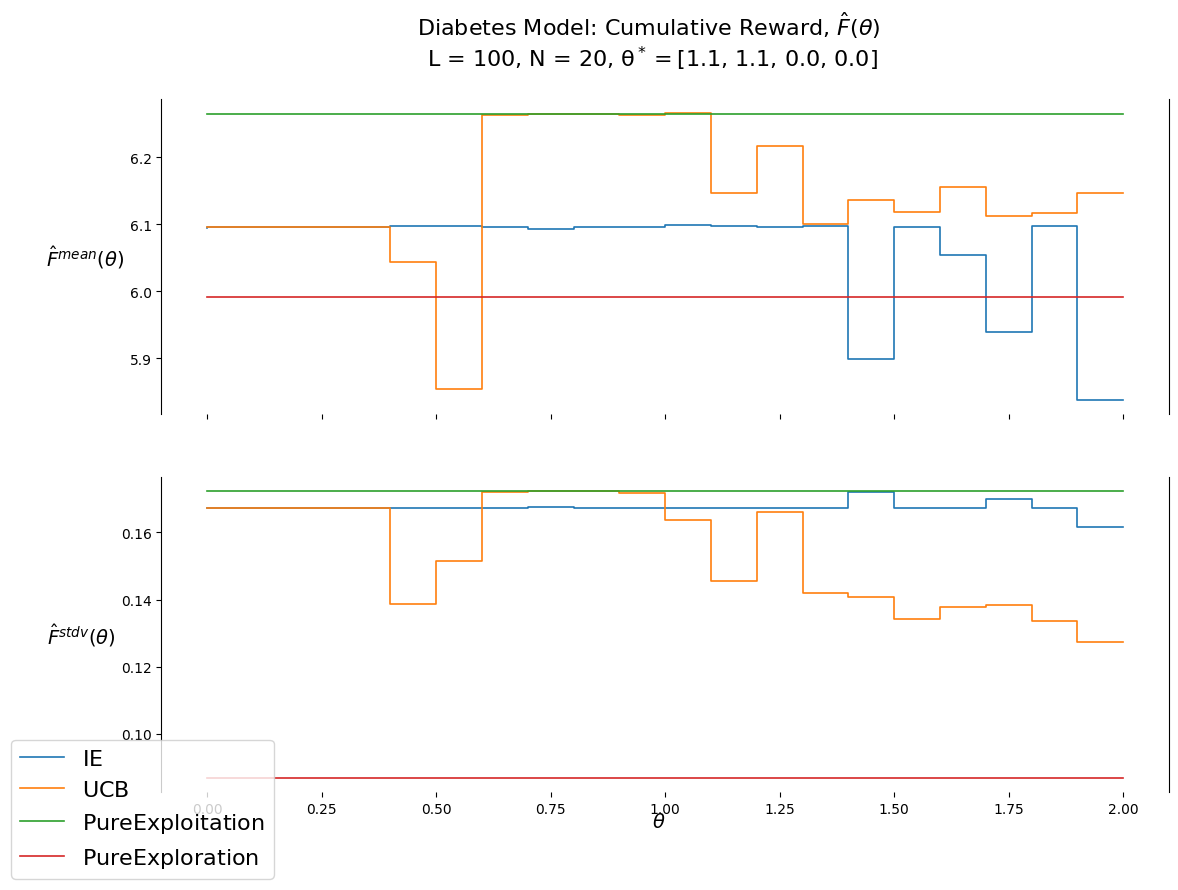
In this project we will use 4 policies from the PFA class:
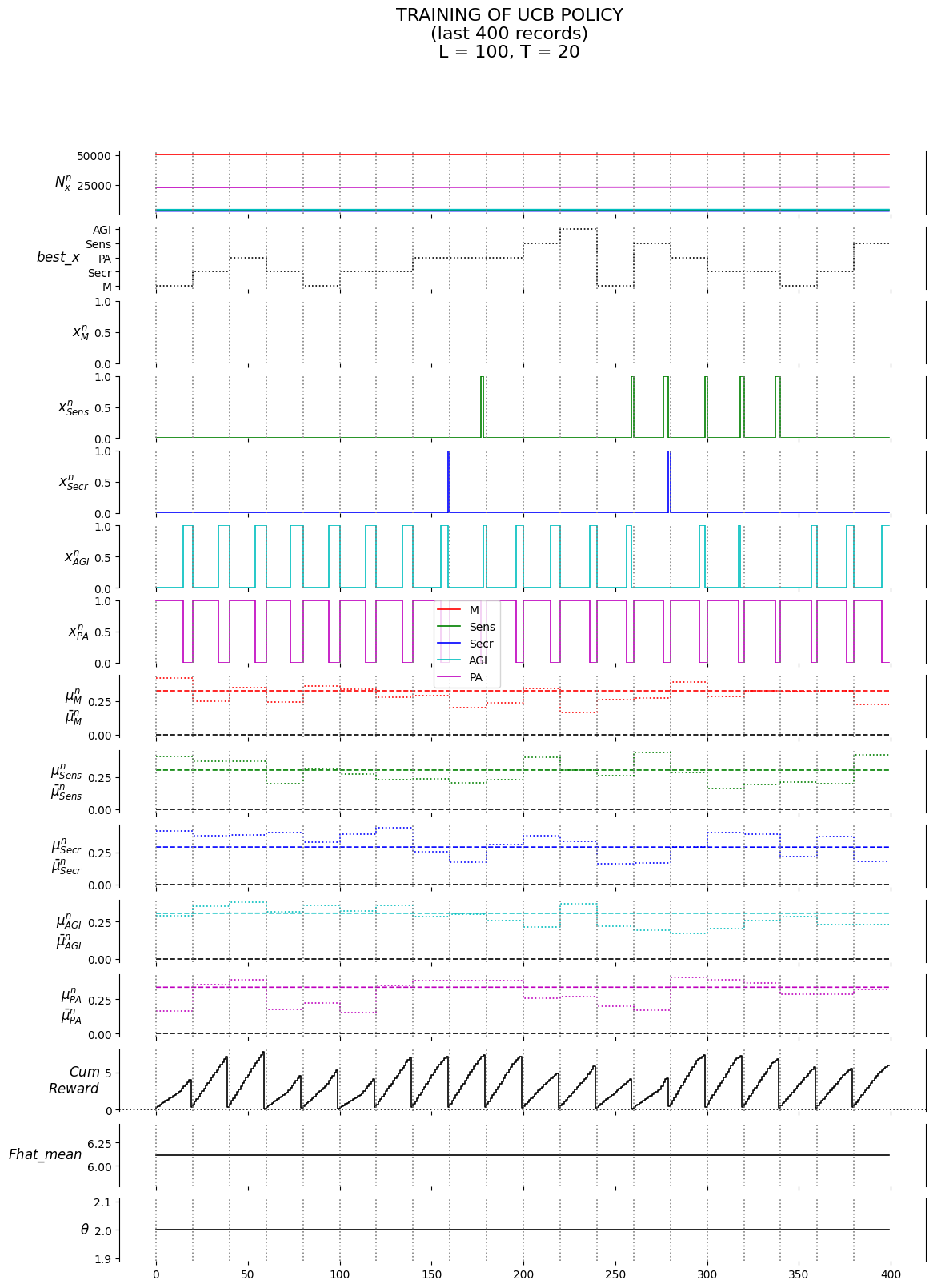
# data structures to output the algorithm detailsmu_star_labels = ["mu_"+e for e in eNames];#print(f"{mu_star_labels=}")Scum_mu_x_labels = ["Scum_mu_"+e for e in eNames];#print(f"{Scum_mu__x_=}") #.Savg_mu_x_labels = ["Savg_mu_"+e for e in eNames];#print(f"{Savg_mu__x_=}") #.mub_labels = ["mub__n_"+e for e in eNames];#print(f"{mu_labels=}")sgb_labels = ["sgb__n_"+e for e in eNames];#print(f"{sigma_labels=}")N_labels = ["N__n_"+e for e in eNames];#print(f'{N_labels=}')x_labels = ["x__n_"+e for e in eNames]labels = ["Policy","Truth_type","Theta","Fhat_mean","l"] +\ mu_star_labels + Scum_mu_x_labels + Savg_mu_x_labels + ["best_x", "n"] +\ mub_labels + sgb_labels + N_labels + x_labels + ["W","CumReward","isBest"]
def run_policy_evalu(piInfo_evalu, piName_evalu, stop_time_evalu, model_copy): record = [] model_copy.W_sample_mu()for n inrange(stop_time_evalu): x__n =getattr(P_evalu, piName_evalu)(model_copy, piInfo_evalu) S__n, F, x__n, exog_info = model_copy.step(x__n) # step the model forward one iteration record_n =\ [model_copy.mu[e] for e in eNames] +\ [S__n.mub__n[e] for e in eNames] +\ [1/math.sqrt(S__n.bet__n[e]) for e in eNames] +\ [S__n.N__n[e] for e in eNames] +\ [x__n.x__n[e] for e in eNames] +\ [exog_info['W']] +\ [F] record.append(record_n) cumF = model_copy.cumF return cumF, record
4.6.2.1 Evalutate with data similar to train data
4.6.2.1.1 Non-optimal policy
theta_evalu_non=thetaStar_PureExploration# theta_evalu_non=thetaStar_PureExploitation# piName_evalu_non = 'X__IE'# piName_evalu_non = 'X__UCB'piName_evalu_non ='X__PureExploration'# piName_evalu_non = 'X__PureExploitation'F, record = run_policy_evalu(theta_evalu_non, piName_evalu_non, stop_time_evalu, copy(M_evalu))labels_evalu =\ ["mu__n_"+e for e in eNames] +\ ["mub__n_"+e for e in eNames] +\ ["sgb__n_"+e for e in eNames] +\ ["N__n_"+e for e in eNames] +\ ["x__n_"+e for e in eNames] +\ ["W", "CumReward"]print(f'{theta_evalu_non=}')print(f'{int(F)=:,}')df_non = pd.DataFrame.from_records(data=record, columns=labels_evalu); df_non[:10]
theta_evalu_non=(0.0,)
int(F)=142
mu__n_M
mu__n_Sens
mu__n_Secr
mu__n_AGI
mu__n_PA
mub__n_M
mub__n_Sens
mub__n_Secr
mub__n_AGI
mub__n_PA
sgb__n_M
sgb__n_Sens
sgb__n_Secr
sgb__n_AGI
sgb__n_PA
N__n_M
N__n_Sens
N__n_Secr
N__n_AGI
N__n_PA
x__n_M
x__n_Sens
x__n_Secr
x__n_AGI
x__n_PA
W
CumReward
0
0.2742
0.1832
0.2893
0.4046
0.2856
0.3200
0.2800
0.2012
0.2600
0.2100
0.1200
0.1900
0.1610
0.1500
0.2100
0
0
1
0
0
0
0
1
0
0
-0.6532
0.2893
1
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2800
0.2012
0.2600
0.2100
0.1167
0.1900
0.1610
0.1500
0.2100
1
0
1
0
0
1
0
0
0
0
0.8555
0.5635
2
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2800
0.2012
0.2913
0.2100
0.1167
0.1900
0.1610
0.1437
0.2100
1
0
1
1
0
0
0
0
1
0
0.6388
0.9681
3
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2512
0.2012
0.2913
0.2100
0.1167
0.1776
0.1610
0.1437
0.2100
1
1
1
1
0
0
1
0
0
0
0.0516
1.1513
4
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2512
0.1646
0.2913
0.2100
0.1167
0.1776
0.1532
0.1437
0.2100
1
1
2
1
0
0
0
1
0
0
-0.1886
1.4406
5
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2512
0.1646
0.2913
0.3149
0.1167
0.1776
0.1532
0.1437
0.1936
1
1
2
1
1
0
0
0
0
1
0.9095
1.7262
6
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2009
0.1646
0.2913
0.3149
0.1167
0.1674
0.1532
0.1437
0.1936
1
2
2
1
1
0
1
0
0
0
-0.1972
1.9094
7
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2009
0.1646
0.2911
0.3149
0.1167
0.1674
0.1532
0.1381
0.1936
1
2
2
2
1
0
0
0
1
0
0.2887
2.3140
8
0.2742
0.1832
0.2893
0.4046
0.2856
0.3492
0.2009
0.1646
0.3442
0.3149
0.1167
0.1674
0.1532
0.1331
0.1936
1
2
2
3
1
0
0
0
1
0
1.0409
2.7186
9
0.2742
0.1832
0.2893
0.4046
0.2856
0.3116
0.2009
0.1646
0.3442
0.3149
0.1136
0.1674
0.1532
0.1331
0.1936
2
2
2
3
1
1
0
0
0
0
-0.3782
2.9928
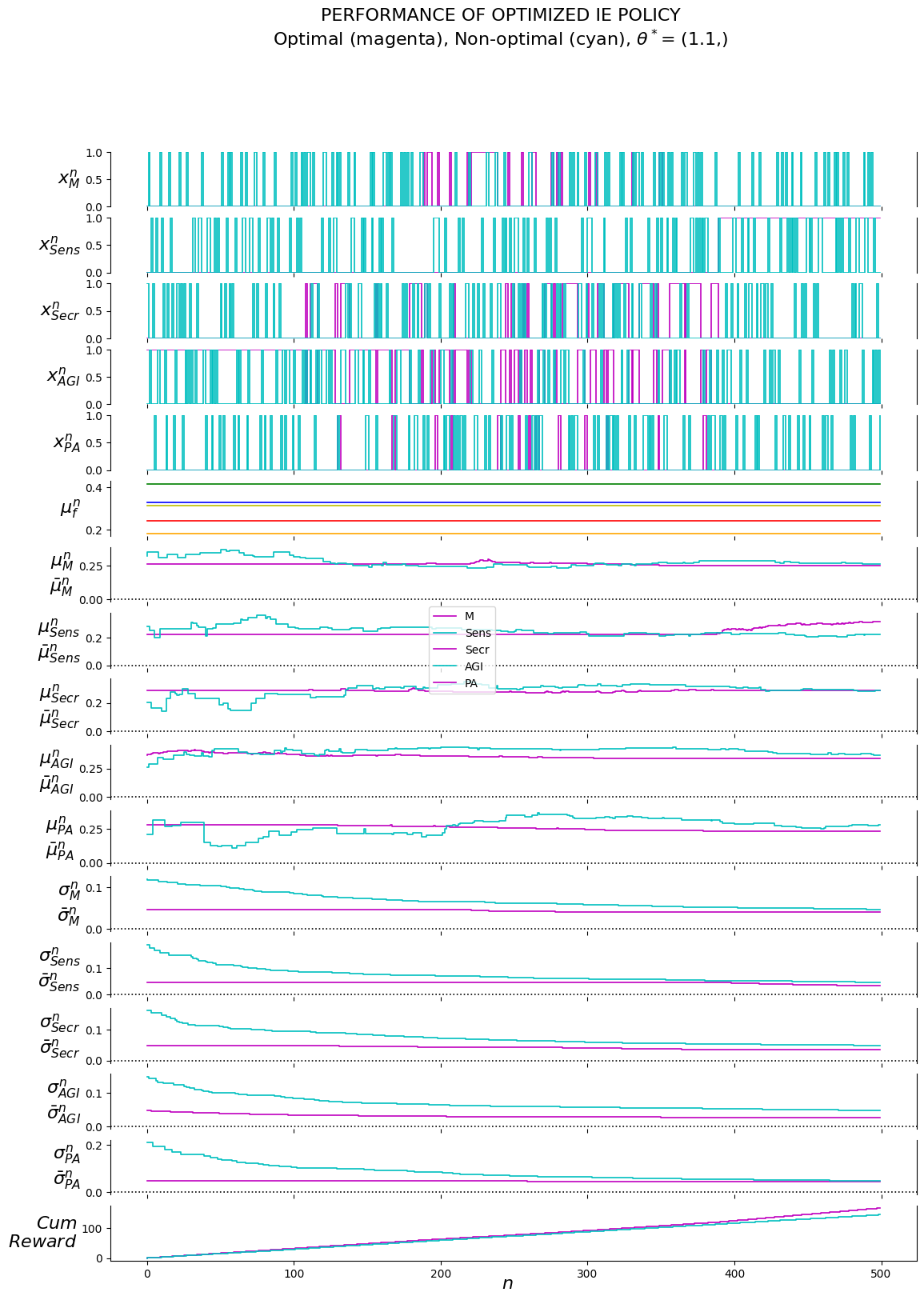
4.6.2.1.2 Optimal policy
# theta_evalu = thetaStar_IEtheta_evalu = thetaStar_UCB# piName_evalu = 'X__IE'piName_evalu ='X__UCB'F, record = run_policy_evalu(theta_evalu, piName_evalu, stop_time_evalu, copy(M_evalu))labels_evalu =\ ["mu__n_"+e for e in eNames] +\ ["mub__n_"+e for e in eNames] +\ ["sgb__n_"+e for e in eNames] +\ ["N__n_"+e for e in eNames] +\ ["x__n_"+e for e in eNames] +\ ["W", "CumReward"]print(f'{theta_evalu=}')print(f'{int(F)=:,}')df = pd.DataFrame.from_records(data=record, columns=labels_evalu); df[:10]