The overall structure of this project and report follows the traditional CRISP-DM format. However, instead of the CRISP-DM’S “4 Modeling” section, we inserted the “6 step modeling process” of Dr. Warren Powell in section 4 of this document. Dr Powell’s unified framework shows great promise for unifying the formalisms of at least a dozen different fields. Using his framework enables easier access to thinking patterns in these other fields that might be beneficial and informative to the sequential decision problem at hand. Traditionally, this kind of problem would be approached from the reinforcement learning perspective. However, using Dr. Powell’s wider and more comprehensive perspective almost certainly provides additional value.
In order to make a strong mapping between the code in this notebook and the mathematics in the Powell Unified Framework (PUF), we follow the following convention for naming Python identifier names:
Superscripts
variable names have a double underscore to indicate a superscript
\(X^{\pi}\): has code X__pi, is read X pi
Subscripts
variable names have a single underscore to indicate a subscript
\(S_t\): has code S_t, is read ‘S at t’
\(M^{Spend}_t\) has code M__Spend_t which is read: “MSpend at t”
Arguments
collection variable names may have argument information added
\(X^{\pi}(S_t)\): has code X__piIS_tI, is read ‘X pi in S at t’
the surrounding I’s are used to imitate the parentheses around the argument
Next time/iteration
variable names that indicate one step in the future are quite common
\(R_{t+1}\): has code R_tt1, is read ‘R at t+1’
\(R^{n+1}\): has code R__nt1, is read ‘R at n+1’
Rewards
State-independent terminal reward and cumulative reward
\(F\): has code F for terminal reward
\(\sum_{n}F\): has code cumF for cumulative reward
State-dependent terminal reward and cumulative reward
\(C\): has code C for terminal reward
\(\sum_{t}C\): has code cumC for cumulative reward
Vectors where components use different names
\(S_t(R_t, p_t)\): has code S_t.R_t and S_t.p_t, is read ‘S at t in R at t, and, S at t in p at t’
the code implementation is by means of a named tuple
self.State = namedtuple('State', SVarNames) for the ‘class’ of the vector
self.S_t for the ‘instance’ of the vector
Vectors where components reuse names
\(x_t(x_{t,GB}, x_{t,BL})\): has code x_t.x_t_GB and x_t.x_t_BL, is read ‘x at t in x at t for GB, and, x at t in x at t for BL’
the code implementation is by means of a named tuple
self.Decision = namedtuple('Decision', xVarNames) for the ‘class’ of the vector
self.x_t for the ‘instance’ of the vector
Use of mixed-case variable names
to reduce confusion, sometimes the use of mixed-case variable names are preferred (even though it is not a best practice in the Python community), reserving the use of underscores and double underscores for math-related variables
1 BUSINESS UNDERSTANDING
Managing the supply of blood is a crucial aspect of healthcare operations at hospitals. The availability of safe and adequate blood plays a vital role in ensuring the successful treatment of patients undergoing surgeries, trauma cases, and various medical conditions. Hospitals employ efficient blood supply management systems to procure, store, distribute, and utilize this life-saving resource effectively.
The management of blood supplies involves careful coordination between multiple stakeholders, including healthcare professionals, blood banks, laboratories, and administrative personnel. By implementing robust procedures and protocols, hospitals aim to optimize the utilization of blood products while maintaining high standards of safety and quality.
One of the primary objectives of blood supply management is to maintain an adequate inventory of blood products. This requires forecasting the demand for different blood types and components based on historical data, patient demographics, and anticipated surgical procedures. Hospitals collaborate closely with blood banks and engage in regular communication to ensure a steady supply of blood that meets the specific needs of their patients.
To ensure the safety and integrity of the blood supply, hospitals adhere to strict regulatory guidelines and quality assurance practices. This includes rigorous screening of blood donors for infectious diseases, compatibility testing, and proper storage and transportation of blood products. Hospitals also maintain comprehensive records and traceability systems to monitor the usage, expiration dates, and disposal of blood units.
Efficient distribution and utilization of blood are essential to prevent wastage and optimize resources. Hospital blood banks work in close coordination with various departments, such as operating rooms, emergency departments, and intensive care units, to monitor blood usage patterns, prioritize cases, and respond to urgent requests promptly. Implementing transfusion guidelines and protocols further ensures the appropriate use of blood products, reducing the risk of unnecessary transfusions and improving patient outcomes.
In conclusion, effective management of blood supplies is paramount in the provision of quality healthcare services at hospitals. By implementing robust systems and protocols, hospitals can ensure the availability of safe and adequate blood products, improve patient care, and contribute to the overall well-being of the communities they serve.
In this project the client had a need to be convinced of the benefits of a formal resource assignment/allocation approach for their need (which was a sensitive military situation). The current use case was chosen as an appropriate example that could be adapted for a solution eventually. Their need was addressed in this series of POCs. The example explored (but also modified in many ways) in this report comes from Dr. Warren Powell (formerly at Princeton). It was chosen as a template to create a POC for the client.
The original code for this example can be found here.
2 DATA UNDERSTANDING
# import pdbimport randomfrom collections import namedtuple, defaultdictimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport timeimport pickleimport matplotlib as mplimport cvxoptimport os.pathimport os# from certifi.core import wherepd.options.display.float_format ='{:,.4f}'.formatpd.set_option('display.max_columns', None)pd.set_option('display.max_rows', None)pd.set_option('display.max_colwidth', None)! python --version
Python 3.10.12
First, we setup all the parameters of the inventory system-under-steer (SUS):
def printParams(params):print(params)def loadParams(filename): parDf = pd.read_excel(filename, sheet_name ='Parameters') parDict = parDf.set_index('Index').T.to_dict('list') params = {key:v for key, value in parDict.items() for v in value} params['PRINT'] =False params['PRINT_ALL'] =False params['OUTPUT_FILENAME'] ='DetailedOutput.xlsx' params['SHOW_PLOTS']=False#Set here bloodtypes and substitutions that are allowed params['Bloodtypes'] = ['AB+', 'AB-', 'A+', 'A-','B+', 'B-', 'O+', 'O-'] params['NUM_BLD_TYPES'] =len(params['Bloodtypes']) b = [(x,y) for x in params['Bloodtypes'] for y in params['Bloodtypes']] f = [False]*(len(params['Bloodtypes'])*len(params['Bloodtypes'])) c = {k:v for k,v inzip(b, f)}#In case we want to allow subs c[('AB+', 'AB+')] =True c[('AB-', 'AB+')] =True c[('AB-', 'AB-')] =True c[('A+', 'AB+')] =True c[('A+', 'A+')] =True c[('A-', 'AB+')] =True c[('A-', 'AB-')] =True c[('A-', 'A+')] =True c[('A-', 'A-')] =True c[('B+', 'AB+')] =True c[('B+', 'B+')] =True c[('B-', 'AB+')] =True c[('B-', 'AB-')] =True c[('B-', 'B+')] =True c[('B-', 'B-')] =True c[('O+', 'AB+')] =True c[('O+', 'A+')] =True c[('O+', 'B+')] =True c[('O+', 'O+')] =True c[('O-', 'AB+')] =True c[('O-', 'A+')] =True c[('O-', 'B+')] =True c[('O-', 'O+')] =True c[('O-', 'AB-')] =True c[('O-', 'A-')] =True c[('O-', 'B-')] =True c[('O-', 'O-')] =True params['SubMatrix'] = c #. Table 14.1# Set here max age of blood params['MAX_AGE'] =3 params['Ages'] =list(range(params['MAX_AGE'])) params['NUM_BLD_NODES'] = params['NUM_BLD_TYPES']*params['MAX_AGE']# Set here blood demand nodes params['Surgerytypes'] = ['Urgent', 'Elective'] params['Substitution'] = [True] params['NUM_SUR_TYPES'] =len(params['Surgerytypes']) params['NUM_DEM_NODES'] = params['NUM_BLD_TYPES']*params['NUM_SUR_TYPES']*len(params['Substitution'])# Solver params params['SLOPE_CAPAC_LAST'] =100000 params['MIN_CONST'] =0.01 params['EPSILON'] =0.001# Set here number of iterations and time periods params['NUM_TRAINNING_ITER'] =int(params['NUM_TRAINNING_ITER']) params['NUM_TESTING_ITER'] =int(params['NUM_TESTING_ITER']) params['NUM_ITER'] =int(params['NUM_TESTING_ITER'] + params['NUM_TRAINNING_ITER']) #Total number of iterations params['MAX_TIME'] =int(15) params['Times'] =list(range(params['MAX_TIME']))# Set here VFA parameters# - If USE_VFA is set to True we are going to use VFA's when making the decisions -# - If USE_VFA is set to False, it means that a MYOPIC policy is going to be considered and all the parameters#related to VFA's (such as DISCOUNT_FACTOR, LOAD_VFA, SAVE_VFA, STEPSIZE_RULE, PROJECTION_ALGO,#IS_PERTUB,SEED_TRAINING are ignored)#params['USE_VFA'] = True #If set to True we are going to use VFA's when making the decisions - False means a MYOPIC policy params['DISCOUNT_FACTOR'] =0.95 params['LOAD_VFA'] =False#If set to True we are going to initialize the VFA's with VFA's from previous runs - instead of all zeros params['NAME_LOAD_VFA_PICKLE'] ="Bld_Net10_P_C_Subs.pickle" params['SAVE_VFA'] =False#If we want to save/update the VFA's to be used in future runs params['NAME_SAVE_VFA_PICKLE'] ="Bld_Net10_P_C_Subs.pickle"# Set here the stepsize parameters params['STEPSIZE_RULE'] ='C'#Possible values: 'C' for Constant or 'A' for AdaGrad params['NUM_ITER_STEP_ONE'] =0#Number of iterations with stepsize one# Set here the CONSTANT stepsize parameter (not considered if AdaGrad stepsize is being used)#params['ALPHA'] = 0.2 #the stepsize for the other iterations#Set here the AdaGrad stepsize parameters (not considered if Constant stepsize is being used) params['STEP_EPS'] =0.00000001 params['ETA'] =1# Set here the algorithm that should be use for projection back the slopes that break concavity# Possible algorithms for projecting back the slopes to enforce concavity are:# - 'Avg' to average the slopes that break concavity; \# - 'Copy' to copy the newly updated vbar to the slopes that break concavity# - 'Up' to update the slopes that break concavity with the current stepsize and vhat params['PROJECTION_ALGO'] ='Up'#Perturb the solution during training iterations for exploration params['IS_PERTUB'] =False params['LAMBDA_PERTUB'] =1 params['PERTUB_GEN'] = np.random.RandomState(13247)# Set here one step contribution function parameters - BONUSES and PENALTIES params['AGE_BONUS'] = np.zeros(params['MAX_AGE'])# params['AGE_BONUS'] = [2]*MAX_AGE# params['AGE_BONUS'] = list(reversed(list(range(0,MAX_AGE))))# params['AGE_BONUS'] = list(range(0,MAX_AGE))# params['AGE_BONUS'] = [0.5, 2] #It has to be the same length as MAX_AGE params['INFEASIABLE_SUBSTITUTION_PENALTY'] =-50 params['NO_SUBSTITUTION_BONUS'] =5 params['URGENT_DEMAND_BONUS'] =30 params['ELECTIVE_DEMAND_BONUS'] =5 params['DISCARD_BLOOD_PENALTY'] =-10#applied for the oldest age in the holding/vfa arcs# Set here Random Seeds params['SEED_TRAINING'] =1090377 params['SEED_TESTING'] =8090373#Set here the distribution for demand/donation/initial inventory params['SAMPLING_DIST'] ='P'#Possible values: 'P' for Poisson or 'U' for uniform params['POISSON_FACTOR'] =1# Set here max demand by blood type (when 'U'niform dist) or mean demand (when 'P'oisson dist) params['DEFAULT_VALUE_DIST'] =20 d = [params['DEFAULT_VALUE_DIST']]*params['NUM_BLD_TYPES'] params['MAX_DEM_BY_BLOOD'] = {k:v for k,v inzip(params['Bloodtypes'], d)} params['MAX_DON_BY_BLOOD'] = {k:v for k,v inzip(params['Bloodtypes'], d)}# Set here demand by blood type (for blood types that are different than the params['DEFAULT_VALUE_DIST']) params['MAX_DEM_BY_BLOOD']['AB+'] =3 params['MAX_DEM_BY_BLOOD']['B+'] =9 params['MAX_DEM_BY_BLOOD']['O+'] =18 params['MAX_DEM_BY_BLOOD']['B-'] =2 params['MAX_DEM_BY_BLOOD']['AB-'] =3 params['MAX_DEM_BY_BLOOD']['A-'] =6 params['MAX_DEM_BY_BLOOD']['O-'] =7 params['MAX_DEM_BY_BLOOD']['A+'] =14 params['MAX_DEM_BY_BLOOD']['AB+'] =0 params['MAX_DEM_BY_BLOOD']['B+'] =0 params['MAX_DEM_BY_BLOOD']['O+'] =0 params['MAX_DEM_BY_BLOOD']['B-'] =0 params['MAX_DEM_BY_BLOOD']['AB-'] =0 params['MAX_DEM_BY_BLOOD']['A-'] =10 params['MAX_DEM_BY_BLOOD']['O-'] =10 params['MAX_DEM_BY_BLOOD']['A+'] =0 params['MAX_DEM_BY_BLOOD']['AB+'] =3 params['MAX_DEM_BY_BLOOD']['B+'] =9 params['MAX_DEM_BY_BLOOD']['O+'] =18 params['MAX_DEM_BY_BLOOD']['B-'] =2 params['MAX_DEM_BY_BLOOD']['AB-'] =3 params['MAX_DEM_BY_BLOOD']['A-'] =6 params['MAX_DEM_BY_BLOOD']['O-'] =7 params['MAX_DEM_BY_BLOOD']['A+'] =14#params['DEFAULT_VALUE_DIST']# Set here donation by blood type (for blood types that are different than the params['DEFAULT_VALUE_DIST']) params['MAX_DON_BY_BLOOD']['AB+'] =0 params['MAX_DON_BY_BLOOD']['B+'] =0 params['MAX_DON_BY_BLOOD']['O+'] =0 params['MAX_DON_BY_BLOOD']['B-'] =0 params['MAX_DON_BY_BLOOD']['AB-'] =0 params['MAX_DON_BY_BLOOD']['A-'] =10 params['MAX_DON_BY_BLOOD']['O-'] =10 params['MAX_DON_BY_BLOOD']['A+'] =0 params['MAX_DON_BY_BLOOD']['AB+'] =3 params['MAX_DON_BY_BLOOD']['B+'] =9 params['MAX_DON_BY_BLOOD']['O+'] =18 params['MAX_DON_BY_BLOOD']['B-'] =2 params['MAX_DON_BY_BLOOD']['AB-'] =3 params['MAX_DON_BY_BLOOD']['A-'] =6 params['MAX_DON_BY_BLOOD']['O-'] =7 params['MAX_DON_BY_BLOOD']['A+'] =14#The default weights to split the demand of a blood type is equal weights. The only requirement is that each#weight is positive and they add up to 1.#Default params['SURGERYTYPES_PROP'] = {k:1/len(params['Surgerytypes']) for k in params['Surgerytypes']} params['SUBSTITUTION_PROP'] = {k:1/len(params['Substitution']) for k in params['Substitution']}# Set here the weights for each surgery type (if different than the default) params['SURGERYTYPES_PROP']['Urgent'] =1/2 params['SURGERYTYPES_PROP']['Elective'] =1- params['SURGERYTYPES_PROP']['Urgent']# Set here the weights for each substitution type (if different than the default) params['SUBSTITUTION_PROP'][True] =1#params['SUBSTITUTION_PROP'][False] = 1 - params['SUBSTITUTION_PROP'][True]#Set here random surge parameters#params['TIME_PERIODS_SURGE'] = set([4,8,10,12,14]) params['TIME_PERIODS_SURGE'] =set([3,6,10,13])#SURGE_PROB = 0.7 params['SURGE_FACTOR'] =6#The surge demand is always going to be poisson with mean SURGE_FACTOR*params['MAX_DEM_BY_BLOOD'], even if the regular demand distribution is Uniform#Set here the weights for the utility function - urgent coverage, elective coverage, proportion of blood discarded params['WEIGHT_URGENT']=10 params['WEIGHT_ELECTIVE']=1 params['WEIGHT_DISCARDED']=3if (params['SAMPLING_DIST'] =='P'): params['MAX_DEM_BY_BLOOD'] = {k: int(v * params['POISSON_FACTOR']) for k, v in params['MAX_DEM_BY_BLOOD'].items()} params['MAX_DON_BY_BLOOD'] = {k: int(v * params['POISSON_FACTOR']) for k, v in params['MAX_DON_BY_BLOOD'].items()} params['AVG_TOTAL_DEMAND'] =sum(params['MAX_DEM_BY_BLOOD'].values()) params['AVG_TOTAL_SUPPLY'] =sum(params['MAX_DON_BY_BLOOD'].values()) params['NUM_PARALLEL_LINKS'] =int(params['MAX_AGE']/2*max(params['MAX_DON_BY_BLOOD'].values()))#print("Exogenous info dist: Poisson ")else: params['AVG_TOTAL_DEMAND'] =sum(params['MAX_DEM_BY_BLOOD'].values())/2 params['AVG_TOTAL_SUPPLY'] =sum(params['MAX_DON_BY_BLOOD'].values())/2 params['NUM_PARALLEL_LINKS'] =int(params['MAX_AGE']/2*max(params['MAX_DON_BY_BLOOD'].values()))#print("Exogenous info dist: Uniform")#Checking if MYOPIC policyifnot params['USE_VFA']: params['ALPHA'] =0 params['LOAD_VFA'] =False params['SAVE_VFA'] =False params['NUM_TRAINNING_ITER'] =0 params['NUM_ITER'] = params['NUM_TESTING_ITER'] params['NUM_PARALLEL_LINKS'] =1print("Printing params dict\n") printParams(params)if (params['SAMPLING_DIST'] =='P'):print("Exogenous info dist: Poisson ")else:print("Exogenous info dist: Uniform")print("Demand parameters by blood type ",params['MAX_DEM_BY_BLOOD'])print("There are ",params['NUM_SUR_TYPES'] *len(params['Substitution'])," demand nodes for each blood type")print("Weights SURGERYTYPES_PROP ",params['SURGERYTYPES_PROP'])print("Weights SUBSTITUTION_PROP ",params['SUBSTITUTION_PROP'])print("Donation parameters by blood type ",params['MAX_DON_BY_BLOOD'])print("AVG TOTAL DEMAND ",params['AVG_TOTAL_DEMAND'])print("AVG TOTAL SUPPLY ",params['AVG_TOTAL_SUPPLY'])print("NUM PARALLEL LINKS ",params['NUM_PARALLEL_LINKS'])print("Possible surge time periods ", params['TIME_PERIODS_SURGE'])print("SURGE_PROB ", params['SURGE_PROB'], " and SURGE_FACTOR ", params['SURGE_FACTOR'])return params# params = loadParams(f'{base_dir}/Parameters.xlsx')PARS = loadParams(f'{base_dir}/Parameters.xlsx')
In order to capture the vector attribute values in variable names, we replace all ‘+’ characters for bloodtypes by a ‘p’. Similarly, all ‘-’ characters are replaced by ‘n’.
# modify params['SubMatrix'] to have names with '_'mySubMatrix = {}for kv in PARS['SubMatrix'].items():# print(kv) mySubMatrix['_'.join(kv[0]).replace('+', 'p').replace('-', 'n')] = kv[1]# mySubMatrix
# modify params['MAX_DON_BY_BLOOD'] to have names with '_'myMAX_DON_BY_BLOOD = {}for kv in PARS['MAX_DON_BY_BLOOD'].items():# print(kv[0].replace('+', 'p').replace('-', 'n')) myMAX_DON_BY_BLOOD[kv[0].replace('+', 'p').replace('-', 'n')] = kv[1]myMAX_DON_BY_BLOOD
# modify params['SUBSTITUTION_PROP'] to have names with '_'mySUBSTITUTION_PROP = {}for kv in PARS['SUBSTITUTION_PROP'].items():# print(kv[0].replace('+', 'p').replace('-', 'n')) mySUBSTITUTION_PROP[str(kv[0])] = kv[1]mySUBSTITUTION_PROP
{'True': 1}
# modify params['Bloodtypes'] to have names with '_'myBloodtypes = [el.replace('+','p').replace('-','n') for el in PARS['Bloodtypes']]myBloodtypes
SNAMES = ['R_t', # BloodInventory'Rhold_t', # Held BloodInventory'Dh_t', # Demand'Rh_t', # Donations]xNAMES = ['x_t']# all possible attribute vectorsaNAMES = []for i in PARS['Bloodtypes']:for j in PARS['Ages']: an ='_'.join([str(i),str(j)]).replace('+', 'p').replace('-', 'n') aNAMES.append(an)print(f'{len(aNAMES)=}')print(aNAMES[:10])# all possible demand vectorsbNAMES = []for i in PARS['Bloodtypes']:for j in PARS['Surgerytypes']:for k in PARS['Substitution']: bn ='_'.join([str(i),str(j),str(k)]).replace('+', 'p').replace('-', 'n') bNAMES.append(bn)print(f'{len(bNAMES)=}')print(bNAMES[:10])abNAMES = []for a in aNAMES:for b in bNAMES: abn = (a +'___'+ b) abNAMES.append(abn)print(f'{len(abNAMES)=}')print(abNAMES[:3])abNAMES[-10:]#add abNAMES to hold bloodabNAMES_HOLD = []for a in aNAMES: a0,a1 = a.split('_') a_hold ='_'.join([a0, str(int(a1)+1)]) abName_hold = a +'___'+ a_hold abNAMES_HOLD.append(abName_hold)print(f'{len(abNAMES_HOLD)=}')print(abNAMES_HOLD)# abNAMES = abNAMES + abNAMES_HOLDabNAMES_EXP = abNAMES + abNAMES_HOLD #expanded abNAMESprint(f'{len(abNAMES_EXP)=}')print(abNAMES_EXP[:3])abNAMES_EXP[-10:]
def contribution(params, aName, bName): a = aName.split('_') b = bName.split('_')if ( #substutition is not allowedbool(b[2]) ==Falseand a[0] != b[0]) or\ (bool(b[2]) ==Trueand mySubMatrix['_'.join([a[0], b[0]])] ==False): value = params['INFEASIABLE_SUBSTITUTION_PENALTY']else:# start giving a bonus depending on the age of the blood value =0# no substitutionif a[0] == b[0]: value += params['NO_SUBSTITUTION_BONUS']# filling urgent demandif b[1] =='Urgent': value += params['URGENT_DEMAND_BONUS']# filling elective demandelse: value += params['ELECTIVE_DEMAND_BONUS']if b[1] =='Elective': value += params['BLOOD_FOR_ELECTIVE_PENALTY']return(value)ContribMatrix = {} #seems to play same role as the demweights of demedgesfor an in aNAMES: demContribs = {}for bn in bNAMES: demContribs[bn] = contribution(PARS, an, bn) ContribMatrix[an] = demContribs
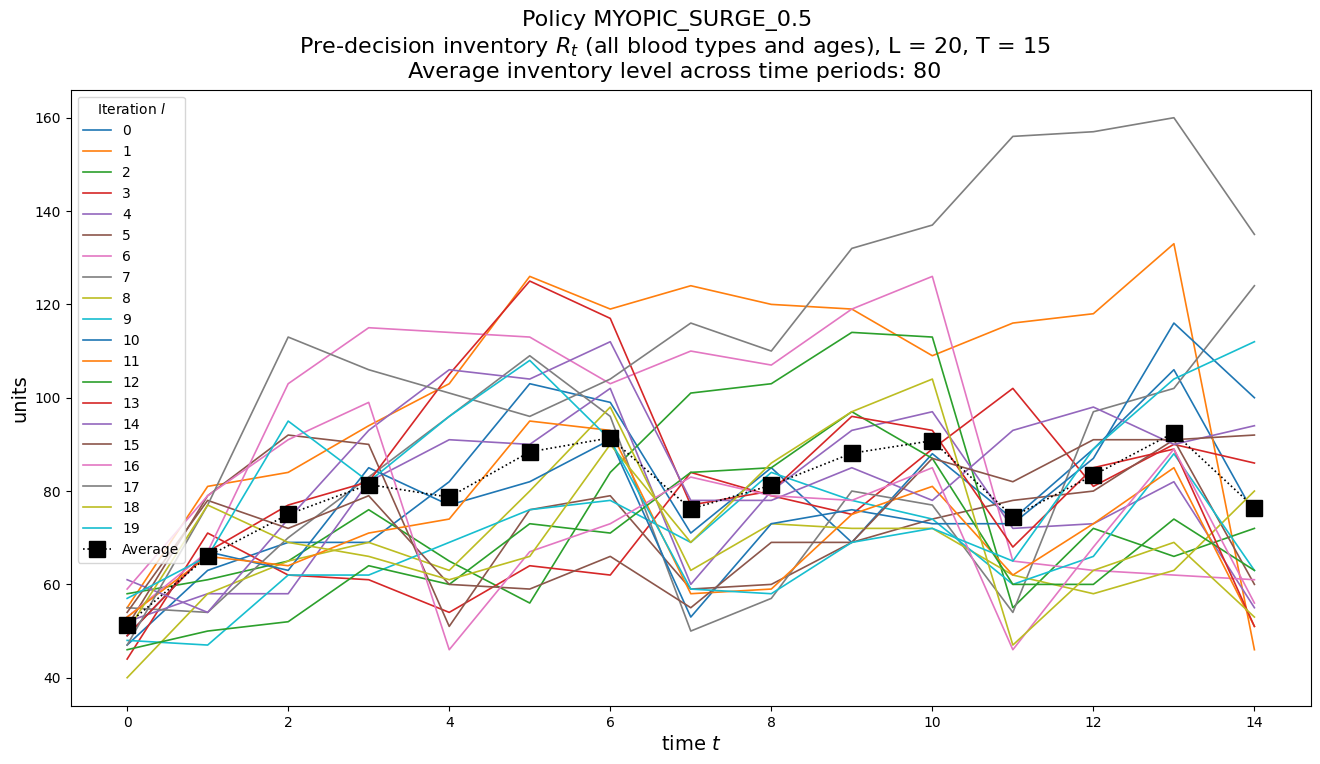
L = PARS['NUM_ITER'] #number of sample-pathsT = PARS['MAX_TIME'] #number of transitions/steps in each sample-pathprint(f'{L=}, {T=}')T__sim =15#50 #100
L=20, T=15
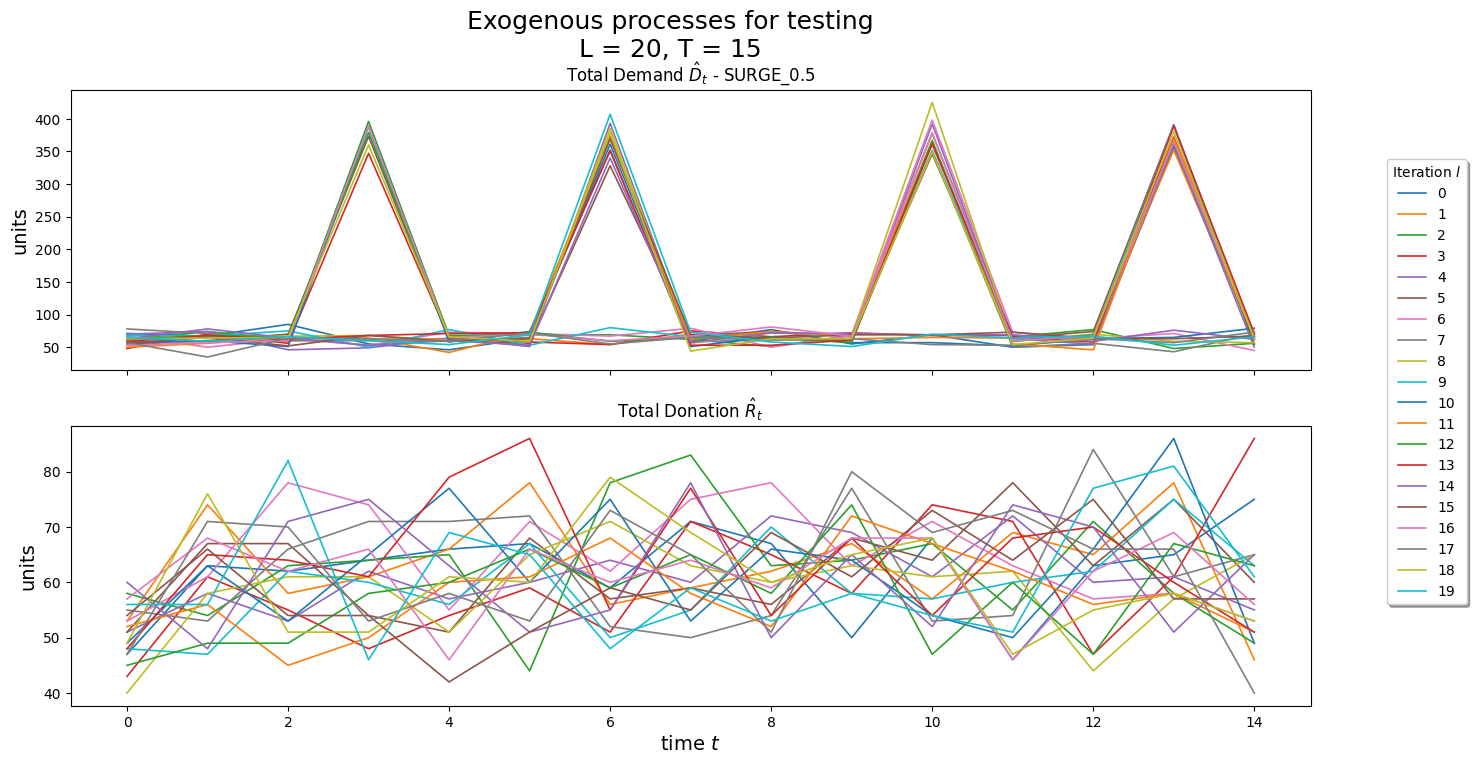
The simulation allows for applying a PARS['SURGE_FACTOR'] with probability PARS['SURGE_PROB'] at specified points in a sample path, PARS['TIME_PERIODS_SURGE']
The problem of managing blood inventories serves as a particularly elegant illustration of a resource allocation problem. We are going to start by assuming that we are managing inventories at a single ospital, where each week we have to decide which of our blood inventories should be used for the demands that need to be served in the upcoming week.
We have to start with a bit of background about blood. For the purposes of managing blood inventories, we care primarily about blood type and age. Although there is a vast range of differences in the blood of two individuals, for most purposes doctors focus on the eight major blood types: A+ (“A positive”), A- (“A negative”), B+, B-, AB+, AB-, O+, and O-. While the ability to substitute different blood types can depend on the nature of the operation, for most purposes blood can be substituted according to table 14.1:
Blood substition
A second important characteristic of blood is its age. The storage of blood is limited to six weeks, after which it has to be discarded. Hospitals need to anticipate if they think they can use blood before it hits this limit, as it can be transferred to blood centers which monitor inventories at different hospitals within a region. It helps if a hospital can identify blood it will not need as soon as possible so that the blood can be transferred to locations that are running short.
One mechanism for extending the shelflife of blood is to freeze it. Frozen blood can be stored up to 10 years, but it takes at least an hour to thaw, limiting its use in emergency situations or operations where the amount of blood needed is highly uncertain. In addition, once frozen blood is thawed it must be used within 24 hours.
4.2 Core Elements
This section attempts to answer three important questions: - What metrics are we going to track? - What decisions do we intend to make? - What are the sources of uncertainty?
For this problem, the only metric we are interested in is the total contribution we make after each decision window. We do not have costs in this problem to assign blood of one type to demand of another type. In other words, we do not, for example, spend money to encourage additional donations. Neither do we include transportation costs when moving inventories from one hospital to another. Instead, we use the contribution function to capture the procedures and preferences of the doctor. For example, we would like to capture the preference that it is better in general not to substitute. Also, to satisfy an urgent demand is more important than to satisfy an elective demand.
We have a separate decision (which will become a decision variable) for each link from a resource vector \(a\) to a demand vector \(b\). Each of these decisions represents an assignment or allocation of an amount of resource away from the inventory for the specific resource with attributes \(a\), to a demand with attributes \(b\).
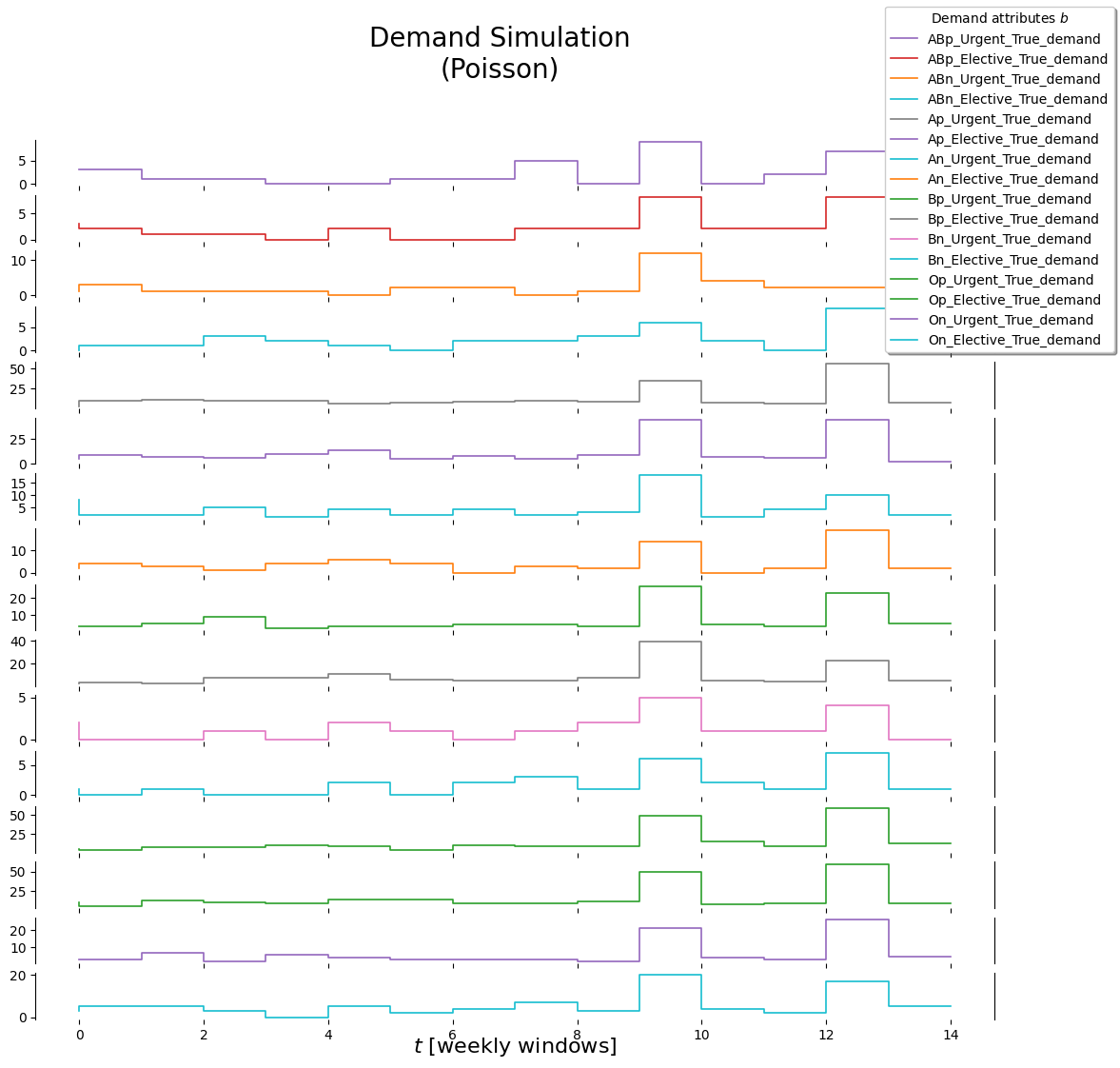
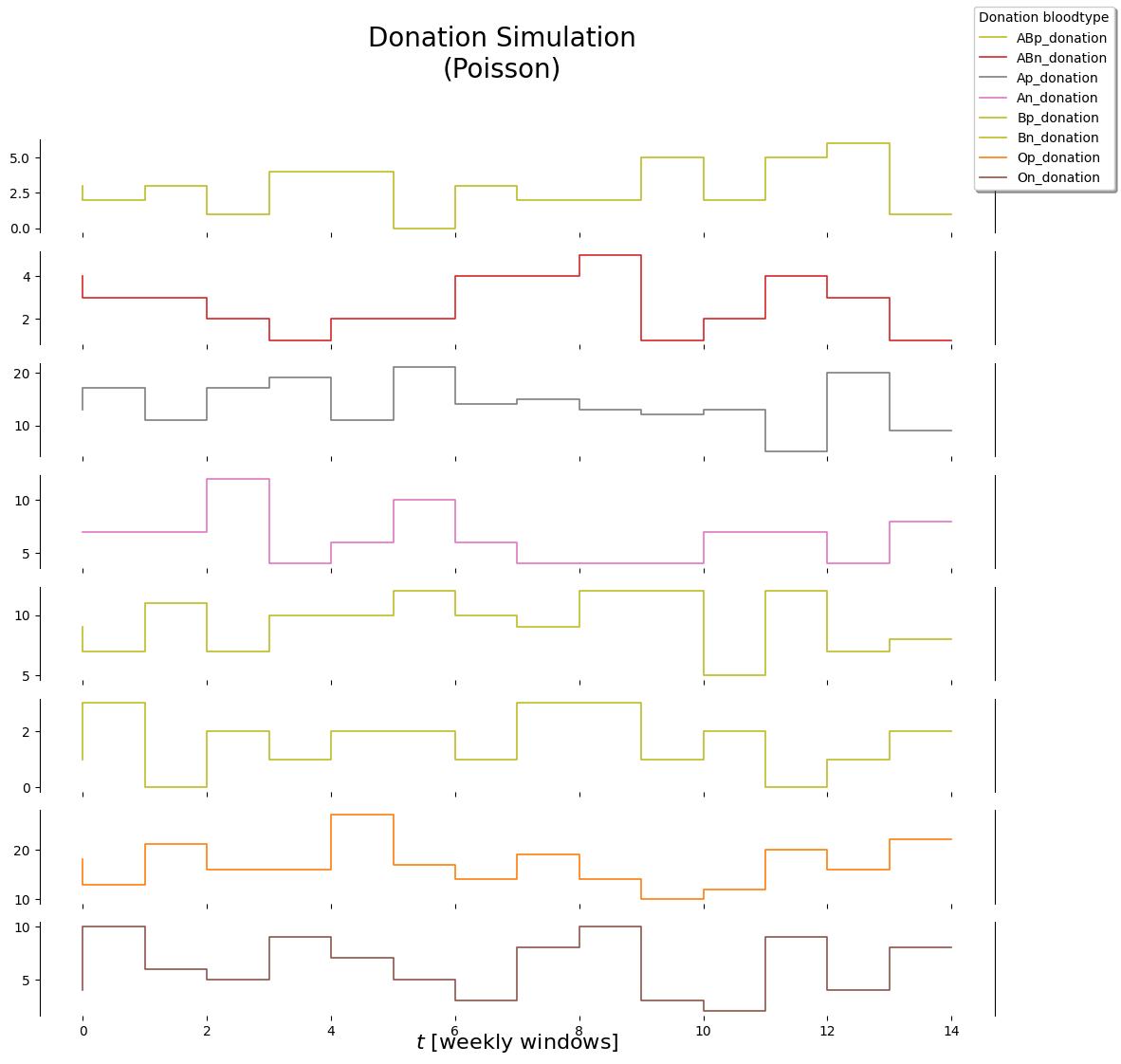
Two sources of uncertainty are included in this model. Firstly, the demand for blood of a specific bloodtype is uncertain.Then we also do not know the amount of blood units that will be donated for each bloodtype.
4.3 Mathematical Model | SUM Design
A Python class is used to implement the model for the SUM (System Under Management):
class Model():
def __init__(self, S_0_info):
...
...
4.3.1 State variables
The state variables represent what we need to know. - \(R_t = (R_{ta})_{a \in \cal A}\) where \(\cal{A} = \{(a_1,a_2):a_1 \in \{ \mathrm{AB+,AB-A+,A-,B+,B-,O+,O-}\}, a_2 \in \{ \mathrm{0,1,2} \} \}\) - the inventory on hand at time \(t\) of the resource with attribute \(a\) before we make a new allocation decision, and before we have satisfied any demands arising in time interval \(t\) - measured in inventory units - \(R^{hold}_t = (R^{hold}_{ta})_{a \in \cal A}\) where \(\cal{A} = \{(a_1,a_2):a_1 \in \{ \mathrm{AB+,AB-A+,A-,B+,B-,O+,O-}\}, a_2 \in \{ \mathrm{0,1,2} \} \}\) - the inventory held (not assigned) at time \(t\) of the resource with attribute \(a\) before we make a new allocation decision, and before we have satisfied any demands arising in time interval \(t\) - measured in inventory units
- \(\hat{D}_t = (\hat{D}_{tb})_{b \in \cal B}\) where \(\cal{B} = \{(b_1,b_2,b_2):b_1 \in \{ \mathrm{AB+,AB-,A+,A-,B+,B-,O+,O-}\}, b_2 \in \{ \mathrm{Urgent,Elective}, b_3 \in \{ \mathrm{SubstitutionAllowed?} \} \}\) - the demand at time \(t\) with attribute \(b\) - measured in inventory units - \(\hat{R}_t = (\hat{R}_{ta})_{a \in \cal A}\) where \(\cal{A} = \{(a_1,a_2):a_1 \in \{ \mathrm{AB+,AB-A+,A-,B+,B-,O+,O-}\}, a_2 \in \{ \mathrm{0,1,2} \} \}\) - the donations at time \(t\) of the resource with attribute \(a\) before we make a new allocation decision, and before we have satisfied any demands arising in time interval \(t\) - measured in inventory units
We have a decision variable for each link from a resource with attributes \(a\) to a demand with attributes \(b\). Each of these decisions represents an assignment or allocation of an amount of resource away from the inventory for the specific resource with attributes \(a\), to a demand with attributes \(b\).
\(x_t = (x_{tab})_{a\in \cal A,b\in \cal B}\) where
The exogenous information variables represent what we did not know (when we made a decision). These are the variables that we cannot control directly. The information in these variables become available after we make the decision \(x_{tab}\).
We include random variations in demand as well as resource levels due to blood donations. This is modeled as:
The latest exogenous information can be accessed by calling the W_fn(self, t) method from class Model().
4.3.4 Transition function
The transition function describes how the state variables evolve over time. Because we currently have two state variables in the state, \(S_t=(R_t,D_t)\), we have the equations:
where \(R^x_t\) is the post-decision resource vector. The matrix \(\Delta R_t\) consists of elements \(\delta_{a'}(a,b)\) where this element is in row \(a'\) and column \((a,b)\). The elements are given by:
The contribution (reward) function is implemented by the C_fn() method in class Model.
4.3.6 Implementation of SUM Model
Here is the complete implementation of the Model class:
class Model():def__init__(self, S_0_info):self.S_0_info = S_0_infoself.State = namedtuple('State', SNAMES) #. 'class'self.S_t =self.build_state(S_0_info) #. 'instance'self.Decision = namedtuple('Decision', xNAMES) #. 'class'self.cumC =0.0self.supersink = ('supersink', np.inf)self.parallelarr = {}self.varr = {}self.sqGrad = {} #store the sum of the squared gradients when using AdaGrad stepsizes# add parallel edges from hold nodes to supersinkfor t in PARS['Times']:for hld in aNAMES: parArr = np.zeros(PARS['NUM_PARALLEL_LINKS']) vArr = np.zeros(PARS['NUM_PARALLEL_LINKS'])self.parallelarr[(t, hld, self.supersink)] = parArrself.varr[(t, hld, self.supersink)] = vArr sqGradArr = np.zeros(PARS['NUM_PARALLEL_LINKS'])self.sqGrad[(t, hld)] = sqGradArrdef build_state(self, info):returnself.State(*[info[sn] for sn in SNAMES])def build_decision(self, info):returnself.Decision(*[info[xn] for xn in xNAMES])# exogenous information = demand from t-1 to t and new donated blooddef W_fn(self, t):if (PARS['SAMPLING_DIST'] =='P'): Dh_tt1 = dem_sim.simulate_pois(t) Rh_tt1 = don_sim.simulate_pois()else: Dh_tt1 = dem_sim.simulate_unif(t) Rh_tt1 = don_sim.simulate_unif()self.S_t.Dh_t.update(Dh_tt1)# update the demand nodes values =list(self.S_t.Dh_t.values())for i,itm inenumerate(self.S_t.Dh_t.items()):self.S_t.Dh_t[itm[0]] = values[i]# save the donation vector to the modelself.S_t.Rh_t.update(Rh_tt1)return Dh_tt1, Rh_tt1def S__M_fn(self, x_t, hld):# iterate through hold vector hold = hldfor i,itm inenumerate(self.S_t.Rhold_t.items()):self.S_t.Rhold_t[itm[0]] = hold[i] values =list(self.S_t.Rh_t.values()) rev_don =list(reversed(values)) values =list(self.S_t.Rhold_t.values()) myrev_hld =list(reversed(values))# age the blood at hold node and add in the donationsfor i inrange(PARS['NUM_BLD_NODES']):if (i % PARS['MAX_AGE'] == PARS['MAX_AGE']-1):# add donation myrev_hld[i] = rev_don[i // PARS['MAX_AGE']]else:# age myrev_hld[i] = myrev_hld[i+1] myrev_hld =list(reversed(myrev_hld))# amount at blood node = amount at hold nodefor i,itm inenumerate(self.S_t.R_t.items()):self.S_t.R_t[itm[0]] = myrev_hld[i]returnself.S_tdef C_fn(self, x_t): x = [x_t.x_t[abn] for abn in abNAMES_EXP] C = np.dot(x, P.coeff)return Cdef step(self, x_t, hld): C =self.C_fn(x_t)self.cumC += Cself.S_t =self.S__M_fn(x_t, hld)return (self.S_t, self.cumC, x_t) #. for plotting########################################################################################################class Exog_Info():def__init__(self, demand, donation):# list consisting of blood demand objectsself.demand = demand# list consisting of blood unit objects donated to the blood inventoryself.donation = donationdef init_R_t_unif(): bldinv_init = {}for aName in aNAMES:if aName.split('_')[1]=='0': bldinv_init[aName] =round(np.random.uniform(0, myMAX_DON_BY_BLOOD[aName.split('_')[0]])*.9)else: bldinv_init[aName] =round(np.random.uniform(0, myMAX_DON_BY_BLOOD[aName.split('_')[0]])*(0.1/(PARS['MAX_AGE'] -1)))return bldinv_initdef init_R_t_pois(): bldinv_init = {}for aName in aNAMES:if aName.split('_')[1]=='0': bldinv_init[aName] =int(np.random.poisson(myMAX_DON_BY_BLOOD[aName.split('_')[0]])*.9)else: bldinv_init[aName] =int(np.random.poisson(myMAX_DON_BY_BLOOD[aName.split('_')[0]])*(0.1/(PARS['MAX_AGE']-1)))return bldinv_init
4.4 Uncertainty Model
We will simulate the demand and blood donations as described in section 4.3.3:
There are two main meta-classes of policy design. Each of these has two subclasses: - Policy Search - Policy Function Approximations (PFAs) - Cost Function Approximations (CFAs) - Lookahead - Value Function Approximations (VFAs) - Direct Lookaheads (DLAs)
In this project we will only use one approach: - A technique that exploits the convexity (concavity in our case because we maximize) of the problem in the form of a linear program (LP) (from the VFA class)
The LP policy is implemented by the X__LP() method in class Policy().
4.5.1 Implementation of Policy Design
The Policy() class implements the policy design. The Python package cvxopt is used to perform the solution of the linear program at each step. Here are some links:
********************Started Main*****************
Starting testing iterations! Currently at iteration 0
Reseting random seed!
Iteration = 0
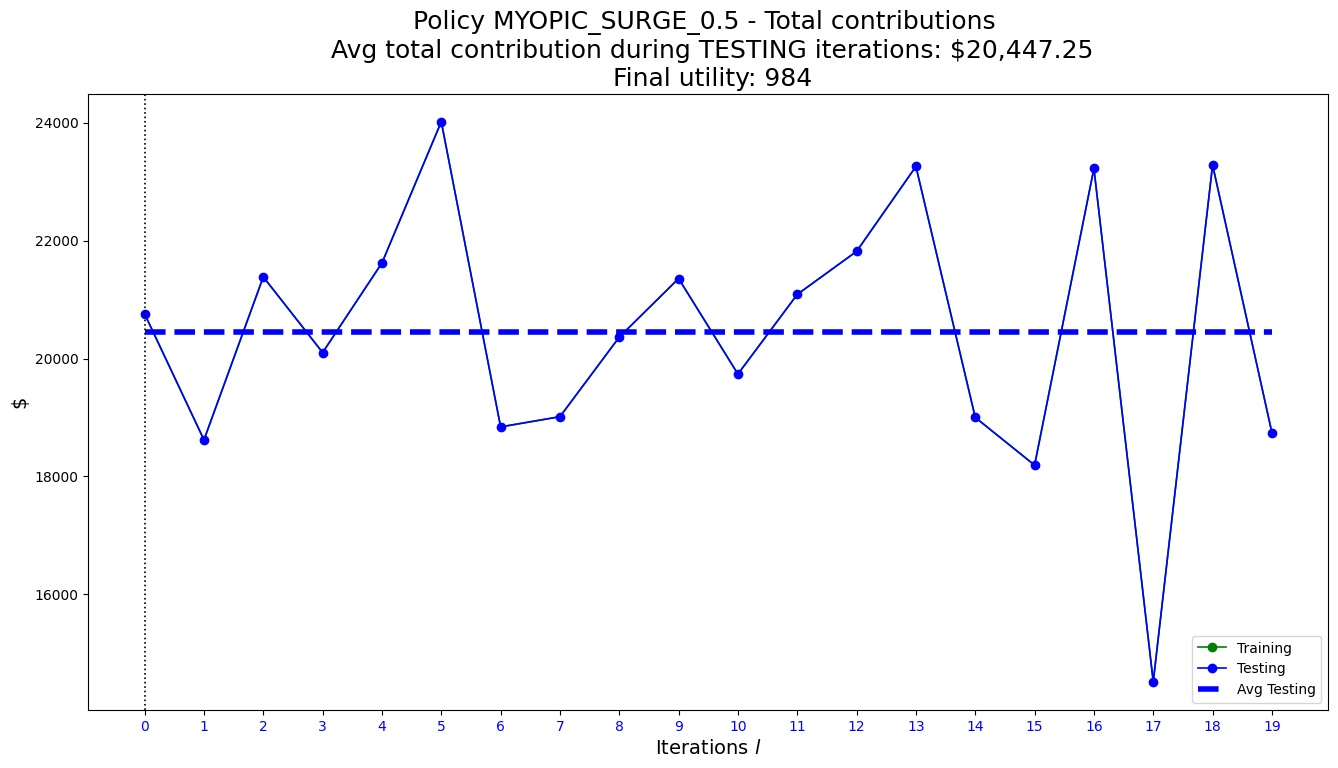
***Finishing iteration 0 in 1.00 secs. Total contribution: 20757.00***
Iteration = 1
***Finishing iteration 1 in 1.00 secs. Total contribution: 18621.00***
Iteration = 2
***Finishing iteration 2 in 1.00 secs. Total contribution: 21385.00***
Iteration = 3
***Finishing iteration 3 in 0.00 secs. Total contribution: 20102.00***
Iteration = 4
***Finishing iteration 4 in 0.00 secs. Total contribution: 21622.00***
Iteration = 5
***Finishing iteration 5 in 0.00 secs. Total contribution: 24017.00***
Iteration = 6
***Finishing iteration 6 in 0.00 secs. Total contribution: 18841.00***
Iteration = 7
***Finishing iteration 7 in 0.00 secs. Total contribution: 19014.00***
Iteration = 8
***Finishing iteration 8 in 0.00 secs. Total contribution: 20364.00***
Iteration = 9
***Finishing iteration 9 in 0.00 secs. Total contribution: 21357.00***
Iteration = 10
***Finishing iteration 10 in 0.00 secs. Total contribution: 19737.00***
Iteration = 11
***Finishing iteration 11 in 0.00 secs. Total contribution: 21088.00***
Iteration = 12
***Finishing iteration 12 in 0.00 secs. Total contribution: 21818.00***
Iteration = 13
***Finishing iteration 13 in 0.00 secs. Total contribution: 23258.00***
Iteration = 14
***Finishing iteration 14 in 0.00 secs. Total contribution: 19001.00***
Iteration = 15
***Finishing iteration 15 in 1.00 secs. Total contribution: 18192.00***
Iteration = 16
***Finishing iteration 16 in 1.00 secs. Total contribution: 23225.00***
Iteration = 17
***Finishing iteration 17 in 1.00 secs. Total contribution: 14519.00***
Iteration = 18
***Finishing iteration 18 in 0.00 secs. Total contribution: 23284.00***
Iteration = 19
***Finishing iteration 19 in 0.00 secs. Total contribution: 18743.00***
Total elapsed time 15.26 secs
CPU times: user 12.2 s, sys: 8.48 s, total: 20.7 s
Wall time: 15.3 s
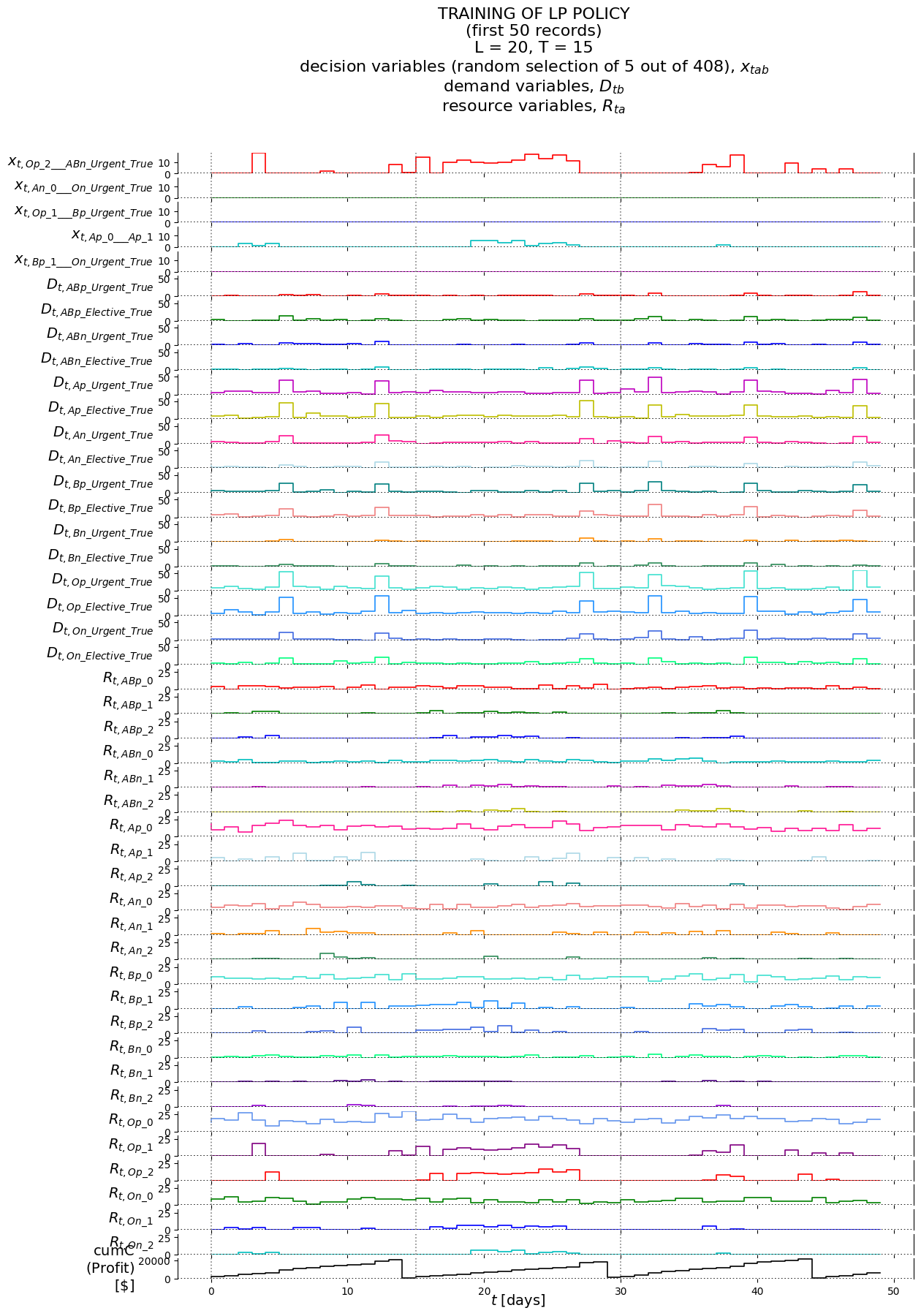
R_t_labels = ['R_t_'+an for an in aNAMES]D_t_labels = ['D_t_'+bn for bn in bNAMES]x_t_labels = ['x_t_'+abn for abn in abNAMES_EXP]labels = ['piName', 'l'] +\ ['t'] + R_t_labels + D_t_labels + ['cumC'] + x_t_labels# labels
def run_policy_evalu(piName_evalu, T_evalu, model): record = []for t inrange(T_evalu): x_t, x =getattr(P_evalu, piName_evalu)(model) hld = [np.sum(x[i*(PARS['NUM_DEM_NODES']+PARS['NUM_PARALLEL_LINKS'])+PARS['NUM_DEM_NODES']:(i+1)*(PARS['NUM_DEM_NODES']+PARS['NUM_PARALLEL_LINKS'])]) for i inlist(range(PARS['NUM_BLD_NODES']))]# solHoldRecord = (l, t, hld.copy())# solHoldList.append(solHoldRecord) hld = np.array(hld) S_t, cumC, x_t = model.step(x_t, hld) # step the model forward one iteration record_t = [t] +\ [S_t.R_t[an] for an in aNAMES] +\ [S_t.Dh_t[bn] for bn in bNAMES] +\ [cumC] +\ [x_t.x_t[abn] for abn in abNAMES_EXP] record.append(record_t) cumC = model.cumCreturn cumC, record
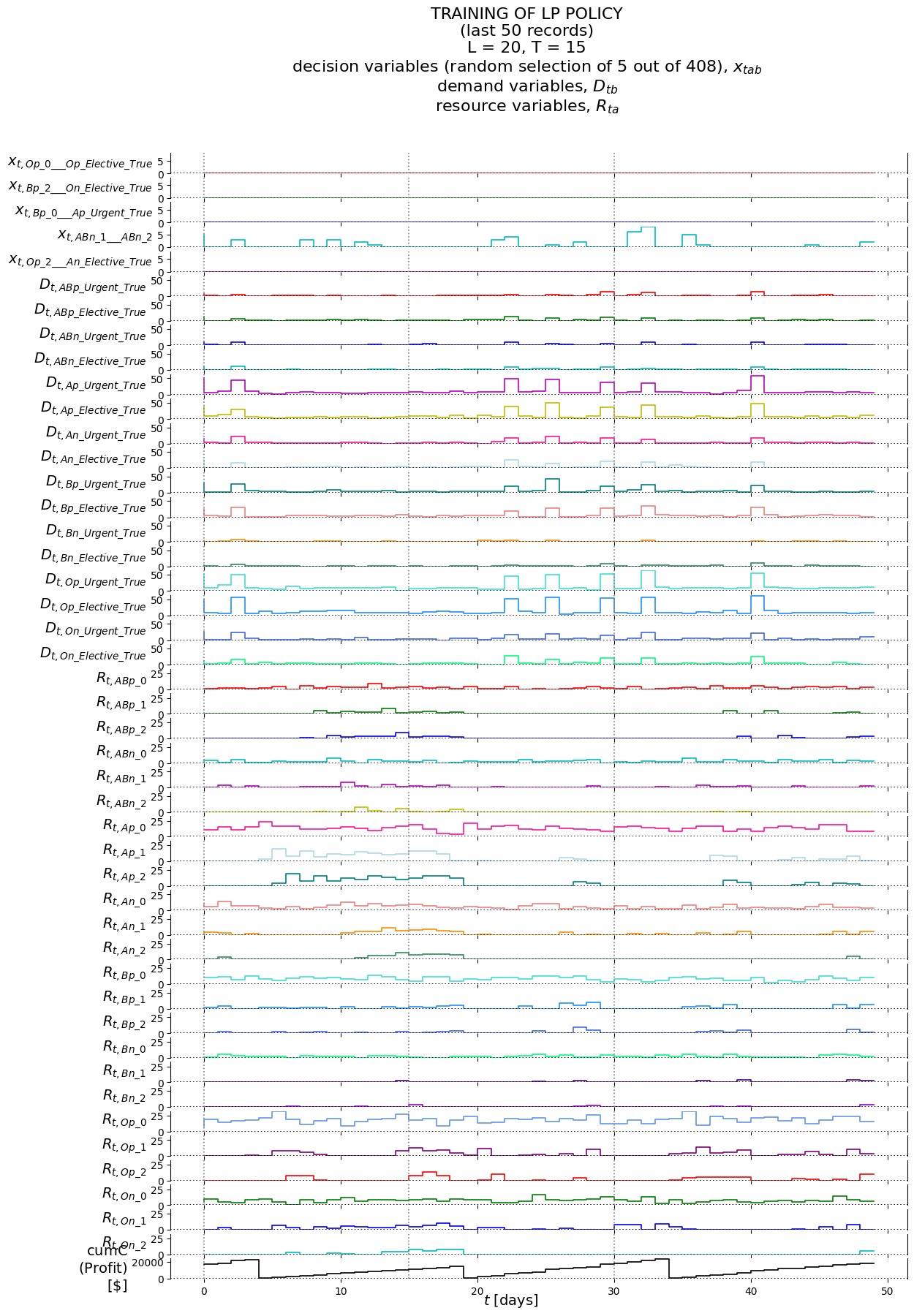
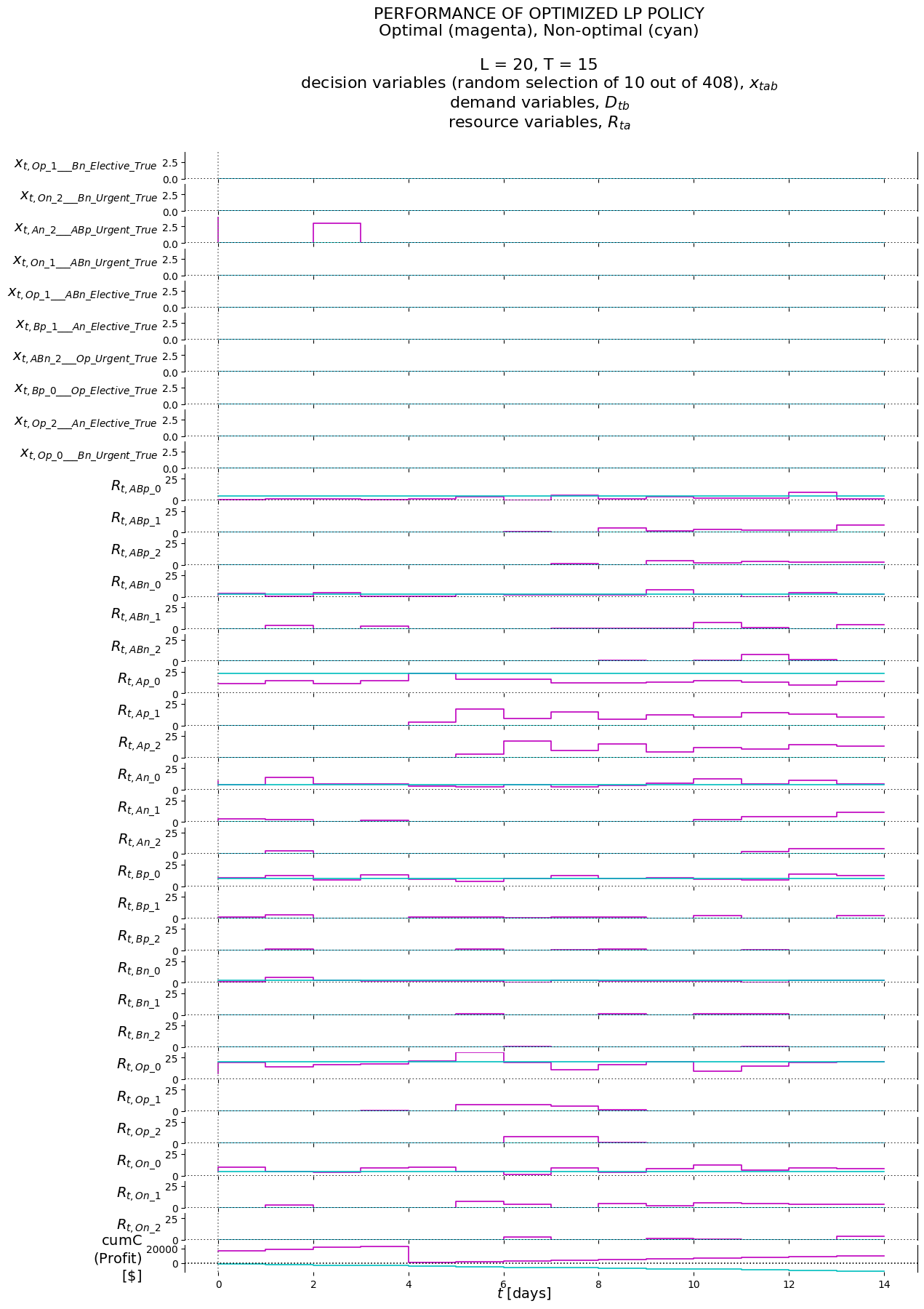
From the cumC plot we see that the cumulative reward for the optimal policy X__LP keeps on rising. The non-optimal policy X__FillAsNeededFromSingleResource keeps losing money.
# def initOutputListHeaders(params):def initOutputListHeaders(): labelsDemandExo=['l','t','Bloodtype','Urgency','isSubAllowed','DemandValue'] labelsDonationExo=['l','t','Bloodtype','DonationValue'] labelsSupplyPre=['l','t','BloodType','Age','PreInv'] labelsSupplyPost=['l','t','BloodType','Age','PostInv'] labelsSlopesList=['l','t','BloodType','Age'] vNames = ["v_"+str(r) for r inlist(range(PARS['NUM_PARALLEL_LINKS']))] labelsSlopesList = labelsSlopesList + vNames headerSolDemList =['l','t','BloodTypeS','Age','BloodTypeD','Urgency','SubsAllowed','isCompatible','Contrib','Value'] headerSolHoldList = ['l','t','BloodTypeS','Age','Value']# headerSimuList = ['Iteration','ElapsedTime','Stepsize','ObjVal','isTrainning'] headerSimuList = ['l','ElapsedTime','Stepsize','cumC','isTrainning'] headerUpdateVfaList = ['l','t','BloodType','Age','R','vhat','vbarOld','sqGrad','stepsize','vbarNew']return(labelsDemandExo, labelsDonationExo,labelsSupplyPre,labelsSupplyPost,labelsSlopesList,headerSolDemList,headerSolHoldList,headerSimuList,headerUpdateVfaList)def convertToDfOutputLists(# params, demandExoList, donationExoList, supplyPreList, supplyPostList, slopesList, solDemList, solHoldList, simuList, updateVfaList): labelsDemandExo, labelsDonationExo, \ labelsSupplyPre, labelsSupplyPost, \ labelsSlopesList, headerSolDemList, headerSolHoldList, \ headerSimuList, headerUpdateVfaList = initOutputListHeaders()#Flatteting the lists dfSimu = pd.DataFrame.from_records(simuList, columns=headerSimuList) demandExoListFlat = [ \ (ite,t,dnode.split('_')[0],dnode.split('_')[1],dnode.split('_')[2],dvalue)for ite,t,d in demandExoList for dnode,dvalue inzip(bNAMES, d)] dfDemandExo = pd.DataFrame.from_records(demandExoListFlat, columns=labelsDemandExo) donationExoListFlat = [ \ (ite,t,dtype,dvalue)for ite,t,d in donationExoList for dtype,dvalue inzip(myBloodtypes, d)] dfDonationExo = pd.DataFrame.from_records(donationExoListFlat, columns=labelsDonationExo) supplyPreListFlat = [ \ (ite,t,bnode.split('_')[0],bnode.split('_')[1],bvalue)for ite,t,b in supplyPreList for bnode,bvalue inzip(aNAMES, b)] dfSupplyPre = pd.DataFrame.from_records(supplyPreListFlat, columns=labelsSupplyPre) supplyPostListFlat = [ \ (ite,t,bnode.split('_')[0],bnode.split('_')[1],bvalue)for ite,t,b in supplyPostList for bnode,bvalue inzip(aNAMES, b)] dfSupplyPost = pd.DataFrame.from_records(supplyPostListFlat,columns=labelsSupplyPost) solDemListFlat = [ \ (ite, t, bld.split('_')[0], bld.split('_')[1], dem.split('_')[0], dem.split('_')[1], dem.split('_')[2], mySubMatrix['_'.join((bld.split('_')[0], dem.split('_')[0]))], mySubMatrix['_'.join((bld.split('_')[0], dem.split('_')[0]))], #.seems to play same role as demweights xbd)for ite,t,xDem in solDemListfor bld,xb inzip(aNAMES,xDem)for dem,xbd inzip(bNAMES,xb)] dfSolDem = pd.DataFrame.from_records(solDemListFlat,columns=headerSolDemList) solHoldListFlat = [ \ (ite,t,bnode.split('_')[0],bnode.split('_')[1],hvalue)for ite,t,h in solHoldListfor bnode,hvalue inzip(aNAMES,h)] dfSolHold = pd.DataFrame.from_records(solHoldListFlat,columns=headerSolHoldList) slopesListFlat = [ \ (vnode.split('_')[0],vnode.split('_')[1],bnode.split('_')[0],bnode.split('_')[1],*list(vnode.split('_')[2]))for vnode,bnode inzip(slopesList,aNAMES*PARS['NUM_ITER']*PARS['MAX_TIME'])] dfSlopes = pd.DataFrame.from_records(slopesListFlat,columns=labelsSlopesList) dfUpdateVfa = pd.DataFrame.from_records(updateVfaList,columns=headerUpdateVfaList)return\ dfDemandExo, dfDonationExo, \ dfSupplyPre, dfSupplyPost, \ dfSlopes, dfSolDem, dfSolHold, \ dfSimu, dfUpdateVfa# def printDfsToOutputFile(params,dfDemandExo, dfDonationExo, dfSupplyPre, dfSupplyPost, dfSlopes, dfSolDem, dfSolHold, dfSimu, dfUpdateVfa):def printDfsToOutputFile(dfDemandExo, dfDonationExo, dfSupplyPre, dfSupplyPost, dfSlopes, dfSolDem, dfSolHold, dfSimu, dfUpdateVfa): t_init_print = time.time()print("Started printing file")# print to excel file# Create a Pandas Excel writer using XlsxWriter as the engine. writer = pd.ExcelWriter(PARS['OUTPUT_FILENAME'], engine='xlsxwriter')# Convert the dataframe to an XlsxWriter Excel object. dfSimu.to_excel(writer, sheet_name='Simu')if PARS['PRINT_ALL']: dfDemandExo.to_excel(writer, sheet_name='DemandExo') dfDonationExo.to_excel(writer, sheet_name='DonationExo') dfSupplyPre.to_excel(writer, sheet_name='SupplyPre') dfSolDem.to_excel(writer, sheet_name='SolDem') dfSolHold.to_excel(writer, sheet_name='HoldDem') dfSupplyPost.to_excel(writer, sheet_name='SupplyPost') dfSlopes.to_excel(writer, sheet_name='SlopesList') dfUpdateVfa.to_excel(writer, sheet_name='UpdatesVfa')# Close the Pandas Excel writer and output the Excel file. writer.save()print("Finished printing files in {:.2f} secs".format(time.time()-t_init_print))
UserWarning: You have mixed positional and keyword arguments, some input may be discarded.
fig_inv.legend(
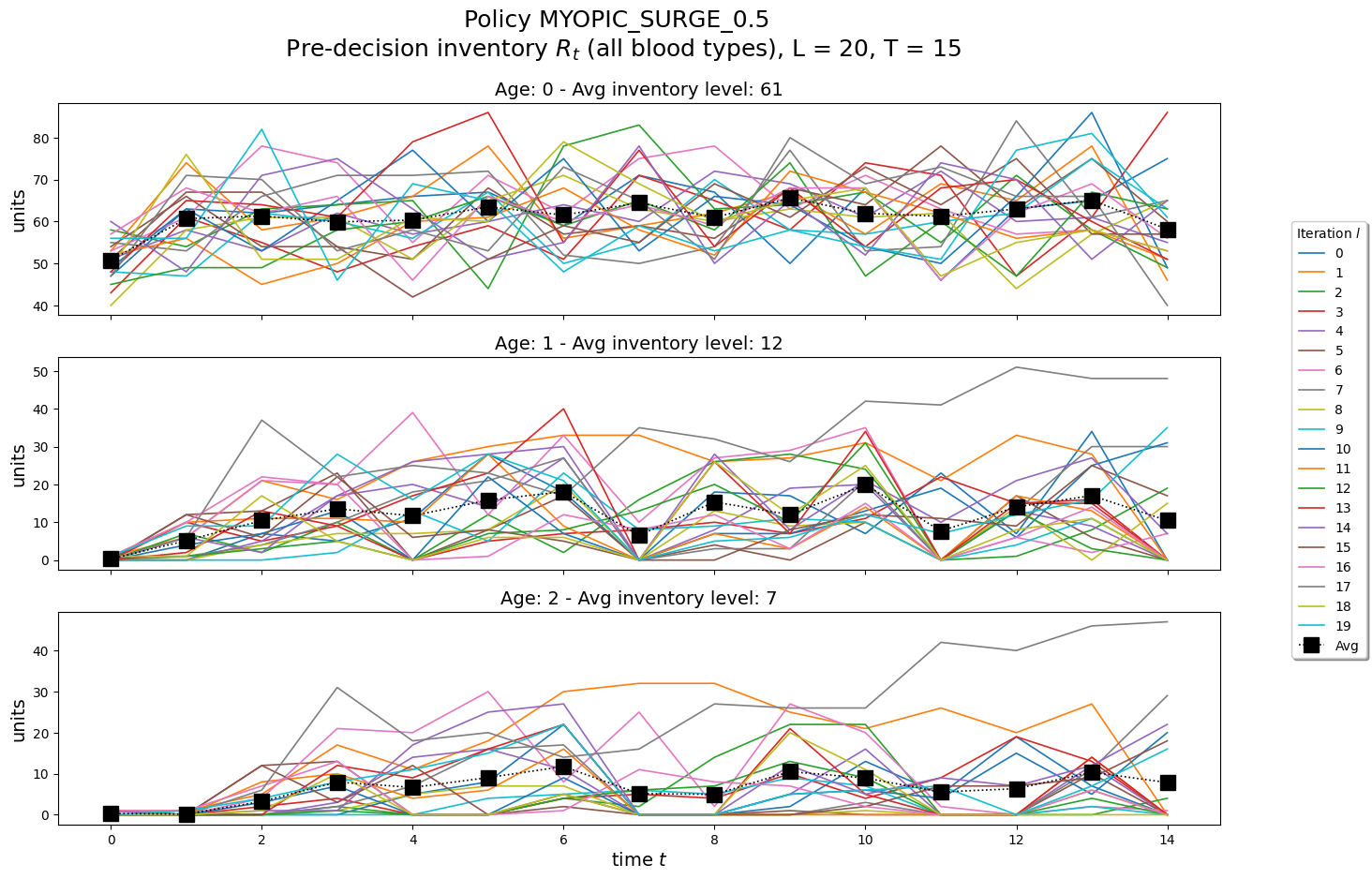
P.plot_predecision_inventory_by_bloodtype(dfInv)
UserWarning: You have mixed positional and keyword arguments, some input may be discarded.
fig_inv_blood.legend(
P.plot_predecision_inventory(dfInv)
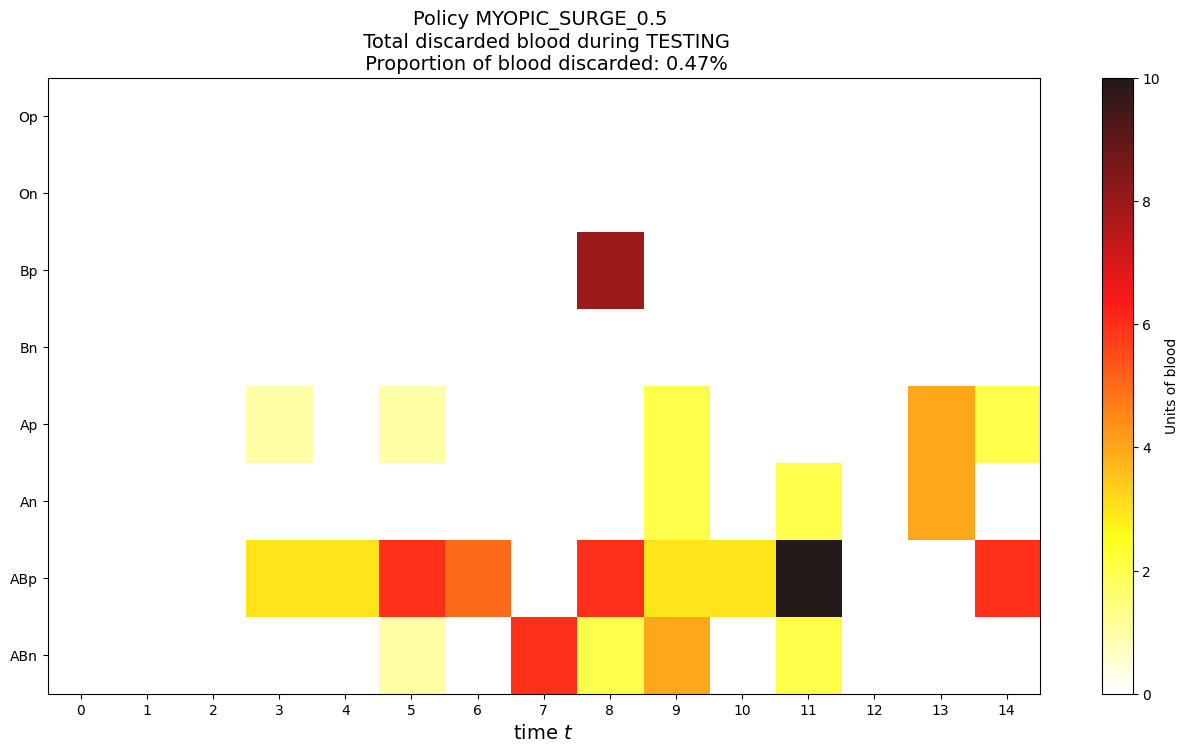
P.plot_discarded_blood_during_testing(dfSolHold)
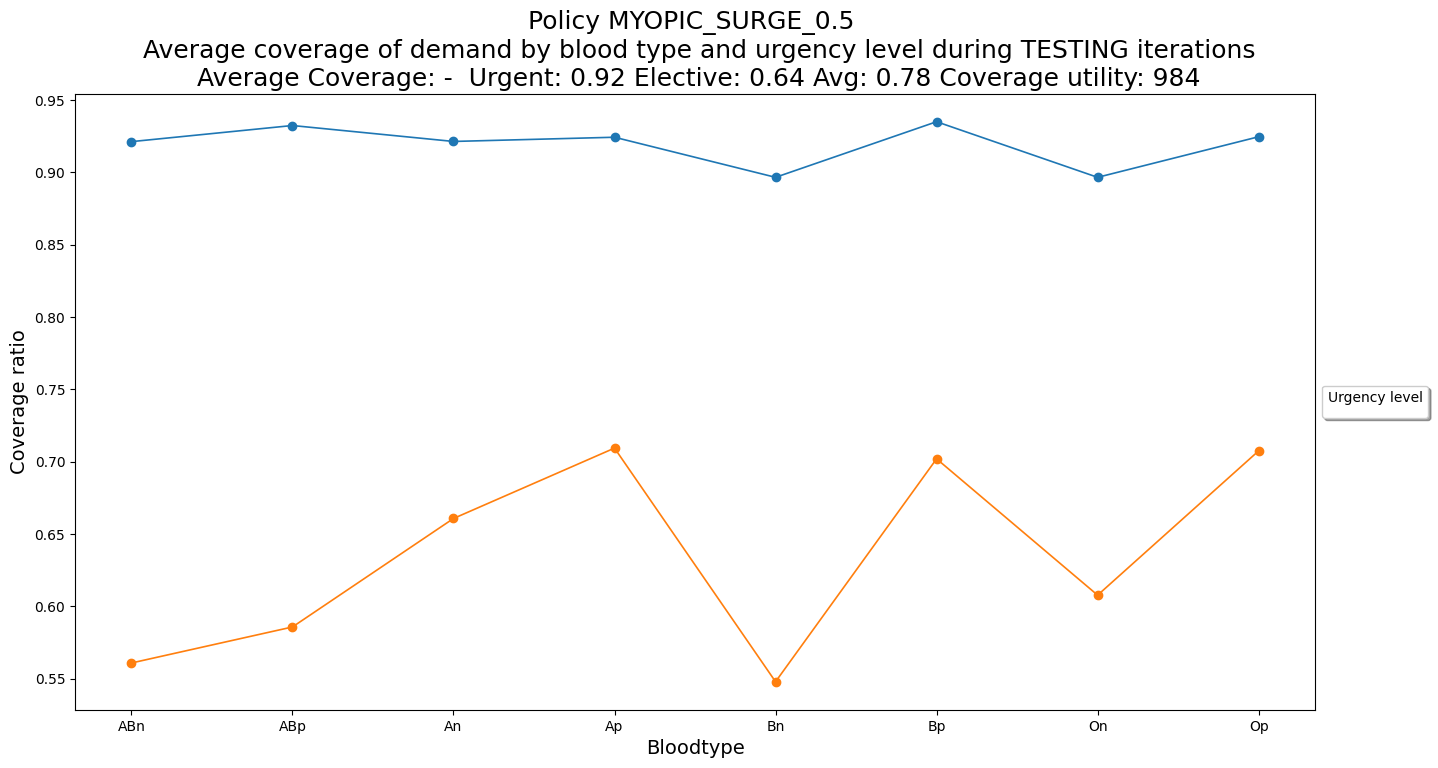
P.plot_demand_coverage(dfPrintIte)
WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
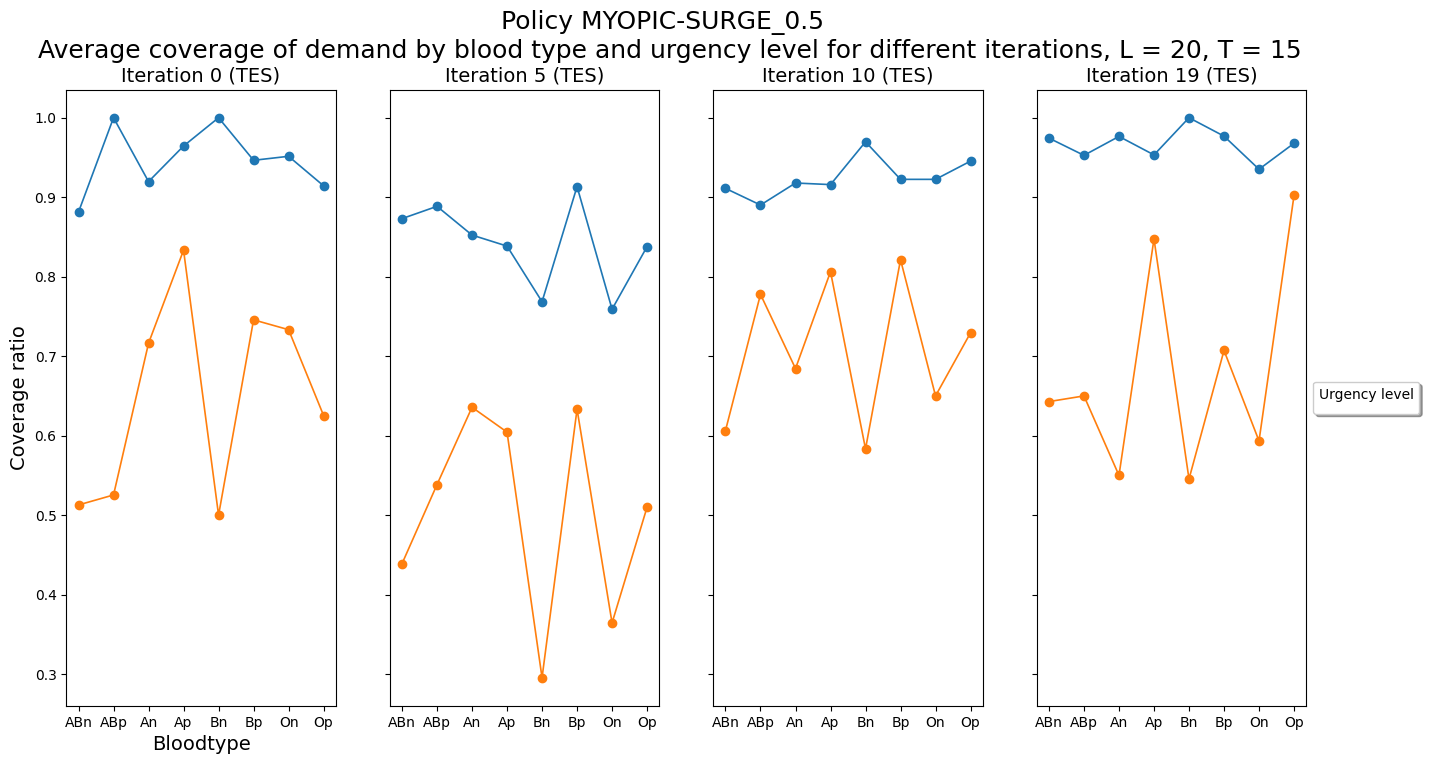
P.plot_demand_coverage_by_timeperiod(dfCoverage)
WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
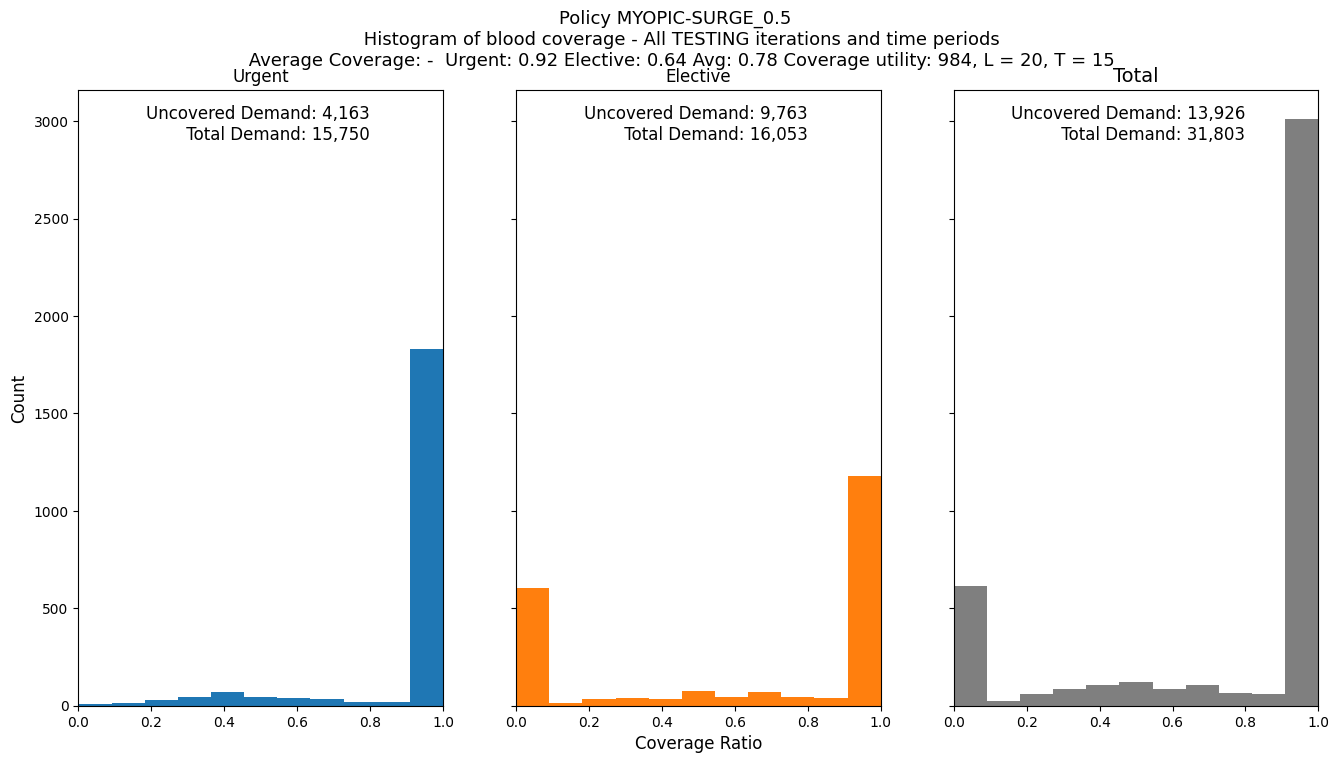
P.plot_demand_coverage_histogram(dfCoverage)
# if params['SAVE_PLOTS']:# fig_ite.savefig('{}_Figure1.pdf'.format(instance))# fig_exo.savefig('{}_Figure2.pdf'.format(instance))# fig_inv.savefig('{}_Figure3.pdf'.format(instance))# fig_inv_blood.savefig('{}_Figure4.pdf'.format(instance))# fig_inv_total.savefig('{}_Figure5.pdf'.format(instance))# fig_dis.savefig('{}_Figure6.pdf'.format(instance))# fig_tes.savefig('{}_Figure7.pdf'.format(instance))# fig_cover.savefig('{}_Figure8.pdf'.format(instance))# fig_cover_ite.savefig('{}_Figure9.pdf'.format(instance))# fig_hist.savefig('{}_Figure10.pdf'.format(instance))# if params['SHOW_PLOTS']:# plt.show()############################################################################################################################################Printing the final resultsprint("\n*******************************************************************************************")print("Policy {}_{}".format(policy,surge))print(instance)print("Average total contribution during TESTING iterations: ${:,}".format(meanTesting))print(coverage)print("Proportion of blood discarded: {:.2f}% ".format(totalDiscarded*100/totalDonation))print("Final utility: {:.0f}".format(modifiedUtil))print("*********************************************************************************************\n")withopen("OutputAll.txt", "a") as myfile:print("{}\t{:.2f}\t{:.2f}\t{:.2f}\t{:.2f}\t{:.2f}\t{:.2f}".format(instance,meanTesting,finalCoverage['Urgent'],finalCoverage['Elective'],dfCoverage_agg_ite['Ratio'].mean(),totalDiscarded/totalDonation,modifiedUtil),file=myfile)############################################################################################################################################ print("Total elapsed time {:.2f} secs".format(time.time()- t_global_init)) #.moved to perform_search_sample_paths()############################################################################################################################################Printing output fileif PARS['PRINT']: printDfsToOutputFile(PARS,dfDemandExo, dfDonationExo, dfSupplyPre, dfSupplyPost, dfSlopes, dfSolDem, dfSolHold, dfCoverage, dfUpdateVfa)############################################################################################################################################End Main###############################################################################################################################################
*******************************************************************************************
Policy MYOPIC_SURGE_0.5
PolicyMYOPIC_SURGE_0.5_PEN_-9.0_ALPHA_0.00
Average total contribution during TESTING iterations: $20,447.25
Average Coverage: - Urgent: 0.92 Elective: 0.64 Avg: 0.78
Proportion of blood discarded: 0.47%
Final utility: 984
*********************************************************************************************