!python --versionPython 3.7.14It is important for an inventory manager to maintain inventory at optimal levels for each kind of product. Too much inventory incurs a holding cost while too little inventory gives rise to a stockout cost. This balancing act could be addressed by framing this problem as a Markov Reward Process. This type of framework is intermediate between a Markov Process (also known as a Markov Chain) and Markov Decision Process. Markov Processes may be presented, in order of increasing complexity, in the following way:
In this project we will take the Markov Process from the previous project, and add a reward associated with each transition. This means our inventory problem has become a Markov Reward Process.
Each scalar reward will come from a probability distribution. The optimization purpose of this framework has to do with discovering the expected accumulated reward associated with each non-terminal state.
Formally, a Markov Reward Process consists of:
There are two main cost elements related to inventory items:
Note that costs may be thought of as negative rewards.
We need to express the transition probabilities of the Markov Reward Process, taking the rewards into account:
\[ \begin{aligned} \mathcal P_R(s,s',r) &= p(s',r|s) \\ &= \mathbb P[S_{t+1}=s',R_{t+1}=r|S_t=s] \end{aligned} \] for \(t=0,1,2,...\), for all \(s \in \mathcal N, r \in \mathcal D, s' \in \mathcal S\), such that \[ \sum_{s' \in \mathcal S} \sum_{r \in \mathcal D}\mathcal P_R(s,s'r) = 1 \] for all \(s \in \mathcal N\)
As before, we have the constraints:
We use the reward transition function, \(\mathcal R_T\) to calculate the rewards. There are two situations to consider: - \(\alpha\) of \(S_{t+1} > 0\) (i.e. the next state’s on-hand inventory is greater than zero) - \(\mathcal R_T((\alpha,\beta),(\alpha+\beta-i,C-(\alpha+\beta)))=-h\alpha \quad\text{for } 0\le i \le \alpha+\beta-1 \quad \text{(4.3)}\) - \(\alpha\) of \(S_{t+1} = 0\) (i.e. the next state’s on-hand inventory is zero) - \(\mathcal R_T((\alpha,\beta),(0,C-(\alpha+\beta)))=-h\alpha -p(\lambda(1-F(\alpha+\beta-1))-(\alpha+\beta)(1-F(\alpha+\beta))) \quad \text{(4.4)}\)
!python --versionPython 3.7.14We make use of the approach followed in http://web.stanford.edu/class/cme241/.
from __future__ import annotations
from abc import ABC, abstractmethod
import random
from typing import Generic, TypeVar, Sequence, Callable, Iterator, Tuple, Iterable, Set, Mapping, Dict
from collections import defaultdict
import graphviz
import numpy as np
from pprint import pprint
from dataclasses import dataclass
from scipy.stats import poissonFigure 5.1 shows the Python classes used with the inheritance relationships between them.

A = TypeVar('A')
B = TypeVar('B')
class Distribution(ABC, Generic[A]):
@abstractmethod
def sample(self) -> A:
pass
def sample_n(self, n: int) -> Sequence[A]: #n random samples
return [self.sample() for _ in range(n)]
@abstractmethod
def expectation(self, f: Callable[[A], float]) -> float:
pass
def map(self, f: Callable[[A], B]) -> Distribution[B]:
return SampledDistribution(lambda: f(self.sample()))
def apply(self, f: Callable[[A], Distribution[B]]) -> Distribution[B]:
def sample():
a = self.sample()
b_dist = f(a)
return b_dist.sample()
return SampledDistribution(sample)class SampledDistribution(Distribution[A]):
sampler: Callable[[], A]
expectation_samples: int
def __init__(
self,
sampler: Callable[[], A],
expectation_samples: int = 10000
):
self.sampler = sampler
self.expectation_samples = expectation_samples
def sample(self) -> A:
return self.sampler()
def expectation(
self,
f: Callable[[A], float]
) -> float:
return
sum(f(self.sample())
for _ in range(self.expectation_samples))/self.expectation_samplesclass FiniteDistribution(Distribution[A], ABC):
@abstractmethod
def table(self) -> Mapping[A, float]:
pass
def probability(self, outcome: A) -> float:
return self.table()[outcome]
def map(self, f: Callable[[A], B]) -> FiniteDistribution[B]:
result: Dict[B, float] = defaultdict(float)
for x, p in self:
result[f(x)] += p
return Categorical(result)
def sample(self) -> A:
outcomes = list(self.table().keys())
weights = list(self.table().values())
return random.choices(outcomes, weights=weights)[0]
def expectation(self, f: Callable[[A], float]) -> float:
return sum(p * f(x) for x, p in self)
def __iter__(self) -> Iterator[Tuple[A, float]]:
return iter(self.table().items())
def __eq__(self, other: object) -> bool:
if isinstance(other, FiniteDistribution):
return self.table() == other.table()
else:
return False
def __repr__(self) -> str:
return repr(self.table())class Categorical(FiniteDistribution[A]):
probabilities: Mapping[A, float]
def __init__(self, distribution: Mapping[A, float]):
total = sum(distribution.values())
self.probabilities = {outcome: probability/total #normalized
for outcome, probability in distribution.items()}
def table(self) -> Mapping[A, float]:
return self.probabilities
def probability(self, outcome: A) -> float:
return self.probabilities.get(outcome, 0.)Figure 5.2 shows the Python classes used with the inheritance relationships between them.

S = TypeVar('S')
X = TypeVar('X')
class State(ABC, Generic[S]):
state: S
def on_non_terminal(
self,
f: Callable[[NonTerminal[S]], X],
default: X
) -> X:
if isinstance(self, NonTerminal):
return f(self)
else:
return default@dataclass(frozen=True)
class Terminal(State[S]):
state: S@dataclass(frozen=True)
class NonTerminal(State[S]):
state: S
def __eq__(self, other):
return self.state == other.state
def __lt__(self, other):
return self.state < other.stateclass MarkovProcess(ABC, Generic[S]):
@abstractmethod
def transition(self, state: NonTerminal[S]) -> Distribution[State[S]]:
pass
def simulate(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[State[S]]:
state: State[S] = start_state_distribution.sample()
yield state
while isinstance(state, NonTerminal):
state = self.transition(state).sample()
yield state
def traces(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[Iterable[State[S]]]:
while True:
yield self.simulate(start_state_distribution)Transition = Mapping[NonTerminal[S], FiniteDistribution[State[S]]]class FiniteMarkovProcess(MarkovProcess[S]):
non_terminal_states: Sequence[NonTerminal[S]]
transition_map: Transition[S]
def __init__(self, transition_map: Mapping[S, FiniteDistribution[S]]):
non_terminals: Set[S] = set(transition_map.keys())
self.transition_map = {
NonTerminal(s): Categorical(
{(NonTerminal(s1) if s1 in non_terminals else Terminal(s1)): p
for s1, p in v}
) for s, v in transition_map.items()
}
self.non_terminal_states = list(self.transition_map.keys())
def __repr__(self) -> str:
display = ""
for s, d in self.transition_map.items():
display += f"From State {s.state}:\n"
for s1, p in d:
opt = "Terminal " if isinstance(s1, Terminal) else ""
display += f" To {opt}State {s1.state} with Probability {p:.3f}\n"
return display
def get_transition_matrix(self) -> np.ndarray:
sz = len(self.non_terminal_states)
mat = np.zeros((sz, sz))
for i, s1 in enumerate(self.non_terminal_states):
for j, s2 in enumerate(self.non_terminal_states):
mat[i, j] = self.transition(s1).probability(s2)
return mat
def transition(self, state: NonTerminal[S])\
-> FiniteDistribution[State[S]]:
return self.transition_map[state]
def get_stationary_distribution(self) -> FiniteDistribution[S]:
eig_vals, eig_vecs = np.linalg.eig(self.get_transition_matrix().T)
index_of_first_unit_eig_val = np.where(
np.abs(eig_vals - 1) < 1e-8)[0][0]
eig_vec_of_unit_eig_val = np.real(
eig_vecs[:, index_of_first_unit_eig_val])
return Categorical({
self.non_terminal_states[i].state: ev
for i, ev in enumerate(eig_vec_of_unit_eig_val /
sum(eig_vec_of_unit_eig_val))
})
def display_stationary_distribution(self):
pprint({
s: round(p, 3)
for s, p in self.get_stationary_distribution()
})
def generate_image(self) -> graphviz.Digraph:
d = graphviz.Digraph()
for s in self.transition_map.keys():
#d.node(str(s)) #.
d.node(f"{(s.state.on_hand, s.state.on_order)}") #.
for s, v in self.transition_map.items():
for s1, p in v:
#d.edge(str(s), str(s1), label=str(p)) #.
#d.edge(str(s), str(s1), label=f'{p:.3f}') #.
d.edge(f"{(s.state.on_hand, s.state.on_order)}", f"{(s1.state.on_hand, s1.state.on_order)}", label=f'{p:.2f}') #.
return dclass MarkovRewardProcess@dataclass(frozen=True)
class TransitionStep(Generic[S]):
state: NonTerminal[S]
next_state: State[S]
reward: float
def add_return(self, γ: float, return_: float) -> ReturnStep[S]:
'''Given a γ and the return from 'next_state', this annotates the
transition with a return for 'state'.
'''
return ReturnStep(
self.state,
self.next_state,
self.reward,
return_=self.reward + γ*return_
)@dataclass(frozen=True)
class ReturnStep(TransitionStep[S]):
return_: floatclass MarkovRewardProcess is a kind of MarkovProcess of S. - transition - implements the transition probability \[
\begin{aligned}
\mathcal P(s,s') &= p(s'|s) \\
&= \mathbb P[S_{t+1}=s'|S_t=s]
\end{aligned}
\] - transitions the Markov Reward Process, ignoring the generated reward (which makes this just a normal Markov Process) - transition_reward - implements the transition probability \[
\begin{aligned}
\mathcal P_R(s,s',r) &= p(s',r|s) \\
&= \mathbb P[S_{t+1}=s',R_{t+1}=r|S_t=s]
\end{aligned}
\] - given a state, returns a distribution of the next state and reward from transitioning between the states - simulate_reward - simulate the MRP, yielding an Iterable of (state, next state, reward) for each sampled transition - reward_traces - yield simulation traces (the output of simulate_reward), sampling a start state from the given distribution each time
class MarkovRewardProcess(MarkovProcess[S]):
def transition(self, state: NonTerminal[S]) -> Distribution[State[S]]:
distribution = self.transition_reward(state)
def next_state(distribution=distribution):
next_s, _ = distribution.sample()
return next_s
return SampledDistribution(next_state)
@abstractmethod
def transition_reward(self, state: NonTerminal[S])\
-> Distribution[Tuple[State[S], float]]:
pass
def simulate_reward(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[TransitionStep[S]]:
state: State[S] = start_state_distribution.sample()
reward: float = 0.
while isinstance(state, NonTerminal):
next_distribution = self.transition_reward(state)
next_state, reward = next_distribution.sample()
yield TransitionStep(state, next_state, reward)
state = next_state
def reward_traces(
self,
start_state_distribution: Distribution[NonTerminal[S]]
) -> Iterable[Iterable[TransitionStep[S]]]:
while True:
yield self.simulate_reward(start_state_distribution)class FiniteMarkovRewardProcessclass FiniteMarkovRewardProcess inherits from FiniteMarkovProcess[S] as well as from MarkovRewardProcess[S]. Some of the methods are: - get_value_function_vec() - this methods implements \(V=(I_m-\gamma\mathcal P)^{-1} \cdot \mathcal R\) where: - \(V\), the value function, is a column vector of length \(m\) - \(\mathcal P\), the transition function, is a \(m \times m\) matrix - \(\mathcal R\), the reward function, is a column vector of length \(m\) - \(\gamma\) is the dicount rate
StateReward = FiniteDistribution[Tuple[State[S], float]]
RewardTransition = Mapping[NonTerminal[S], StateReward[S]]class FiniteMarkovRewardProcess(FiniteMarkovProcess[S],
MarkovRewardProcess[S]):
transition_reward_map: RewardTransition[S]
reward_function_vec: np.ndarray
def __init__(
self,
transition_reward_map: Mapping[S, FiniteDistribution[Tuple[S, float]]]
):
transition_map: Dict[S, FiniteDistribution[S]] = {}
for state, trans in transition_reward_map.items():
probabilities: Dict[S, float] = defaultdict(float)
for (next_state, _), probability in trans:
probabilities[next_state] += probability
transition_map[state] = Categorical(probabilities)
super().__init__(transition_map)
nt: Set[S] = set(transition_reward_map.keys())
self.transition_reward_map = {
NonTerminal(s): Categorical(
{(NonTerminal(s1) if s1 in nt else Terminal(s1), r): p
for (s1, r), p in v}
) for s, v in transition_reward_map.items()
}
self.reward_function_vec = np.array([
sum(probability * reward for (_, reward), probability in
self.transition_reward_map[state])
for state in self.non_terminal_states
])
def __repr__(self) -> str:
display = ""
for s, d in self.transition_reward_map.items():
display += f"From State {s.state}:\n"
for (s1, r), p in d:
opt = "Terminal " if isinstance(s1, Terminal) else ""
display +=\
f" To [{opt}State {s1.state} and Reward {r:.3f}]"\
+ f" with Probability {p:.3f}\n"
return display
def transition_reward(self, state: NonTerminal[S]) -> StateReward[S]:
return self.transition_reward_map[state]
def get_value_function_vec(self, gamma: float) -> np.ndarray:
return np.linalg.solve(
np.eye(len(self.non_terminal_states)) -
gamma*self.get_transition_matrix(),
self.reward_function_vec
)
def display_reward_function(self):
pprint({
self.non_terminal_states[i]: round(r, 3)
for i, r in enumerate(self.reward_function_vec)
})
def display_value_function(self, gamma: float):
pprint({
self.non_terminal_states[i]: round(v, 3)
for i, v in enumerate(self.get_value_function_vec(gamma))
})
def generate_image(self) -> graphviz.Digraph:
d = graphviz.Digraph()
for s in self.transition_map.keys():
#d.node(str(s)) #.
d.node(f"{(s.state.on_hand, s.state.on_order)}") #.
# for s, v in si_mrp.transition_map.items():
for s, v in self.transition_reward_map.items():
for s1, p in v:
#d.edge(str(s), str(s1), label=str(p)) #.
#d.edge(str(s), str(s1), label=f'{p:.3f}') #.
# d.edge(f"{(s.state.on_hand, s.state.on_order)}", f"{(s1.state.on_hand, s1.state.on_order)}", label=f'{p:.2f}') #.
d.edge(f"{(s.state.on_hand, s.state.on_order)}", f"{(s1[0].state.on_hand, s1[0].state.on_order)}", label=f'{p:.2f}/{s1[1]:.1f}') #.
return dclass InventoryState@dataclass(frozen=True)
class InventoryState:
on_hand: int
on_order: int
def inventory_position(self) -> int:
return self.on_hand + self.on_orderclass SimpleInventoryMRPclass SimpleInventoryMRP(MarkovRewardProcess[InventoryState]):
def __init__(
self,
capacity: int,
poisson_lambda: float,
holding_cost: float,
stockout_cost: float
):
self.capacity = capacity
self.poisson_lambda: float = poisson_lambda
self.holding_cost: float = holding_cost
self.stockout_cost: float = stockout_cost
def transition_reward(
self,
state: NonTerminal[InventoryState]
) -> SampledDistribution[Tuple[State[InventoryState], float]]:
def sample_next_state_reward(state=state) ->\
Tuple[State[InventoryState], float]:
demand_sample: int = np.random.poisson(self.poisson_lambda)
ip: int = state.state.inventory_position()
#eq (4.1)
next_state: InventoryState = InventoryState(
max(ip - demand_sample, 0),
max(self.capacity - ip, 0)
)
#eq (4.2)
reward: float = \
-self.holding_cost*state.state.on_hand\
-self.stockout_cost*max(demand_sample - ip, 0)
return NonTerminal(next_state), reward
return SampledDistribution(sample_next_state_reward)# ---study SimpleInventoryMRP# ---end study SimpleInventoryMRPclass SimpleInventoryMRPFinite#
# ---study state_reward_probs_mapcapacity = 3
alpha = 2
beta = capacity - alpha; beta 1state = InventoryState(alpha, beta); stateInventoryState(on_hand=2, on_order=1)ip = state.inventory_position(); ip3beta1 = capacity - ip; beta10holding_cost = 1.0
base_reward = - holding_cost*state.on_handpoisson_lambda: float = 1.0
poisson_distr = poisson(poisson_lambda){
(InventoryState(ip - i, beta1), base_reward):
poisson_distr.pmf(i) for i in range(ip)
}{(InventoryState(on_hand=3, on_order=0), -2.0): 0.36787944117144233,
(InventoryState(on_hand=2, on_order=0), -2.0): 0.36787944117144233,
(InventoryState(on_hand=1, on_order=0), -2.0): 0.18393972058572114}capacity = 3
stockout_cost = 10.0
d: Dict[InventoryState, Categorical[Tuple[InventoryState, float]]] = {}
for alpha in range(capacity + 1): #alpha 0 to C
for beta in range(capacity + 1 - alpha): #beta 0 to C - alpha
state = InventoryState(alpha, beta)
ip = state.inventory_position()
beta1 = capacity - ip
base_reward = - holding_cost*state.on_hand
state_reward_probs_map: Dict[Tuple[InventoryState, float], float] = {
(InventoryState(ip - i, beta1), base_reward):
poisson_distr.pmf(i) for i in range(ip)
}
probability = 1 - poisson_distr.cdf(ip - 1)
reward = base_reward - stockout_cost*\
(probability*(poisson_lambda - ip) +
ip*poisson_distr.pmf(ip))
state_reward_probs_map[(InventoryState(0, beta1), reward)] = probability
d[state] = Categorical(state_reward_probs_map)state_reward_probs_map{(InventoryState(on_hand=3, on_order=0), -3.0): 0.36787944117144233,
(InventoryState(on_hand=2, on_order=0), -3.0): 0.36787944117144233,
(InventoryState(on_hand=1, on_order=0), -3.0): 0.18393972058572114,
(InventoryState(on_hand=0, on_order=0),
-3.2333692644293284): 0.08030139707139416}d{InventoryState(on_hand=0, on_order=0): {(InventoryState(on_hand=0, on_order=3), -10.0): 1.0},
InventoryState(on_hand=0, on_order=1): {(InventoryState(on_hand=1, on_order=2), -0.0): 0.3678794411714424, (InventoryState(on_hand=0, on_order=2), -3.6787944117144233): 0.6321205588285577},
InventoryState(on_hand=0, on_order=2): {(InventoryState(on_hand=2, on_order=1), -0.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=1), -0.0): 0.36787944117144233, (InventoryState(on_hand=0, on_order=1), -1.0363832351432696): 0.26424111765711533},
InventoryState(on_hand=0, on_order=3): {(InventoryState(on_hand=3, on_order=0), -0.0): 0.36787944117144233, (InventoryState(on_hand=2, on_order=0), -0.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=0), -0.0): 0.18393972058572114, (InventoryState(on_hand=0, on_order=0), -0.23336926442932837): 0.08030139707139416},
InventoryState(on_hand=1, on_order=0): {(InventoryState(on_hand=1, on_order=2), -1.0): 0.3678794411714424, (InventoryState(on_hand=0, on_order=2), -4.678794411714423): 0.6321205588285577},
InventoryState(on_hand=1, on_order=1): {(InventoryState(on_hand=2, on_order=1), -1.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=1), -1.0): 0.36787944117144233, (InventoryState(on_hand=0, on_order=1), -2.0363832351432696): 0.26424111765711533},
InventoryState(on_hand=1, on_order=2): {(InventoryState(on_hand=3, on_order=0), -1.0): 0.36787944117144233, (InventoryState(on_hand=2, on_order=0), -1.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=0), -1.0): 0.18393972058572114, (InventoryState(on_hand=0, on_order=0), -1.2333692644293284): 0.08030139707139416},
InventoryState(on_hand=2, on_order=0): {(InventoryState(on_hand=2, on_order=1), -2.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=1), -2.0): 0.36787944117144233, (InventoryState(on_hand=0, on_order=1), -3.0363832351432696): 0.26424111765711533},
InventoryState(on_hand=2, on_order=1): {(InventoryState(on_hand=3, on_order=0), -2.0): 0.36787944117144233, (InventoryState(on_hand=2, on_order=0), -2.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=0), -2.0): 0.18393972058572114, (InventoryState(on_hand=0, on_order=0), -2.2333692644293284): 0.08030139707139416},
InventoryState(on_hand=3, on_order=0): {(InventoryState(on_hand=3, on_order=0), -3.0): 0.36787944117144233, (InventoryState(on_hand=2, on_order=0), -3.0): 0.36787944117144233, (InventoryState(on_hand=1, on_order=0), -3.0): 0.18393972058572114, (InventoryState(on_hand=0, on_order=0), -3.2333692644293284): 0.08030139707139416}}#
# ---end study state_reward_probs_mapclass SimpleInventoryMRPFinite(FiniteMarkovRewardProcess[InventoryState]):
def __init__(
self,
capacity: int,
poisson_lambda: float,
holding_cost: float,
stockout_cost: float
):
self.capacity: int = capacity
self.poisson_lambda: float = poisson_lambda
self.holding_cost: float = holding_cost
self.stockout_cost: float = stockout_cost
self.poisson_distr = poisson(poisson_lambda)
super().__init__(self.get_transition_reward_map())
def get_transition_reward_map(self) -> \
Mapping[
InventoryState,
FiniteDistribution[Tuple[InventoryState, float]]
]:
d: Dict[InventoryState, Categorical[Tuple[InventoryState, float]]] = {}
for alpha in range(self.capacity + 1): #alpha 0 to C
for beta in range(self.capacity + 1 - alpha): #beta 0 to C - alpha
state = InventoryState(alpha, beta)
#eq (4.3), (4.4)
ip = state.inventory_position()
beta1 = self.capacity - ip
base_reward = - self.holding_cost*state.on_hand
state_reward_probs_map: Dict[Tuple[InventoryState, float], float] = {
(InventoryState(ip - i, beta1), base_reward):
self.poisson_distr.pmf(i) for i in range(ip) #i 0 to ip-1
}
prob = 1 - self.poisson_distr.cdf(ip - 1) #. changed probability to prob
reward = base_reward - self.stockout_cost*\
(prob*(self.poisson_lambda - ip) +
ip*self.poisson_distr.pmf(ip))
state_reward_probs_map[(InventoryState(0, beta1), reward)] = prob
d[state] = Categorical(state_reward_probs_map)
return dNext, we create an instance of the class SimpleInventoryMRPFinite with: - item_capacity = 3 - item_poisson_lambda = 1.0 - item_holding_cost = 1.0 - item_stockout_cost = 10.0 - item_gamma = 0.9
item_capacity = 3
item_poisson_lambda = 1.0
item_holding_cost = 1.0
item_stockout_cost = 10.0
item_gamma = 0.9
si_mrp = SimpleInventoryMRPFinite(
capacity=item_capacity,
poisson_lambda=item_poisson_lambda,
holding_cost=item_holding_cost,
stockout_cost=item_stockout_cost
)Here is the transition map:
print("Transition Map")
print("--------------")
print(FiniteMarkovProcess(
{s.state: Categorical({s1.state: p for s1, p in v.table().items()})
for s, v in si_mrp.transition_map.items()}
))Transition Map
--------------
From State InventoryState(on_hand=0, on_order=0):
To State InventoryState(on_hand=0, on_order=3) with Probability 1.000
From State InventoryState(on_hand=0, on_order=1):
To State InventoryState(on_hand=1, on_order=2) with Probability 0.368
To State InventoryState(on_hand=0, on_order=2) with Probability 0.632
From State InventoryState(on_hand=0, on_order=2):
To State InventoryState(on_hand=2, on_order=1) with Probability 0.368
To State InventoryState(on_hand=1, on_order=1) with Probability 0.368
To State InventoryState(on_hand=0, on_order=1) with Probability 0.264
From State InventoryState(on_hand=0, on_order=3):
To State InventoryState(on_hand=3, on_order=0) with Probability 0.368
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.184
To State InventoryState(on_hand=0, on_order=0) with Probability 0.080
From State InventoryState(on_hand=1, on_order=0):
To State InventoryState(on_hand=1, on_order=2) with Probability 0.368
To State InventoryState(on_hand=0, on_order=2) with Probability 0.632
From State InventoryState(on_hand=1, on_order=1):
To State InventoryState(on_hand=2, on_order=1) with Probability 0.368
To State InventoryState(on_hand=1, on_order=1) with Probability 0.368
To State InventoryState(on_hand=0, on_order=1) with Probability 0.264
From State InventoryState(on_hand=1, on_order=2):
To State InventoryState(on_hand=3, on_order=0) with Probability 0.368
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.184
To State InventoryState(on_hand=0, on_order=0) with Probability 0.080
From State InventoryState(on_hand=2, on_order=0):
To State InventoryState(on_hand=2, on_order=1) with Probability 0.368
To State InventoryState(on_hand=1, on_order=1) with Probability 0.368
To State InventoryState(on_hand=0, on_order=1) with Probability 0.264
From State InventoryState(on_hand=2, on_order=1):
To State InventoryState(on_hand=3, on_order=0) with Probability 0.368
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.184
To State InventoryState(on_hand=0, on_order=0) with Probability 0.080
From State InventoryState(on_hand=3, on_order=0):
To State InventoryState(on_hand=3, on_order=0) with Probability 0.368
To State InventoryState(on_hand=2, on_order=0) with Probability 0.368
To State InventoryState(on_hand=1, on_order=0) with Probability 0.184
To State InventoryState(on_hand=0, on_order=0) with Probability 0.080
Here is the transition reward map:
print("Transition Reward Map")
print("---------------------")
print(si_mrp)Transition Reward Map
---------------------
From State InventoryState(on_hand=0, on_order=0):
To [State InventoryState(on_hand=0, on_order=3) and Reward -10.000] with Probability 1.000
From State InventoryState(on_hand=0, on_order=1):
To [State InventoryState(on_hand=1, on_order=2) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=2) and Reward -3.679] with Probability 0.632
From State InventoryState(on_hand=0, on_order=2):
To [State InventoryState(on_hand=2, on_order=1) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=1) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -1.036] with Probability 0.264
From State InventoryState(on_hand=0, on_order=3):
To [State InventoryState(on_hand=3, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=2, on_order=0) and Reward -0.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -0.000] with Probability 0.184
To [State InventoryState(on_hand=0, on_order=0) and Reward -0.233] with Probability 0.080
From State InventoryState(on_hand=1, on_order=0):
To [State InventoryState(on_hand=1, on_order=2) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=2) and Reward -4.679] with Probability 0.632
From State InventoryState(on_hand=1, on_order=1):
To [State InventoryState(on_hand=2, on_order=1) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=1) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -2.036] with Probability 0.264
From State InventoryState(on_hand=1, on_order=2):
To [State InventoryState(on_hand=3, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=2, on_order=0) and Reward -1.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -1.000] with Probability 0.184
To [State InventoryState(on_hand=0, on_order=0) and Reward -1.233] with Probability 0.080
From State InventoryState(on_hand=2, on_order=0):
To [State InventoryState(on_hand=2, on_order=1) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=1) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=0, on_order=1) and Reward -3.036] with Probability 0.264
From State InventoryState(on_hand=2, on_order=1):
To [State InventoryState(on_hand=3, on_order=0) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=2, on_order=0) and Reward -2.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -2.000] with Probability 0.184
To [State InventoryState(on_hand=0, on_order=0) and Reward -2.233] with Probability 0.080
From State InventoryState(on_hand=3, on_order=0):
To [State InventoryState(on_hand=3, on_order=0) and Reward -3.000] with Probability 0.368
To [State InventoryState(on_hand=2, on_order=0) and Reward -3.000] with Probability 0.368
To [State InventoryState(on_hand=1, on_order=0) and Reward -3.000] with Probability 0.184
To [State InventoryState(on_hand=0, on_order=0) and Reward -3.233] with Probability 0.080
The following diagram shows the states for the case when the capacity is 3. The transition probabilities and rewards are also shown. The rewards are shown after the ‘/’ character on the transitions.
si_mrp.generate_image()
Here is the stationary distribution of states:
print("Stationary Distribution")
print("-----------------------")
si_mrp.display_stationary_distribution()
print()Stationary Distribution
-----------------------
{InventoryState(on_hand=1, on_order=0): 0.071,
InventoryState(on_hand=0, on_order=3): 0.031,
InventoryState(on_hand=1, on_order=2): 0.065,
InventoryState(on_hand=2, on_order=0): 0.143,
InventoryState(on_hand=2, on_order=1): 0.148,
InventoryState(on_hand=3, on_order=0): 0.143,
InventoryState(on_hand=0, on_order=0): 0.031,
InventoryState(on_hand=0, on_order=1): 0.107,
InventoryState(on_hand=0, on_order=2): 0.112,
InventoryState(on_hand=1, on_order=1): 0.148}
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import style
# style.use('ggplot')
import matplotlib.ticker as tickerfig = plt.figure(figsize=(15, 10))
ax1 = fig.add_subplot(111, projection='3d')
list_of_tuples = [(el[0].on_hand, el[0].on_order, el[1]) for el in si_mrp.get_stationary_distribution()]; #list_of_tuples
x3, y3, dz = [list(tup) for tup in zip(*list_of_tuples)]; x3, y3, dz
# x3 = [0, 1, 2, 1, 0, 0]
# y3 = [0, 1, 0, 0, 2, 1]
n = len(dz)
z3 = np.zeros(n)
dx = np.ones(n)
dy = np.ones(n)
# dz = [0.117, 0.162, 0.162, 0.162, 0.117, 0.279]
ax1.bar3d(x3, y3, z3, dx, dy, dz)
ax1.set_xticks([e+0.5 for e in range(n - 1)])
ax1.set_xticklabels(range(n - 1))
ax1.set_xlabel(r'on-hand inventory, $\alpha$', fontsize=15)
ax1.set_yticks([e+0.5 for e in range(n - 1)])
ax1.set_yticklabels(range(n - 1))
ax1.set_ylabel(r'on-order inventory, $\beta$', fontsize=15)
ax1.set_zlabel(r'probability, $\pi$', fontsize=15)
ax1.set_title('Stationary Distribution of States', fontsize=20)
ax1.view_init(ax1.elev + 20, -200)
# ax.elev + 10, -160
plt.show()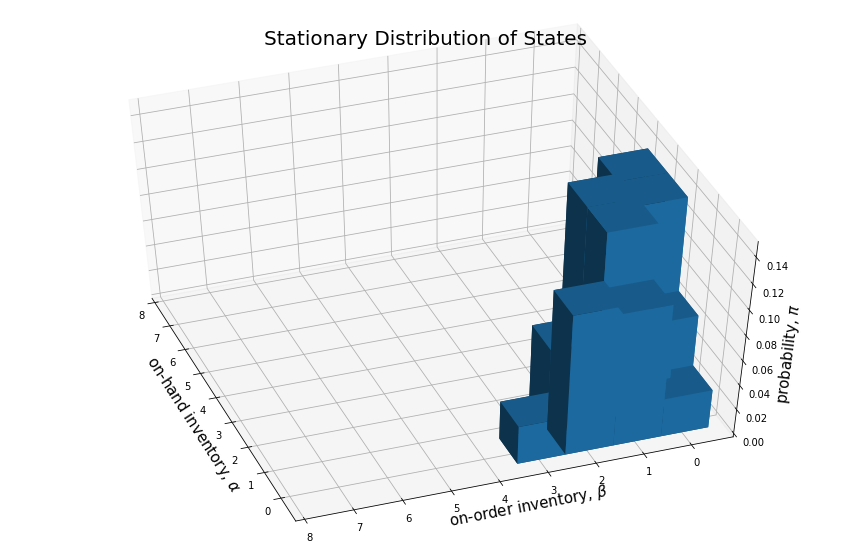
Next we visualize how each of the state variables, \(\alpha\) and \(\beta\), evolve over time.
#
# use stationary distribution for a start state distribution
ssd = si_mrp.get_stationary_distribution(); ssd{InventoryState(on_hand=0, on_order=0): 0.031120936942690133, InventoryState(on_hand=0, on_order=1): 0.10660457196659985, InventoryState(on_hand=0, on_order=2): 0.11244837477707609, InventoryState(on_hand=0, on_order=3): 0.03112093694269009, InventoryState(on_hand=1, on_order=0): 0.07128613765604674, InventoryState(on_hand=1, on_order=1): 0.1484160781225697, InventoryState(on_hand=1, on_order=2): 0.0654423348455706, InventoryState(on_hand=2, on_order=0): 0.14257227531209354, InventoryState(on_hand=2, on_order=1): 0.1484160781225697, InventoryState(on_hand=3, on_order=0): 0.14257227531209354}#
# create a generator for the states of a trace
gen = si_mrp.traces(start_state_distribution=ssd); gen<generator object MarkovProcess.traces at 0x7f76c771cdd0>#
# get a trace
a_trace = [list(next(gen)) for i in range(50)]; a_trace[[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=2, on_order=1)],
[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=1, on_order=2)],
[InventoryState(on_hand=1, on_order=0)],
[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=1, on_order=0)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=1, on_order=1)],
[InventoryState(on_hand=1, on_order=0)],
[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=2, on_order=1)],
[InventoryState(on_hand=0, on_order=1)],
[InventoryState(on_hand=1, on_order=0)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=1, on_order=1)],
[InventoryState(on_hand=0, on_order=1)],
[InventoryState(on_hand=2, on_order=1)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=0, on_order=0)],
[InventoryState(on_hand=2, on_order=0)],
[InventoryState(on_hand=0, on_order=3)],
[InventoryState(on_hand=2, on_order=0)],
[InventoryState(on_hand=2, on_order=0)],
[InventoryState(on_hand=2, on_order=0)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=2, on_order=1)],
[InventoryState(on_hand=1, on_order=1)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=0, on_order=1)],
[InventoryState(on_hand=1, on_order=1)],
[InventoryState(on_hand=2, on_order=1)],
[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=0, on_order=3)],
[InventoryState(on_hand=0, on_order=3)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=3, on_order=0)],
[InventoryState(on_hand=1, on_order=2)],
[InventoryState(on_hand=0, on_order=1)],
[InventoryState(on_hand=0, on_order=1)],
[InventoryState(on_hand=2, on_order=1)],
[InventoryState(on_hand=0, on_order=1)],
[InventoryState(on_hand=2, on_order=0)],
[InventoryState(on_hand=0, on_order=2)],
[InventoryState(on_hand=2, on_order=0)]]#
# get a list of numeric tuples from the trace
list_of_tuples = [(state[0].on_hand, state[0].on_order) for state in a_trace]; list_of_tuples[(0, 2),
(2, 1),
(0, 2),
(3, 0),
(1, 2),
(1, 0),
(0, 2),
(3, 0),
(1, 0),
(3, 0),
(1, 1),
(1, 0),
(0, 2),
(0, 2),
(3, 0),
(2, 1),
(0, 1),
(1, 0),
(3, 0),
(3, 0),
(1, 1),
(0, 1),
(2, 1),
(3, 0),
(0, 0),
(2, 0),
(0, 3),
(2, 0),
(2, 0),
(2, 0),
(3, 0),
(2, 1),
(1, 1),
(3, 0),
(0, 1),
(1, 1),
(2, 1),
(0, 2),
(0, 3),
(0, 3),
(3, 0),
(3, 0),
(1, 2),
(0, 1),
(0, 1),
(2, 1),
(0, 1),
(2, 0),
(0, 2),
(2, 0)]#
# collect each state variable's values in a list
alpha, beta = [list(tup) for tup in zip(*list_of_tuples)]; #alpha, betan_steps = len(alpha); n_steps #number of steps50figure, axis = plt.subplots(2, 1)
figure.set_figwidth(15)
figure.set_figheight(8)
axis[0].step(range(n_steps), alpha)
axis[0].set_ylim([0, 4])
axis[0].set_title(r"state variable $\alpha$")
axis[1].step(range(n_steps), beta)
axis[1].set_ylim([0, 4])
axis[1].set_title(r"state variable $\beta$");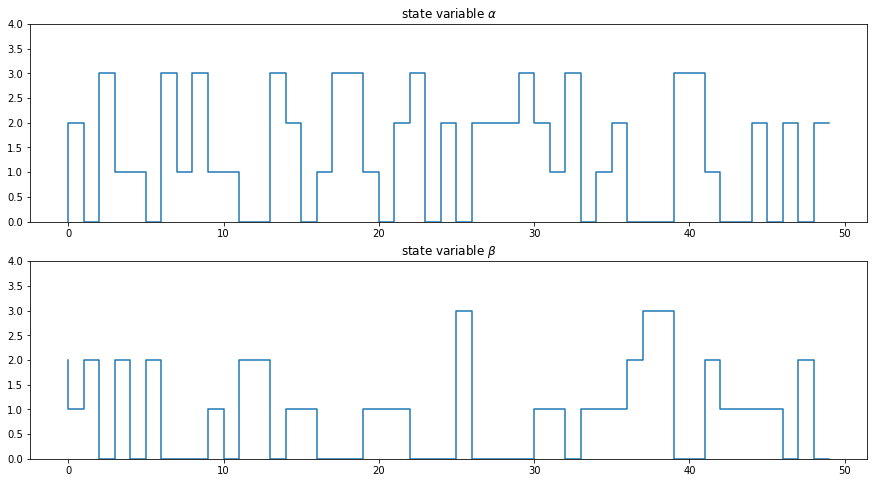
Here is a representation of the reward function:
print("Reward Function")
print("---------------")
si_mrp.display_reward_function()
print()Reward Function
---------------
{NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -0.274,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -2.325,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -10.0,
NonTerminal(state=InventoryState(on_hand=0, on_order=3)): -0.019,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -3.325,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -1.274,
NonTerminal(state=InventoryState(on_hand=1, on_order=2)): -1.019,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -2.274,
NonTerminal(state=InventoryState(on_hand=2, on_order=1)): -2.019,
NonTerminal(state=InventoryState(on_hand=3, on_order=0)): -3.019}
fig = plt.figure(figsize=(15, 10))
ax1 = fig.add_subplot(111, projection='3d')
rewards = {si_mrp.non_terminal_states[i]: round(r, 3) for i, r in enumerate(si_mrp.reward_function_vec)}
list_of_tuples = [(k.state.on_hand, k.state.on_order, -v) for k,v in rewards.items()]
x3, y3, dz = [list(tup) for tup in zip(*list_of_tuples)]; x3, y3, dz
# x3 = [0, 1, 2, 1, 0, 0]
# y3 = [0, 1, 0, 0, 2, 1]
n = len(dz)
z3 = np.zeros(n)
dx = np.ones(n)
dy = np.ones(n)
# dz = [0.117, 0.162, 0.162, 0.162, 0.117, 0.279]
ax1.bar3d(x3, y3, z3, dx, dy, dz)
ax1.set_xticks([e+0.5 for e in range(n - 1)])
ax1.set_xticklabels(range(n - 1))
ax1.set_xlabel(r'on-hand inventory, $\alpha$', fontsize=15)
ax1.set_yticks([e+0.5 for e in range(n - 1)])
ax1.set_yticklabels(range(n - 1))
ax1.set_ylabel(r'on-order inventory, $\beta$', fontsize=15)
ax1.set_zlabel(r'cost, $-R$', fontsize=15)
ax1.set_title('Negative of the Reward Function (Cost)', fontsize=20)
ax1.view_init(ax1.elev + 20, -200)
# ax.elev + 10, -160
plt.show()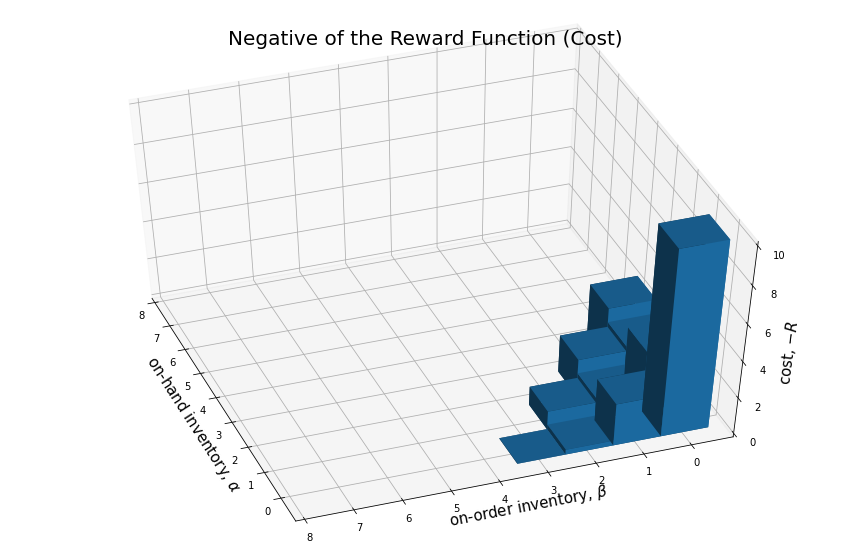
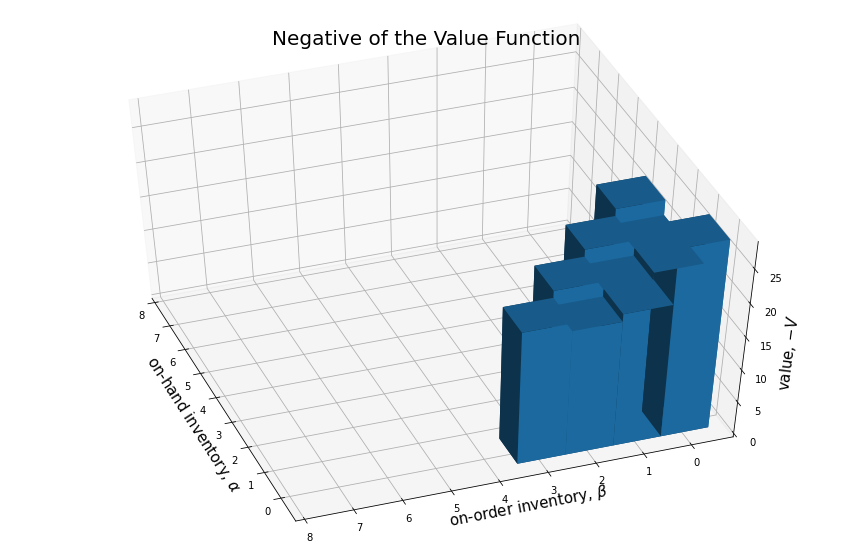
Here is a representation of the value function:
print("Value Function")
print("--------------")
si_mrp.display_value_function(gamma=item_gamma)
print()Value Function
--------------
{NonTerminal(state=InventoryState(on_hand=0, on_order=2)): -19.15,
NonTerminal(state=InventoryState(on_hand=0, on_order=1)): -20.273,
NonTerminal(state=InventoryState(on_hand=0, on_order=0)): -28.271,
NonTerminal(state=InventoryState(on_hand=0, on_order=3)): -20.301,
NonTerminal(state=InventoryState(on_hand=1, on_order=0)): -21.273,
NonTerminal(state=InventoryState(on_hand=1, on_order=1)): -20.15,
NonTerminal(state=InventoryState(on_hand=1, on_order=2)): -21.301,
NonTerminal(state=InventoryState(on_hand=2, on_order=0)): -21.15,
NonTerminal(state=InventoryState(on_hand=2, on_order=1)): -22.301,
NonTerminal(state=InventoryState(on_hand=3, on_order=0)): -23.301}
fig = plt.figure(figsize=(15, 10))
ax1 = fig.add_subplot(111, projection='3d')
values = {si_mrp.non_terminal_states[i]: round(v, 3) for i, v in enumerate(si_mrp.get_value_function_vec(item_gamma))}
list_of_tuples = [(k.state.on_hand, k.state.on_order, -v) for k,v in values.items()]
x3, y3, dz = [list(tup) for tup in zip(*list_of_tuples)]; x3, y3, dz
# x3 = [0, 1, 2, 1, 0, 0]
# y3 = [0, 1, 0, 0, 2, 1]
n = len(dz)
z3 = np.zeros(n)
dx = np.ones(n)
dy = np.ones(n)
# dz = [0.117, 0.162, 0.162, 0.162, 0.117, 0.279]
ax1.bar3d(x3, y3, z3, dx, dy, dz)
ax1.set_xticks([e+0.5 for e in range(n - 1)])
ax1.set_xticklabels(range(n - 1))
ax1.set_xlabel(r'on-hand inventory, $\alpha$', fontsize=15)
ax1.set_yticks([e+0.5 for e in range(n - 1)])
ax1.set_yticklabels(range(n - 1))
ax1.set_ylabel(r'on-order inventory, $\beta$', fontsize=15)
ax1.set_zlabel(r'value, $-V$', fontsize=15)
ax1.set_title('Negative of the Value Function', fontsize=20)
ax1.view_init(ax1.elev + 20, -200)
# ax.elev + 10, -160
plt.show()